Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
BBY 156 Bilgi Erişim 2012-2013 http://bby156. blogspot
BBY 156 Bilgi Erişim Internet ve bilgi erişim: Web arama motorları İrem Soydal ~ Yurdagül Ünal

2
Web’de arama ile ilgili zorluklar -Veri-
Dağıtık veri Geçici veri/Tazelik “Freshness” (“40% of the web changes every month”) Üssel büyüme Yapısal olmayan ve tekrarlanan (gereksiz) veri (“30% of web pages are near duplicates”) Düzenlenmemiş/gözden geçirilmemiş veri Çoklu biçim (multiple formats) Ticari önyargılar Saklı veri
 Üssel büyüme. Yapısal olmayan ve tekrarlanan (gereksiz) veri ( 30% of web pages are near duplicates ) Düzenlenmemiş/gözden geçirilmemiş veri. Çoklu biçim (multiple formats) Ticari önyargılar. Saklı veri.")
3
Web’de arama ile ilgili zorluklar -Kullanıcı-
Arama motorlarının arayüzüne aşina olmayan kullanıcılar (Örneğin, acaba “gezi parkı” sorgusu tüm arama motorlarında aynı anlama mı gelir?) Verinin mantıksal görünüşüne aşina olmayan kullanıcılar (Örneğin, acaba “Portakal” şeklinde yapılan bir sorgu ile “portakal” şeklinde yapılan sorgu aynı şey midir?) Farklı bilgi ihtiyacı olan ve farklı arama davranışları sergileyen kullanıcılar
 Verinin mantıksal görünüşüne aşina olmayan kullanıcılar (Örneğin, acaba Portakal şeklinde yapılan bir sorgu ile portakal şeklinde yapılan sorgu aynı şey midir ) Farklı bilgi ihtiyacı olan ve farklı arama davranışları sergileyen kullanıcılar.")
4
Arama motorları ve geleneksel bilgi erişim sistemleri arasındaki farklar
Bilgi erişim sistemlerinde dizinlenecek belgeler durağandır (statik). Başka bir deyişle, bir belge bir defa dizinlendikten sonra bir daha dizinleme işlemine tabi tutulmaz. Arama motorlarının mimarisi ise bilgi erişim sistemlerininkine göre farklı, çünkü çok daha dinamik bir yapı var. “Web kaynakları tahmini olarak ortalama 75 gün değişmeden kalmaktadırlar.” (Brake, 2001) “Web kaynaklarının %40’ı her ay değişiyor.” (Kahle, 1996) “Internet ortamındaki bir bağlantının (link) ortalama ömrünün 44 gün olduğunu belirtiliyor.” (Kahle, 1997) Bir Web sitesinin “yarı ömrü” (half-life) 2 yıl civarında
. Başka bir deyişle, bir belge bir defa dizinlendikten sonra bir daha dizinleme işlemine tabi tutulmaz. Arama motorlarının mimarisi ise bilgi erişim sistemlerininkine göre farklı, çünkü çok daha dinamik bir yapı var. Web kaynakları tahmini olarak ortalama 75 gün değişmeden kalmaktadırlar. (Brake, 2001) Web kaynaklarının %40’ı her ay değişiyor. (Kahle, 1996) Internet ortamındaki bir bağlantının (link) ortalama ömrünün 44 gün olduğunu belirtiliyor. (Kahle, 1997) Bir Web sitesinin yarı ömrü (half-life) 2 yıl civarında.")
5
Infographic: Half-Life Of Social Media Shares

6
Bilgi erişim sistemlerinin işlevsel mimarisi
ön yüz arka yüz (Tonta, Bitirim, ve Sever, 2002)
")
7
Arama motorlarının işlevsel mimarisi

8
Arama motorlarının işlevsel mimarisi
Arama motorları üç ana modülden oluşur. Bunlar; Web örümceği (Web crawler/spider), Dizinleme ve Arama modülleridir.
, Dizinleme ve. Arama modülleridir.")
9
Arama motorlarının işlevsel mimarisi

10
Web örümceği Internetteki tüm web sayfalarını keşfetmeyi ve toplamayı amaçlar. Böylece bu sayfalara erişimi mümkün kılar. Bir web örümceğinin kalitesi aşağıdaki ölçütlere göre değerlendirilebilir: Kapsama Alanı: Web'in yüzde kaçını toplayabildi? Güncellik: Toplanan sayfalar ne kadar güncel? İşe yararlılık: Toplanan sayfalar popüler ve önemli sayfalar mı? (Ricardo Baeza-Yates, B. Barla Cambazoglu, 2010)
")
11
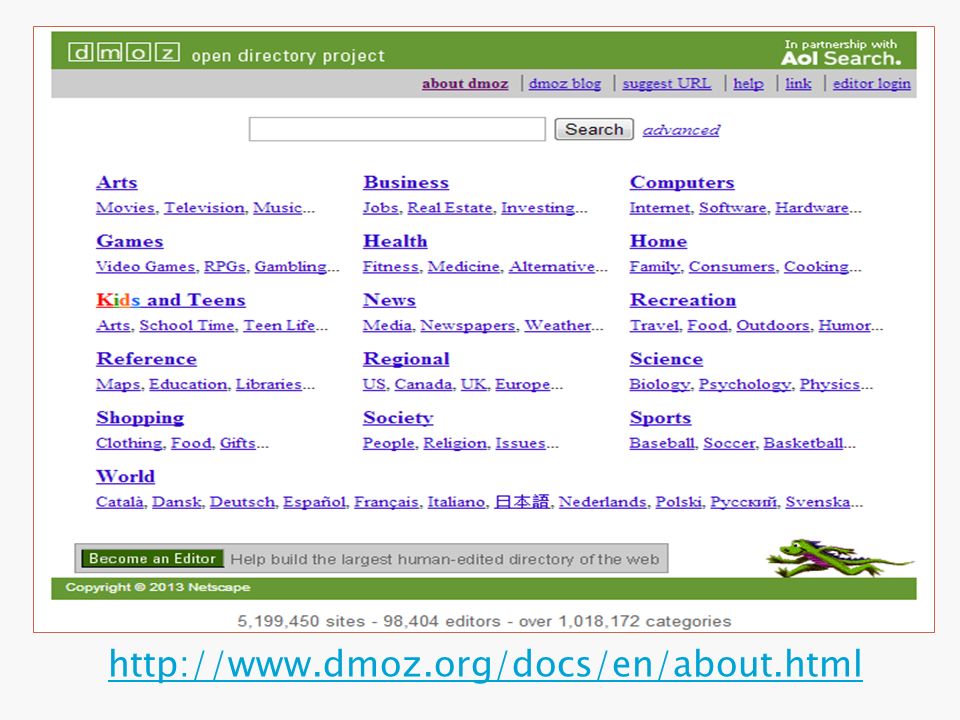
Web örümceği Ziyaret edilecek olan sayfaların bir listesini tutar, sıraya uygun olarak bu sayfaları ziyaret eder, içeriklerini getirir ve link analizi yaparak ziyaret edilmesi gereken yeni sayfaları keşfeder. Web örümcekleri, başlangıçta hangi web sayfalarını ziyaret edeceklerini bilmek zorundadır bu nedenle bir başlangıç listesi (seed) verilir. Başlangıç listeleri için genellikle DMOZ ( linkleri kullanılıyor.
 verilir. Başlangıç listeleri için genellikle DMOZ ( linkleri kullanılıyor.")
13
Web örümceği (politikalar)
Web'in çok büyük boyutta ve değişken olması Web örümcekleri için en önemli sorun. Bu sorunları çözmek için bazı kararlar almak ve politikalar üretmek gerekir: Web Sayfası Seçimi (selection) Politikası: Tüm web sayfalarını belirlenen süre içinde toplamak mümkün olamayacağı için bir "Web Sayfası Seçimi Politikası"na ihtiyaç vardır. Toplanacak web sayfalarının türünü belli kriterlere göre önceliklendirmek gerekmektedir (link analizi). Ör: En çok referans (link) alan sayfalar, bloglar, vs.. Yeniden Ziyaret Etme (re-visit) Politikası: Sayfalarının dinamik olması ve çok hızlı değişmeleri nedeniyle sayfaların en güncel halini elde etmek gerekir. Web örümceği tarafından yakalanan ve indekste saklanan bir sayfa, bu sayfada zamana bağlı olarak meydana gelebilecek değişiklik ve güncellemeleri yansıtabilmesi için düzenli olarak tekrar ziyaret edilmelidir. Bu ziyaretlerin ne zaman yapılacağını belirlemek için sayfanın yenilenme (freshness) hızı ya da yaş (age) değerine bakılır. Bazı arama motorları bu değerlere bakmadan düzenli aralıklarla getirilen sayfaları tekrar ziyaret eder. (Tunç, 2012)
 Politikası: Tüm web sayfalarını belirlenen süre içinde toplamak mümkün olamayacağı için bir Web Sayfası Seçimi Politikası na ihtiyaç vardır. Toplanacak web sayfalarının türünü belli kriterlere göre önceliklendirmek gerekmektedir (link analizi). Ör: En çok referans (link) alan sayfalar, bloglar, vs.. Yeniden Ziyaret Etme (re-visit) Politikası: Sayfalarının dinamik olması ve çok hızlı değişmeleri nedeniyle sayfaların en güncel halini elde etmek gerekir. Web örümceği tarafından yakalanan ve indekste saklanan bir sayfa, bu sayfada zamana bağlı olarak meydana gelebilecek değişiklik ve güncellemeleri yansıtabilmesi için düzenli olarak tekrar ziyaret edilmelidir. Bu ziyaretlerin ne zaman yapılacağını belirlemek için sayfanın yenilenme (freshness) hızı ya da yaş (age) değerine bakılır. Bazı arama motorları bu değerlere bakmadan düzenli aralıklarla getirilen sayfaları tekrar ziyaret eder. (Tunç, 2012)")
14
Web örümceği (politikalar)
Nezaket (politeness) Politikası: Web sayfalarının içeriğini indirme işlemi sayfanın ait olduğu web sitesi sunucusuna belli bir yük getirmektedir. Çok sık aralıklarda örümcekler bu sayfaları indirmeye çalıştığında sunucular diğer istemcilere hizmet edemez hale gelebilmektedir. Bu politikada bir web sayfasının en az kaç saniye aralıklarla indirileceği belirlenir. Web örümcekleri tarafından kullanılan bot’lar, web siteleri için ilgili web serverlara sayfaları indirmek için istek yollarlar, Örümcekler tarafından kullanılan bant genişliği çok fazla olduğu için örümceğin kullandığı bot, ilgili web sitesinin sınırlı bant genişliğinin tamamını kullanabilir (sonuç: “server overload”), Bu durumda, ilgili siteye erişmeye çalışan diğer kullanıcılar yoğunluktan dolayı sayfalara erişemez, bu istenmeyen bir durumdur. Bu tıkanıklığı engellemek için “robots exclusion protocol” yöntemi kullanılır, Bu protokolde sunucuda tutulan robots.txt dosyasında örümceklerin erişmesi istenmeyen sayfalar ve web sunucusuna örümcek tarafından yapılacak iki istek arasında geçmesi gereken zaman gibi parametreler yazılır. (Tunç, 2012) Ayr. Bkz.
 Politikası: Web sayfalarının içeriğini indirme işlemi sayfanın ait olduğu web sitesi sunucusuna belli bir yük getirmektedir. Çok sık aralıklarda örümcekler bu sayfaları indirmeye çalıştığında sunucular diğer istemcilere hizmet edemez hale gelebilmektedir. Bu politikada bir web sayfasının en az kaç saniye aralıklarla indirileceği belirlenir. Web örümcekleri tarafından kullanılan bot’lar, web siteleri için ilgili web serverlara sayfaları indirmek için istek yollarlar, Örümcekler tarafından kullanılan bant genişliği çok fazla olduğu için örümceğin kullandığı bot, ilgili web sitesinin sınırlı bant genişliğinin tamamını kullanabilir (sonuç: server overload ), Bu durumda, ilgili siteye erişmeye çalışan diğer kullanıcılar yoğunluktan dolayı sayfalara erişemez, bu istenmeyen bir durumdur. Bu tıkanıklığı engellemek için robots exclusion protocol yöntemi kullanılır, Bu protokolde sunucuda tutulan robots.txt dosyasında örümceklerin erişmesi istenmeyen sayfalar ve web sunucusuna örümcek tarafından yapılacak iki istek arasında geçmesi gereken zaman gibi parametreler yazılır. (Tunç, 2012) Ayr. Bkz.")
15
Web örümceği (politikalar)
Paralel Çalışma (parallelisation) Politikası: Bilgi erişim sistemi hız kazanmak açısından birden fazla web örümceği çalıştırıyorsa aynı web sayfasının birçok örümcek tarafından indirilmemesi için bir "Paralel Çalışma Politikası" belirlenerek tekrarlı sayfa indirmenin engellenmesi gerekir. Ör: Her örümceğin farklı yer sağlayıcılarla yönlendirilmesi gibi... (Castillo, 2004) (Tunç, 2012)
 Politikası: Bilgi erişim sistemi hız kazanmak açısından birden fazla web örümceği çalıştırıyorsa aynı web sayfasının birçok örümcek tarafından indirilmemesi için bir Paralel Çalışma Politikası belirlenerek tekrarlı sayfa indirmenin engellenmesi gerekir. Ör: Her örümceğin farklı yer sağlayıcılarla yönlendirilmesi gibi... (Castillo, 2004) (Tunç, 2012)")
16
Web örümceği (sayfa getirici ve dil tespiti)
Belirli dillere özel web örümcekleri tasarlayabilmek için dil tespiti gerekir, Örneğin, çok dilli web üzerinde sadece Türkçe belgelerin toplanmasını sağlayacak akıllı web örümceği yaratmak konusu akademik bir problem. Bunun bir problem olmasının iki temel nedeni var: Web üzerinde her bir belgenin dilini tespit etmek Sadece belirli dille yazılmış belgeleri seçmek Bunun bir problem olmasının iki temel nedeni var: Web üzerinde her bir belgenin dilini tespit etmek Sadece belirli dille yazılmış belgeleri seçmek

17
Web örümceği (sayfa getirici ve dil tespiti)
Web üzerindeki Türkçe belgelerin tespit edilmesine yönelik olarak kullanılan farklı yöntemler var ve yöntemler genellikle istatistiklere dayanıyor: Sesli / sessiz harf yaklaşımı: Türkçe’de kelimelerin %50’si sesli harfle bitiyor. İngilizce kelimelerin %28’i sesli harfle bitiyor Türkçe heceleme kurallarına göre karar verme: bir belgedeki kelimelerin %70’i Türkçe heceleme kurallarına uygun olarak heceleniyorsa belge Türkçe’dir. Durma kelimeleri yaklaşımı: bir belge içinde Türkçe için tanımlanan durma kelimelerinden farklı n tanesi geçiyorsa belge Türkçe’dir. Türkçe karakter yaklaşımı: bir belge içerisinde Türkçe karakterlerden (ı, ç, ş, ğ, ü) farklı n tanesi geçiyorsa belge Türkçe’dir. * Sesli / sessiz harf yaklaşımı: Türkçe’de kelimelerin %50’si sesli harfle bitiyor. İngilizce kelimelerin %28’i sesli harfle bitiyor * Türkçe heceleme kurallarına göre karar verme: bir belgede ki kelimelerin %70’i Türkçe heceleme kurallarına uygun olarak heceleniyorsa belge Türkçe’dir. * Durma kelimeleri yaklaşımı: bir belge içinde Türkçe için tanımlanan durma kelimelerinden farklı n tanesi geçiyorsa belge Türkçe’dir. * Türkçe karakter yaklaşımı: bir belge içerisinde Türkçe karakterlerden (ı, ç, ş, ğ, ü) farklı n tanesi geçiyorsa belge Türkçe’dir.
 farklı n tanesi geçiyorsa belge Türkçe’dir. * Sesli / sessiz harf yaklaşımı: Türkçe’de kelimelerin %50’si sesli harfle bitiyor. İngilizce kelimelerin %28’i sesli harfle bitiyor. * Türkçe heceleme kurallarına göre karar verme: bir belgede ki kelimelerin %70’i Türkçe heceleme kurallarına uygun olarak heceleniyorsa belge Türkçe’dir. * Durma kelimeleri yaklaşımı: bir belge içinde Türkçe için tanımlanan durma kelimelerinden farklı n tanesi geçiyorsa belge Türkçe’dir. * Türkçe karakter yaklaşımı: bir belge içerisinde Türkçe karakterlerden (ı, ç, ş, ğ, ü) farklı n tanesi geçiyorsa belge Türkçe’dir.")
18
Sorgu Web arama motorlarına yöneltilen sorgular kısa
Ortalama ~2,4 kelime Kullanıcı beklentileri “İlk sırada gelen sonuç benim görmek istediğim sonuç olmalı!”

19
Arama sonuçlarının derecelendirilmesi
Pek çok arama motoru erişim fonksiyonu (vektör uzayı, olasılıksal, dil modeli v.b.) olarak kullanılan yöntemlerin belge/sorgu eşleşmesi için ürettiği skor değerlerine göre bir derecelendirme yapar. Google ile birlikte bu derecelendirme skoruna link alma skorları da eklendi. PageRank (Sayfa değeri) yöntemi, Internet üzerinde bir sayfaya diğer sayfalardan ne kadar fazla referans (link) verilirse o sayfanın o kadar değerli olacağı görüşü üzerine geliştirilmiştir. Bu yaklaşım “bilimsel bir çalışmaya diğer makalelerden ne kadar çok atıfta bulunulursa o çalışma o kadar önemlidir” mantığına benzemektedir.
 olarak kullanılan yöntemlerin belge/sorgu eşleşmesi için ürettiği skor değerlerine göre bir derecelendirme yapar. Google ile birlikte bu derecelendirme skoruna link alma skorları da eklendi. PageRank (Sayfa değeri) yöntemi, Internet üzerinde bir sayfaya diğer sayfalardan ne kadar fazla referans (link) verilirse o sayfanın o kadar değerli olacağı görüşü üzerine geliştirilmiştir. Bu yaklaşım bilimsel bir çalışmaya diğer makalelerden ne kadar çok atıfta bulunulursa o çalışma o kadar önemlidir mantığına benzemektedir.")
20
Sayfa değeri (PageRank)
Google'ın site sıralamasında kullandığı algoritma bir web sitesine verdiği değeri gösteren 0'dan 10'a kadar olan bir değerdir. Bu değer genel olarak özgün bir içeriğe, sayfaya verilmiş bağlantılara ve bağlantı veren sayfaların kalitesine bağlı olarak değişir. PageRank, değer olarak bir web sitesinin Google tarafından arama sonuçlarında sıralanmasını ve Google tarayıcısının (örümceğinin) siteyi kontrol etme sıklığını etkiler.
 siteyi kontrol etme sıklığını etkiler.")
21
Sayfa değeri (PageRank)
PageRank'in ana fikri şöyledir: Eğer bir A sitesi B sitesinin linkini yayımlamışsa bunun nedeni B sayfasının A sayfası ziyaretçileri tarafından dolaşılabilecek olarak düşünülmüş olmasıdır. Bu yapıya göre A sayfası B sayfasının sayfa derecesini yükseltmiş olacaktır. A sayfası ne kadar yüksek sayfa değerine sahipse B sayfasının değeri de buna orantılı olarak artacaktır. A sayfasında ne kadar az dışarı link varsa, B sayfasının değeri o kadar yüksek olacaktır. Bu mantığa göre A sayfası sadece B sayfasını link verilecek değerde görmüşse, B sayfasının “PageRank”i çok daha fazla artacaktır. Örnek?

22
Life of a Google Query How search works Facts about Google
m/watch?v=BNHR6IQJG Zs Facts about Google m/competition/ Your answer loud and clear m/insidesearch/

23
Bilgi erişim sistemlerinde araştırma konuları - Birleştirilmiş arama motorları (Meta search engines)
Kullanıcıyı birden fazla arama motorunda arama yapma külfetinden kurtarır. Kullanıcı farklı arama motorlarının birbirinden farklı sorgu dillerini öğrenmek zorunda kalmaz. Sistem arama motorlarının en yüksek ilişkili sonuçlarını kullanıcıya en üstte sunduğu için kullanıcının aradığını kolayca bulma olasılığı yükselmektedir. (Meng, August 2009) Örnekler: AllInOneNews, Search Aggregator, Travelfox
 Örnekler: AllInOneNews, Search Aggregator, Travelfox.")
24
Bilgi erişim sistemlerinde araştırma konuları - Kişiselleştirilmiş arama (personalized search)
Kullanıcının internetteki aktivitelerinin, bilgi tüketim alışkanlıklarının izlenerek kullanıcı hakkında edinilen bilgilerin bilgi erişim sistemlerinde kullanılması ve kullanıcıya “anlamlı” sonuçlar döndürülmesi olarak tanımlanır. (Pitkow, Schütze, Cass, Cooley, Turnbull, Edmonds, Adar, Breuel, 2002) Özel hayatın gizliliği ve kullanıcıların zamanla ilgi alanlarının değişmesi konularına dikkat edilmelidir.
 Özel hayatın gizliliği ve kullanıcıların zamanla ilgi alanlarının değişmesi konularına dikkat edilmelidir.")
25
Bilgi erişim sistemlerinde araştırma konuları - Anlamsal arama (semantic search)
Anlamsal aramada sorgu sözcüklerinin belgede bulunma sıklığı değil kullanıcının gerçekte neyi aradığı ve web içeriklerinin konusu /anlamı önemlidir. Sorgu sözcükleriyle eş anlamlı sözcükler de aramaya dahil edilir. Sözcüklerin tüm varyasyonları aramaya dahil edilir: improve, improved, improvement Sadece anahtar kelime değil konu ile ilgili diğer kelimelerin de bilinmesi gerekir.(ontological knowledge) Ör: üst solunum yolu enfeksiyonu ->(nezle, grip, sinüzit, faranjit)
 Ör: üst solunum yolu enfeksiyonu ->(nezle, grip, sinüzit, faranjit)")
26
Bilgi erişim sistemlerinde araştırma konuları - Anlamsal arama (semantic search) ~Sorunlar
Anlamsal arama için yapılması gereken ön çalışma (ontoloji oluşturma) çok uzun zaman almaktadır. Doğal dil sorgularını makinenin anlayabileceği ontolojik sorgulara dönüştürmek henüz mümkün olmamıştır. Web içeriğinde konunun, anlamın bulunması da çözülmeyi bekleyen sorunlar arasındadır. Hakia, DBpedia
 çok uzun zaman almaktadır. Doğal dil sorgularını makinenin anlayabileceği ontolojik sorgulara dönüştürmek henüz mümkün olmamıştır. Web içeriğinde konunun, anlamın bulunması da çözülmeyi bekleyen sorunlar arasındadır. Hakia, DBpedia.")
27
Bilgi erişim sistemlerinde araştırma konuları – Soru-yanıt sistemleri (question-answering systems)
Kullanıcının sorduğu soruya cevap olarak bulduğu bilgileri toparlayıp tek bir sonuç olarak döndürür. Günümüz soru yanıtlama sistemleri "soru sınıflama" modülü ile sorunun ve cevabın türünü belirlerler. Soru analiz edildikten sonra sistem metinler üzerinde karmaşık doğal dil işleme tekniklerini çalıştırır. Bu sırada bir filtre cevabın türüne göre paragraflar arasından cevabı bulur. Örneğin soruda "kim" sorusu soruluyorsa cevap bir özel isim olmalıdır. webclopedia.com, answerbus.com, answers.com

28
Bilgi erişim sistemlerinde araştırma konuları - Konu tespit ve takip sistemleri (topic detection and tracking) Haber yayınlarının izlenerek yeni ve ilginç bir haber olduğunda ilgililerin uyarılmasını sağlayan sistemlerdir. Dört ana modülden oluşur. “İlk Hikaye Algılama Modülü“ sisteme yeni bir hikaye ulaştığında bunun tartıştığı konu daha önceden tanımlanmış konularla ilgili değilse, yeni bir konu olduğunu belirler. "Küme Belirleme Modülü" gelen hikaye bir ilk hikaye değilse ilgili konu kümesine yerleştirir, eğer ilk hikaye ise bunun için yeni bir küme oluşturur. "Haber İzleme Modülü" haber kaynaklarından sisteme gelen haberleri değerlendirilerek, bu haberlerin daha önceden belirlenmiş olan konularla ilgili olup olmadıklarını araştırır. "Hikaye Bağlantı Algılama Modülü“ ise sisteme ulaşan iki farklı hikayenin aynı konuyu tartışıp tartışmadıklarını anlamayı amaçlar.
![]()
29
Sonuç Mobil cihazların sabit ve dizüstü bilgisayarların yerine geçmesi internete erişimi kolaylaştıracak, içerik oluşturma hızlanacak. 4G ve 5G ile bant genişliklerinin 2-3 katına çıkması nedeniyle veri iletimi hızlanacak. Bu gelişmeler dünyada üretilen bilginin daha da hızla artmasına neden olacak. Bilgi Erişim Sistemleri sadece metin değil aynı oranda ses, video, resim arama araçları olacak. Bu nedenlerle Bilgi Erişim sistemlerinin hem işi zorlaşacak hem de ihtiyacın artmasıyla gün geçtikçe daha da önem kazanacak. Doğru kaynağa en kısa zamanda ulaşabilmek için kullanıcıyı tanıyan, arama yaparken niyetini anlayan, web içeriğinin konusunu tespit edebilen akıllı sistemlere ihtiyaç var. (Tunç, 2012)
")
30
Önemli!=> Google arama özellikleri
Google search features: Improve your search experience Google Inside Search: Search tools and filters 2143?hl=en&ref_topic= Google Inside Search: Search operators 6861?hl=en&ref_topic=

31
Okuma listesi Tonta, Y. (1995). Bilgi erişim sistemleri. ( Erbil, E ve Çolakkol, A. (2001). Internet’te bilgi arama stratejileri ve bilgiye erişim. ( Olcay, N.E. (2003). Türkçe Internet tarama motoru kullanıcılarının arama stratejilerinin analizi: Arabul örneği. ( Tunç, S.K. (2012). Bilgi erişim sistemleri. ( Diğer yardımcı kaynaklar: Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval. (Tam metin) Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval. (Tam metin) Bu derste kullanılan slaytların çoğunluğu Bilgi erişim ilkeleri (Y. Tonta, 2002) Bilgi erişim (G. Köse, 2012) derslerine ait slaytlardan ve Sevgi Koyuncu Tunç’un “Bilgi Erişim Sistemleri” başlıklı yayımlanmamış çalışmasından derlenmiştir.
. Internet’te bilgi arama stratejileri ve bilgiye erişim. ( Olcay, N.E. (2003). Türkçe Internet tarama motoru kullanıcılarının arama stratejilerinin analizi: Arabul örneği. ( Tunç, S.K. (2012). Bilgi erişim sistemleri. ( Diğer yardımcı kaynaklar: Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval. (Tam metin) Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval. (Tam metin) Bu derste kullanılan slaytların çoğunluğu. Bilgi erişim ilkeleri (Y. Tonta, 2002) Bilgi erişim (G. Köse, 2012) derslerine ait slaytlardan ve. Sevgi Koyuncu Tunç’un Bilgi Erişim Sistemleri başlıklı yayımlanmamış çalışmasından. derlenmiştir.")
Benzer bir sunumlar
















 sahip olurlar. >")

 TEMEL ETİKETLERİ>")
