Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
Örnekleme ve Örneklem Dağılımları
Yrd. Doç. Dr Hamit ACEMOĞLU 1

2
1. sınıf Biyoistatistik 2009-2010
Amaç Bu dersin amacı:Öğrencilerin bu konu sonunda örnekleme ve örneklem dağılımları hakkında bilgi sahibi olması amaçlanmıştır. 1. sınıf Biyoistatistik 2

3
1. sınıf Biyoistatistik 2009-2010
Öğrenim Hedefleri Hedefler: Bu konu sonunda öğrencilerin aşağıdaki hedeflere ulaşması beklenmektedir: Neden örnekleme yaptığımızı açıklayabilmek Örneklem hacmini etkileyen faktörleri sayabilmek Örnekleme çeşitlerini açıklayabilmek SEM ve SEP formüllerini yazabilmek SD ve SEM kullanım alanlarını açıklayabilmek 1. sınıf Biyoistatistik 3

4
1. sınıf Biyoistatistik 2009-2010
İstatistik yaparken genelde bir toplumun tamamı hakkında bilgi toplamak ve yorum yapmak isteriz. Ancak, toplumun tamamından veri elde etmek gerek zaman, gerekse ekonomik açıdan genelde mümkün olmaz. Bu nedenle toplumu temsil edecek bir örneklemden veri toplar ve o verileri kullanarak toplum hakkında çıkarımlar yaparız. 1. sınıf Biyoistatistik 4 4

5
1. sınıf Biyoistatistik 2009-2010
Toplumdan bir örneklem aldığımızda örneklemimizin toplumu tamamen temsil edemeyeceğini tahmin edebiliriz. Toplumun sadece bir kısmını inceleyerek bir örnekleme hatası oluşturmuş oluyoruz. Bu derste teorik dağılımları kullanarak bu hatayı hesaplamayı öğreneceğiz. 1. sınıf Biyoistatistik 5 5

6
Örneklem Hacmini Etkileyen Faktörler
Veri tipi Kategorik : Yüzde ya da oran Sayısal : Ortalama Yaygınlık Alfa (α) önemlilik düzeyi Testin gücü (1-β) Etki Genişliği (Δ) Hipotez testi sonucunda doğru olarak saptayabilmek istediğimiz en küçük değişiklik miktarıdır. Diğer bir deyişle, yokluk hipotezinde ve alternatif hipotezde belirtilen değerler arasındaki farktır. Kitlenin büyüklüğü (N)
 önemlilik düzeyi. Testin gücü (1-β) Etki Genişliği (Δ) Hipotez testi sonucunda doğru olarak saptayabilmek istediğimiz en küçük değişiklik miktarıdır. Diğer bir deyişle, yokluk hipotezinde ve alternatif hipotezde belirtilen değerler arasındaki farktır. Kitlenin büyüklüğü (N)")
7
Kitle oranını kestirmek için örneklem büyüklüğü
Kitle büyüklüğü N bilinmediğinde Kitle büyüklüğü N bilindiğinde n: örnekleme alınacak birey sayısı p: incelenen olayın görülüş sıklığı t: belirli serbestlik derecesinde ve saptanan yanılma düzeyinde t tablo değeri d: olayın görülüş sıklığına göre yapılmak istenen sapma

8
ÖRNEK: Malnütrisyon oranının p=0.15 olduğu daha önce yapılan bir çalışmada saptanmış olsun. Bir araştırıcı yapacağı araştırmada bu değerin ± 0.05 “d” sınırları içinde yani, bulacağı değerin 0.10 – 0.20 arasında olmasını, Bu sınırlar arasına =0.05 yanılma düzeyinde başka bir ifadeyle %95 güvenirlikle bulunmasını istemektedir. Araştırıcı çalışmayı kaç kişi üzerinde yürütmelidir?

9
Sonuç: Toplumda 0.15 oranında görülen bir olayın % 95 olasılıkla sınırları arasında incelemesi isteniyorsa en az “196” birey üzerinde çalışılmalıdır.

10
Kitle ortalamasını kestirmek için örneklem büyüklüğü
Kitle büyüklüğü N bilinmediğinde Kitle büyüklüğü N bilindiğinde : kitle standart sapması d: ortalamaya göre yapılmak istenen ± sapma

11
Uygun Örnekleme Yöntemi
Örneklemede Rasgelelik Örneklemede Rasgelelik, kitledeki her deneğe örnekleme seçilme yönünden eşit şans verilmesidir. Bu şansın eşitlenememesi durumunda; örneklemeden elde edilecek sonuçlardaki hatalar rasgele olmayacağı için sonuçlar yanlı olur. Örneklemede yansız sonuçlar elde edebilmek için rasgelelik koşullarına uyulmalıdır. 1. sınıf Biyoistatistik 11

12
Örnekleme Yöntemleri Olasılıklı Örnekeleme Olasılıksız Örnekleme
Kota Örneklemesi Kartopu Örneklemesi B. Rasgele Örnekleme Tabakalı Örnekleme Küme Örneklemesi

13
Olasılıklı Örnekleme Yöntemleri
Olasılıklı örnekleme yöntemlerinde örnekleme seçilecek örnek birimlerine eşit şans verilir. Örnek birimlerine eşit şans verilerek kitledeki değişkenliğin örneklemde korunması sağlanır. Böylece örneklemin kitleyi temsil yeteneği artırılmış olur. Kitledeki her örnek birimine örnekleme seçilme yönünden eşit şans verebilmek için kitledeki birimler arasından rasgele seçim yapılır. Rasgeleliği sağlayabilmek için rasgele sayılar tablosu yada rasgele sayı üreten bilgisayar yazılımlarından yararlanılır. 1. sınıf Biyoistatistik 13

14
Basit Rasgele Örnekleme
Basit Rasgele Örnekleme, elde edilmesi istenen bilgide farklılık yaratacak herhangi faktörün olmadığı, kitledeki deneklere ulaşmanın olanaklı olduğu durumlarda basit rasgele seçim yöntemine göre örneklem oluşturulmasına denir. Bu yöntemde uygun örneklem büyüklüğü belirlendikten sonra, basit rasgele örnek seçim yöntemi ile örnekler seçilir. Seçim sonrası oluşan örneklem istatistikleri hesaplanarak kitle parametreleri için kestirimler yapılır. 1. sınıf Biyoistatistik 14

15
1. sınıf Biyoistatistik 2009-2010
Tabakalı örnekleme Bu örnekleme, toplanmak istenen bilginin doğruluğunu etkliyecek faktörler olduğunda, kitleyi bu faktör gruplarına göre tabakalara ayırarak her tabakadan ayrı ayrı örneklem seçerek yapılır. Her tabakan ayrı örneklem seçerek, tabakaların(faktör gruplarının) kitledeki değişkenliği örneklemde de korunarak örneklemin kitleyi temsil yeteneği artırılmış olur. Tabakalı örneklemeden iyi sonuç alabilmek için Tabakalar, kendi içinde homojen Tabakalar, kendi aralarında heterojen olmalıdır. 1. sınıf Biyoistatistik 15
 kitledeki değişkenliği örneklemde de korunarak örneklemin kitleyi temsil yeteneği artırılmış olur. Tabakalı örneklemeden iyi sonuç alabilmek için. Tabakalar, kendi içinde homojen. Tabakalar, kendi aralarında heterojen olmalıdır. 1. sınıf Biyoistatistik")
16
1. sınıf Biyoistatistik 2009-2010
Küme Örneklemesi Kitledeki deneklerin listelenemediği bu nedenle tek tek deneklere ulaşmanın olanaksız olduğu durumlarda kullanılan örnekleme yöntemidir. Bu yöntemde, kitle birbirine benzer deneklerden oluşan kümelere (denek grupları) ayrılır. Bu yöntemde, denek seçme yerine küme seçilerek örneklem oluşturulur. 1. sınıf Biyoistatistik 16
 ayrılır. Bu yöntemde, denek seçme yerine küme seçilerek örneklem oluşturulur. 1. sınıf Biyoistatistik")
17
1. sınıf Biyoistatistik 2009-2010
Örneklem varyasyonu Aynı toplumdan aynı büyüklükte örneklemler alsak bile µ ve σ gibi parametrelerde farklılıklar olacaktır. Halbuki bir toplumla ilgili tahminlerimizin gerçek değere yakın olmasını isteriz. Eğer bu farklılıkları rakama dökebilirsek, tahminimizin hasssasiyeti konusunda bilgi olabiliriz ve böylece örnekleme hatamızın düzeyi hakkında fikrimiz olur. Gerçekte tolumdan tek bir örneklem almamıza rağmen yine de teorik dağılımlarla ilgili bilgilerimizi kullanarak toplum geneli hakkında çıkarımlar yaparız. 1. sınıf Biyoistatistik 17

18
Ortalamanın örneklem dağılımı
Toplum ortlamasını ölçmeye çalışıyoruz. Toplumdan n sayıda örneklemler alıp bunların ortalamasını hesaplayabiliriz. Bu ortalamaların bir histogram grafiğini çıkarsak ortalamaların dağılımını görebiliriz. Buna ortalamanın örneklem dağılımı denir. 1. sınıf Biyoistatistik 18

19
1. sınıf Biyoistatistik 2009-2010
19 19
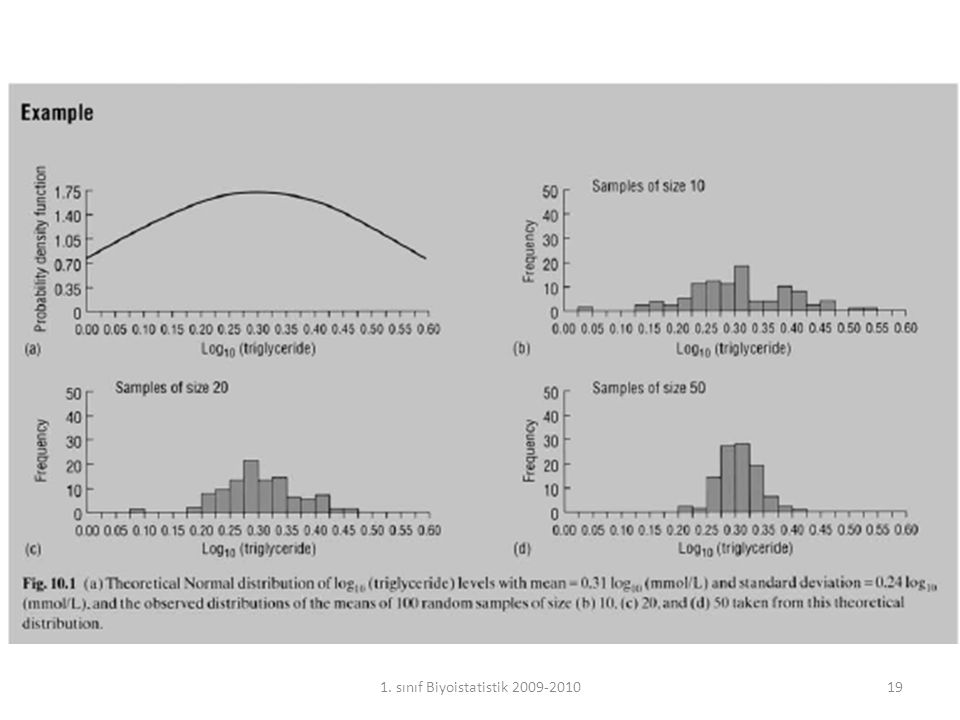
20
1. sınıf Biyoistatistik 2009-2010
Bu dağılıma bakarak şunları söyleyebiliriz: Örneklem sayısı yeterince büyük olursa, asıl verinin nasıl dağıldığına bakılmaksızın ortalamaların dağılımı normal dağılıma yakın olur (Central Limit Theorem). Örneklem sayısı küçükse, asıl verinin normal dağılması halinde ortalamalar normal dağılıma yakın olur. Bu ortalamaların ortalaması gerçek (unbiased) toplum ortalamasını verir. Bu dağılımın variabilitesi alınan ortalamaların standart sapmasıyla hesaplanır. Buna ortalamanın standart hatası (SEM) denir. Toplumun standart sapmasını (σ) bilmemiz halinde ortalamanın standart hatası SEM = σ / √n formülüyle hesaplanır. 1. sınıf Biyoistatistik 20 20
. Örneklem sayısı küçükse, asıl verinin normal dağılması halinde ortalamalar normal dağılıma yakın olur. Bu ortalamaların ortalaması gerçek (unbiased) toplum ortalamasını verir. Bu dağılımın variabilitesi alınan ortalamaların standart sapmasıyla hesaplanır. Buna ortalamanın standart hatası (SEM) denir. Toplumun standart sapmasını (σ) bilmemiz halinde ortalamanın standart hatası SEM = σ / √n formülüyle hesaplanır. 1. sınıf Biyoistatistik")
21
1. sınıf Biyoistatistik 2009-2010
Genelde olduğu gibi, toplumdan tek bir örneklem almışsak, toplum ortalamasının en iyi tahmini örneklemimizin ortalaması olacaktır. Bu durumda toplumun standart sapmasını da bilmediğimizden ortalamanın standart hatasını SEM = s / √n formülüyle hesaplarız. SEM, tahminimizin hassasiyeti konusunda bilgi verir. Tahminimizin ne kadar hassas olduğunu gösterir. Büyük bir standart hata, tahminimizin hassas olmadığını gösterir. Stadart hatanın küçük olması ise tahminimizin hassas olduğunu gösterir. Örneklem sayısının artırılması veya verilerin variabilitesinin daha az az olması halinde standart hatayı küçültmek, yani daha hassas bir tahmin yapmak mümkündür. 1. sınıf Biyoistatistik 21 21

22
Standart sapma mı standart hata mı?
Bu iki parametre birbirine benzer görünse de farklı amaçlarla kullanılırlar. Standart sapma verilerdeki varyasyonu (ortalamadan sapmayı) gösterir ve bu bilgiyi göstermek istediğimizde kullanılmalıdır. Buna karşın standart hata, örneklem ortalamasının hassasiyetini gösterir ve ölçümümüzün hassasiyetini vurgulamak istediğimizde kullanılmalıdır. 1. sınıf Biyoistatistik 22
 gösterir ve bu bilgiyi göstermek istediğimizde kullanılmalıdır. Buna karşın standart hata, örneklem ortalamasının hassasiyetini gösterir ve ölçümümüzün hassasiyetini vurgulamak istediğimizde kullanılmalıdır. 1. sınıf Biyoistatistik")
23
Orantının örneklem dağılımı
Araştırmamızda toplumdaki bir ortantıyı incelediğimizi düşünelim. Topmumdan n sayıda örneklem almamız ve orantımızın p olması halinde toplum ortalaması π için en iyi tahmin p = r / n şeklinde hesaplanabilir (r, toplumda araştırdğımız özelliğe sahip kişilerin sayısı). Eğer toplumdan tekrarlayan n sayıda örneklemler alsak ve ortantılarımızın histogram grafiklerini çizsek, sonuçta ortaya çıkan orantının örneklem dağılımının ortalaması π olup normal dağılıma yakın olacaktır. Bu orantıların standart sapmasına orantının standart hatası [SE(p)] denir. 1. sınıf Biyoistatistik 23
. Eğer toplumdan tekrarlayan n sayıda örneklemler alsak ve ortantılarımızın histogram grafiklerini çizsek, sonuçta ortaya çıkan orantının örneklem dağılımının ortalaması π olup normal dağılıma yakın olacaktır. Bu orantıların standart sapmasına orantının standart hatası [SE(p)] denir. 1. sınıf Biyoistatistik")
24
Tek bir örneklem aldığımızda şöyle hesaplanır:
Bu, tahmin ettiğimiz π değerinin hassasiyetini gösterir. Küçük bir standart hata daha hassas bir ölçüme işaret eder.

25
1. sınıf Biyoistatistik 2009-2010
Alıştırmalar Bir araştırmada 250 kişiden alınan kan örneklerinin biyokimyasal analizine göre ortalama açlık kan şekeri 85,7 mg/dl standart sapması 25,4 mg/dl bulunmuştur. Aynı araştırmada kişilerin %15’inde şeker hastalığı saptanmıştır. Ankete katılanların % 20’si şeker hastalığı hakkında bilgisini “iyi” olarak belirtirken % 15’i “hiç bilgisinin olmadığını” belirtmiştir. Paragrafta geçen veri tiplerini tartışın Açlık kan şekerinin SEM’ni hesaplayarak yorumlayın Şeker hastası olanların SEP’ini hesaplayarak yorumlayın Kan şekeri ortalaması ile birlikte SM mi yoksa SEM mi verelim? Neden? 1. sınıf Biyoistatistik 25

26
Cevaplar Veri tipleri Açlık kan şekeri ortalaması=nümerik
Şeker hastası olan kişi sayısı=Nominal Ankete katılanların şeker hastalığı hakkındaki bilgileri=Ordinal Sadece açlık kan şekeri ortalaması verilmiş ve örneklemde gruplar arası bir karşılaştırma yapılmadığından bu örnekte SEM verilmesi gerekir

Benzer bir sunumlar










 ve farklı populasyonlar için ’nın örnekleme dağılışı.>")


>")





