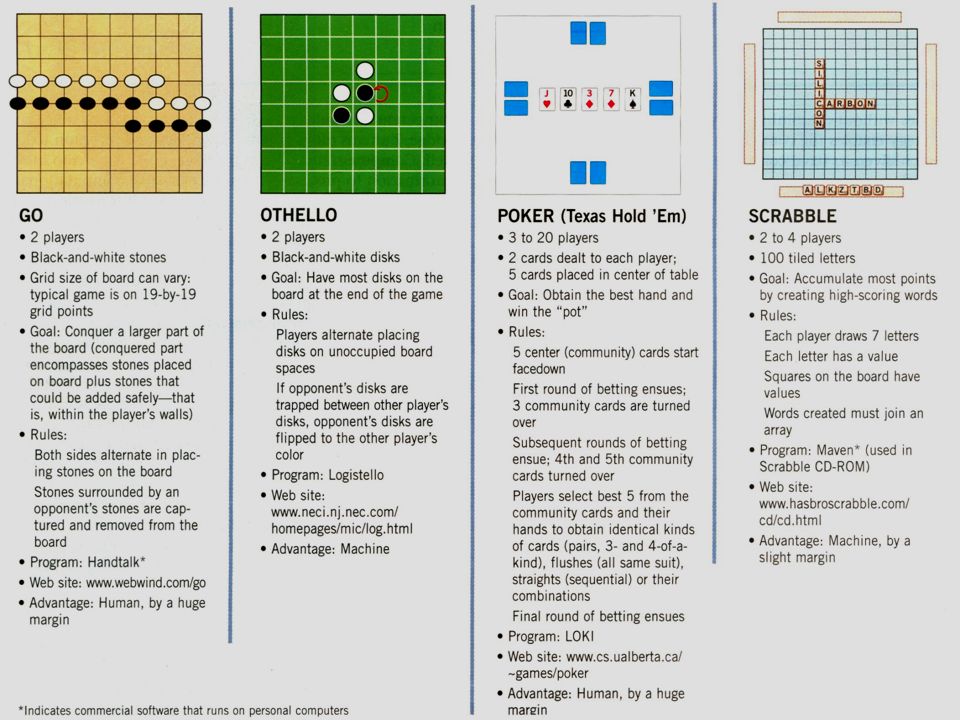
Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
BİL YAPAY ZEKA Hafta 5

2
Rekabet ortamında Arama (Adversarial Search), Oyunlarda Arama
, Oyunlarda Arama")
3
Rekabet ortamında arama
Çoklu etmen ortamı- her bir etmen (agent) karar verirken diğer etmenlerin de hareketlerini dikkate almalı ve bu etmenlerin onun durumunu nasıl etkileyeceğini bilmelidir Olasılık- diğer etmenlerin hareketlerinin tahmin edilebilmemesi “Önceden tahmin edilemeyen" karşı taraf rakibin her olası cevabına karşı bir hareketin belirlenmesi İşbirlikçi ve rakip etmenler Rekabet ortamında arama / oyun Zaman sınırlamaları
 karar verirken diğer etmenlerin de hareketlerini dikkate almalı ve bu etmenlerin onun durumunu nasıl etkileyeceğini bilmelidir. Olasılık- diğer etmenlerin hareketlerinin tahmin edilebilmemesi. Önceden tahmin edilemeyen karşı taraf. rakibin her olası cevabına karşı bir hareketin belirlenmesi. İşbirlikçi ve rakip etmenler. Rekabet ortamında arama / oyun. Zaman sınırlamaları.")
4
Oyun neden öğrenilmeli?
Yapay Zekanın en eski alanlarından birisi (Shannon and Turing, 1950) Zeka gerektiren rekabetin soyut ifadesi Durum ve eylemlerin kolay ifade edilebilirliği Dış dünyadan çok az bilginin gerekli olması Oyun oynama, bazı yeni gereksinimlerle aramanın özel halidir.
 Zeka gerektiren rekabetin soyut ifadesi. Durum ve eylemlerin kolay ifade edilebilirliği. Dış dünyadan çok az bilginin gerekli olması. Oyun oynama, bazı yeni gereksinimlerle aramanın özel halidir.")
5
Oyun Türleri Tam bilgili (perfect info)
Tam olmayan bilgili (imperfect info) Belirlenmiş (deterministic) Şans / rastsal (chance) Satranç, dama, go - tam bilgili, belirlenmiş Tavla- tam bilgili, şans / rastsal Kağıt oyunları- tam olmayan bilgili, şans / rastsal imperfect information - örn: karşı tarafın elindekini bilememe
 Belirlenmiş (deterministic) Şans / rastsal (chance) Satranç, dama, go - tam bilgili, belirlenmiş. Tavla- tam bilgili, şans / rastsal. Kağıt oyunları- tam olmayan bilgili, şans / rastsal. imperfect information - örn: karşı tarafın elindekini bilememe.")
6
Oyunla bağlı sorunlar Oyunların çözümü zordur: “Olasılık ” sorunu
Rakibin hareketini bilmiyoruz ! Arama uzayının boyutu: Satranç : her durumda yaklaşık ~15 hareket, 80 karşılıklı hamle ağaçta 1580 düğüm Go : her durumda ~200 hareket, 300 karşılıklı hamle ağaçta düğüm Optimal çözümün çoğu zaman mümkün olmaması

7
Oyun oynama Algoritmaları
Minimax algoritması Alpha-beta Budama Değerlendirme fonksiyonu Aramayı kesme Her hangi derinlik sınırına kadar arama Derinlik sınırında değerlendirme fonksiyonunun kullanılması Değerlendirmenin tüm ağaç boyunca yayılması

8
Oyun problemlerinde Arama ağaçları
Başlangıç durum- ilk pozisyon ve birinci hamle yapacak oyuncu Ardıl fonksiyonu- (hareket,durum) çiftleri listesini veriyor; geçerli hareket (legal move) ve bu hareket sonucu durum Uç düğüm (terminal) denemesi - oyunun bittiğini belirler. Oyunun son bulduğu durumlara uç düğümler (yapraklar / leaf nodes / terminals) denir Yarar fonksiyonu (utility function)- uç durumlar için sayısal bir değer verir Oyun ağacı - başlangıç durum ve her iki tarafın geçerli hareketleri
 çiftleri listesini veriyor; geçerli hareket (legal move) ve bu hareket sonucu durum. Uç düğüm (terminal) denemesi - oyunun bittiğini belirler. Oyunun son bulduğu durumlara uç düğümler (yapraklar / leaf nodes / terminals) denir. Yarar fonksiyonu (utility function)- uç durumlar için sayısal bir değer verir. Oyun ağacı - başlangıç durum ve her iki tarafın geçerli hareketleri.")
9
Oyun Ağacı Örneği (2-oyunculu tic-tac-toe, belirlenmiş)
Yarar fonk. (Utility): Kazanırsa +1 Kaybederse -1 Beraberlik 0
: Kazanırsa +1. Kaybederse -1. Beraberlik 0.")
10
Minimax Algoritması Belirlenmiş oyunlar için mükemmel taktik
Temel fikir: en yüksek minimax değerli hareketi seçmeli = en iyi ulaşılabilir sonuç

11
Minimax Algoritması S ardıllar(n) S ardıllar(n)
Minimaxdeğer (n)= Yarar(n) , eğer n son durum ise (yaprak / uç düğüm) Max (Minimaxdeğer(s)), n Max düğüm ise (maksimum toplamak isteyen oyuncu, o1) Min (Minimaxdeğer(s)), n Min düğüm ise (o1’e minimum toplatmak isteyen diğer oyuncu, o2) S ardıllar(n) S ardıllar(n)
= Yarar(n) , eğer n son durum ise (yaprak / uç düğüm) Max (Minimaxdeğer(s)), n Max düğüm ise (maksimum toplamak isteyen oyuncu, o1) Min (Minimaxdeğer(s)), n Min düğüm ise (o1’e minimum toplatmak isteyen diğer oyuncu, o2) S ardıllar(n) S ardıllar(n)")
12
Minimax Algoritması

13
Minimax - Özellikleri tam? Evet (eğer ağaç sonlu ise)
Optimal? Evet (optimal rakibe karşı) Zaman karmaşıklığı? O(bm) Uzay karmaşıklığı O(bm) (derinine arama) m: ağacın en fazla derinliği b: her noktada mümkün hamleler sayısı Satranç için b ≈ 35, m ≈100
 Zaman karmaşıklığı O(bm) Uzay karmaşıklığı O(bm) (derinine arama) m: ağacın en fazla derinliği. b: her noktada mümkün hamleler sayısı. Satranç için b ≈ 35, m ≈100.")
14
Satrançta Minimax kullanılırsa…?
Arama uzayının büyüklüğü (3240) Ortalama hamle sayısı = 40 Her adımda yapılabilecek farklı hamle sayısı ortalaması = 32 3240 = 2200 ~ 1060 Saniyede 3 milyar durum işlersek Bir yıldaki saniye sayısı ~ 32*106 Bir yılda işlenecek durum sayısı ~ 1017 Tüm durumların değerlendirilmesi ~ 1043 yıl sürer. Evrenin yaşı ~ 1010 yıl
 Ortalama hamle sayısı = 40. Her adımda yapılabilecek farklı hamle sayısı ortalaması = = 2200 ~ Saniyede 3 milyar durum işlersek. Bir yıldaki saniye sayısı ~ 32*106. Bir yılda işlenecek durum sayısı ~ Tüm durumların değerlendirilmesi ~ 1043 yıl sürer. Evrenin yaşı ~ 1010 yıl.")
15
Minimax Algoritması - Örnek
Sınırlamalar: 2 oyuncu: MAX (bilgisayar) ve MIN (rakip) belirlenmiş, tam bilgi Derinine arama ve değerlendirme fonksiyonu MAX MIN - Derine doğru ağaç oluşturmalı Bu hare- keti seç Her seviye için, en son uç düğüm / yaprağa ulaşılınca, değerlendirme fonksiyonu ile değer hesaplamalı 3 2 1 3 Değerlendirme fonksiyonunu yaymalı: - MIN’de minimum kabul ediliyor - MAX’da maximum kabul ediliyor 2 5 3 1 4
 ve MIN (rakip) belirlenmiş, tam bilgi. Derinine arama ve değerlendirme fonksiyonu. MAX. MIN. - Derine doğru ağaç oluşturmalı. Bu hare- keti seç. Her seviye için, en son uç düğüm. / yaprağa ulaşılınca, değerlendirme. fonksiyonu ile değer hesaplamalı Değerlendirme fonksiyonunu. yaymalı: - MIN’de minimum kabul ediliyor. - MAX’da maximum kabul ediliyor")
16
Minimax Algoritması – Örnek 2

17
Minimax Algoritması – Örnek 3

18
Minimax Algoritması – Örnek 4 (üç oyunculu bir örnek)
Bu örnekte, her oyuncu sadece kendisi için en iyiye (maksimum) bakıyor. Birisini dışarıda tutacak, vb. ittifak stratejileri de düşünülebilirdi.
 bakıyor. Birisini dışarıda tutacak, vb. ittifak stratejileri de düşünülebilirdi.")
19
Alpha-Beta (α-β) Budama
Tüm ağacın (yukarıdan aşağıya doğru derinine) oluşturulmasına ve değerlerin tüm ağaç boyu yayılmasına gerek kalmayabilir Edinilmiş bazı değerler ,ağacın üretilmemiş kısımlarının fazla olduğu ve üretilmesine gerek kalmadığı bilgisini verebilir
 oluşturulmasına ve değerlerin tüm ağaç boyu yayılmasına gerek kalmayabilir. Edinilmiş bazı değerler ,ağacın üretilmemiş kısımlarının fazla olduğu ve üretilmesine gerek kalmadığı bilgisini verebilir.")
20
Tüm durumları değerlendirmek gerekir mi? Basit bir α-β budama örneği:
≤1 Önemsiz, seçilecek yolu etkilemez α Bir durumun alabileceği maksimum değer β Bir durumun alabileceği minimum değer

21
α-β budama için Minimax değerinin bulunması
Temel fikir: oyun ağacında her bir düğüme bakmadan da doğru çözümü bulmak mümkündür. Böylece ağacın bakılmayan kısmı budanmış oluyor. Minimax Değer(kök)= max(min(3,12,8),min(2,x,y),min(14,5,2)) =max(3,min(2,x,y),2) =max(3,z,2 ) ; z=min(2,x,y) kabul ettik . Buradan z<=2 olduğu anlaşılıyor. O zaman Minimax Değer(kök)= 3 alırız
= max(min(3,12,8),min(2,x,y),min(14,5,2)) =max(3,min(2,x,y),2) =max(3,z,2 ) ; z=min(2,x,y) kabul ettik . Buradan z<=2 olduğu anlaşılıyor. O zaman Minimax Değer(kök)= 3 alırız.")
22
α-β Budama örneği - 1

23
α-β Budama örneği - 1

24
α-β Budama örneği - 1

25
α-β Budama örneği - 1

26
α-β Budama örneği - 1

27
α-β Budama örneği - 1 Alpha'ya -∞, Beta'ya +∞ ilk değerlerini ata.
Derinine arama (Depth first) ile ilk yaprağa (uç düğüme) kadar in. Eğer α ≥ β, o zaman o düğümün altında kalanları buda.
 ile ilk yaprağa (uç düğüme) kadar in. Eğer α ≥ β, o zaman o düğümün altında kalanları buda.")
28
α-β Budama örneği - 1 İlk yaprağı değerlendir ve buna göre [alfa, beta] değerlerini güncelle. 3.adım 2.adım 1.adım
![α-β Budama örneği - 1 İlk yaprağı değerlendir ve buna göre [alfa, beta] değerlerini güncelle. 3.adım.](http://slideplayer.biz.tr/slide/10365369/33/images/28/%CE%B1-%CE%B2+Budama+%C3%B6rne%C4%9Fi+-+1+%C4%B0lk+yapra%C4%9F%C4%B1+de%C4%9Ferlendir+ve+buna+g%C3%B6re+%5Balfa%2C+beta%5D+de%C4%9Ferlerini+g%C3%BCncelle.+3.ad%C4%B1m..jpg "2.adım. 1.adım.")
29
α-β Budama örneği - 1 İkinci yaprağı değerlendir ve buna göre alfa, beta değerlerini güncelle. 3.adım 2.adım 1.adım 4.adım

30
α-β Budama örneği - 1 Üçüncü yaprağı değerlendir ve buna göre alfa, beta değerlerini güncelle. 3.adım 2.adım 5.adım 1.adım 4.adım

31
α-β Budama örneği - 1 Dördüncü yaprağı değerlendir ve buna göre alfa, beta değerlerini güncelle. 3.adım 2.adım [3,2] 7.adım 1.adım 4.adım 5.adım 6.adım 7.adım: En küçük değer 3, altıncının en büyük değeri 2, o halde X ile işaretlilerin değerlerini bulmaya gerek yok, zaten alfa ve beta yı değiştiremezler.

32
α-β Budama için Başka bir Örnek

33
α-β Budama' nın Özellikleri
Budama, sonucu etkilemez Hareketlerin iyi sıralanması budamanın etkinliğini yükseltir “mükemmel sıralamada," zaman karmaşıklığı = O(bm/2)
")
34
Neden α-β Budama? Eğer V α’dan kötü ise Max onu iptal edecek
α, Max için yol boyunca seçilmiş en iyi (en yüksek) değer Eğer V α’dan kötü ise Max onu iptal edecek uygun dal budanacak Min için β, benzer yolla değerlendirilir
 değer. Eğer V α’dan kötü ise Max onu iptal edecek. uygun dal budanacak. Min için β, benzer yolla değerlendirilir.")
35
α-β Budama Algoritması

36
α-β Budama Algoritması

37
α-β Budama Örnekleri (Internet – video kaydı ile anlatım)
(26dk 25.sn. den itibaren)
")
38
Başka bir α-β Budama örneği
5,+∞ -∞,4 -∞,2 6,+∞

39
Alpha-Beta Budama İlkeleri
Derinine, soldan sağa ağacı üretip büyütmeli Son düğümlerin (yaprak / uç) değerlerini ebeveyn (parent) düğümleri için başlangıç tahminler kabul etmeli. MIN MAX 2 2 MIN değer (1), ebeveyn (2) MAX değerinden küçüktür 1 MIN değer daha ileride küçülebilir 2 =2 1 5 MAX değerin yalnız büyümesine izin veriliyor Bu düğümden aşağı düğümlere bakmamalı
 değerlerini ebeveyn (parent) düğümleri için başlangıç tahminler kabul etmeli. MIN. MAX. 2. 2. MIN değer (1), ebeveyn (2) MAX değerinden küçüktür. 1. MIN değer daha ileride. küçülebilir. 2. =2. 1. 5. MAX değerin yalnız büyümesine. izin veriliyor. Bu düğümden aşağı düğümlere. bakmamalı.")
40
Alpha-Beta Budama İlkeleri
- MAX düğümlerde (geçici) değerler ALPHA değerlerdir - MIN düğümlerde (geçici) değerler BETA değerlerdir MIN MAX 2 2 5 =2 2 1 1 Alpha-değer Beta-değer
 değerler ALPHA değerlerdir. - MIN düğümlerde (geçici) değerler BETA değerlerdir. MIN. MAX. 2. 2. 5. =2. 2. 1. 1. Alpha-değer. Beta-değer.")
41
Alpha-Beta Budama İlkeleri
Eğer Alpha-değer çocuk düğümün Beta-değerinden büyük veya ona eşitse: Uygun soydan düğümlerin üretimini dayandırmalı MIN MAX 2 2 5 =2 2 1 1 Alpha-değer Beta-değer

42
Alpha-Beta Budama İlkeleri
Eğer Beta-değer, çocuk düğümün Alpha-değerinden küçük veya ona eşitse: Uygun soy üzerindeki düğümlerin üretimini durdurmalı MIN MAX 2 2 6 =2 2 3 1 Alpha-değer Beta-değer 1

43
Mini-Max ve 4 5 8 5 3 1 8 2 1 3 2 4 3
7 3 9 1 6 2 4 5 4 16 5 31 39 = 5 MAX 6 8 5 23 15 = 4 30 = 5 3 38 MIN 33 1 2 8 10 2 18 1 25 3 35 2 12 4 20 3 5 = 8 8 9 27 9 29 6 37 = 3 14 = 4 22 = 5 MAX 1 3 4 7 9 11 13 17 19 21 24 26 28 32 34 36 Budama ile 11 adet değerlendirme / düğüm kontrolünün yapılmasına gerek kalmadı!

44
Kazanç: En İyi (optimal) Olası Durum
Eğer her düzeyde en iyi düğüm, en soldaki düğüm ise MAX MIN Yalnızca kalın doğrular incelenmeli

45
Mini-Max ve Budama için İdeal sıralanmış ağaç örneği
21
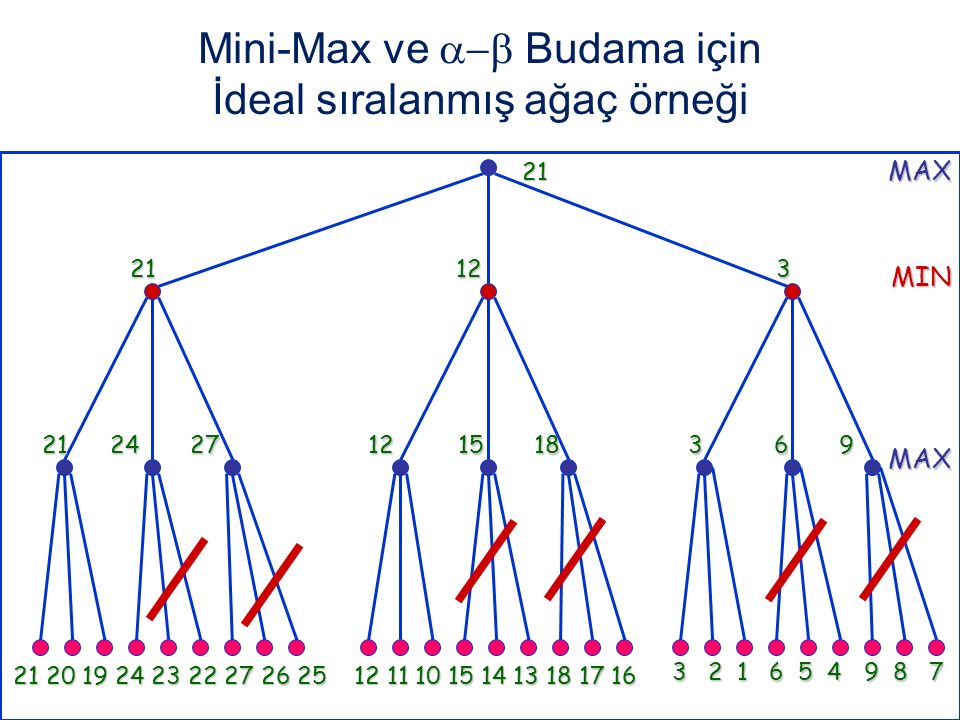
46
α-β Özellikleri Budama seçilen hareketi etkilemez.
Karmaşıklığı O(bm/2) ‘ye kadar düşürebilir. arama derinliğini iki katına çıkarır. 4*2=8 (satrançta master seviyesi)
 ‘ye kadar düşürebilir. arama derinliğini iki katına çıkarır. 4*2=8 (satrançta master seviyesi)")
47
Değerlendirme Fonksiyonları
Ağırlıklı doğrusal fonksiyon Eval(s) = w1 f1(s) + w2 f2(s) + … + wn fn(s) w-özelliğin ağırlığı f-özellik Örnek: satrançta f(s) = aynı türden taşların sayısı w-uygun taşın ağırlığı (örn., piyon için 1)
 = w1 f1(s) + w2 f2(s) + … + wn fn(s) w-özelliğin ağırlığı. f-özellik. Örnek: satrançta. f(s) = aynı türden taşların sayısı. w-uygun taşın ağırlığı (örn., piyon için 1)")
48
Satranç için değerlendirme fonksiyonu
Taş değerleri: Piyon=1, at=fil=3, kale=5, vezir=9 Siyahlar: 5 piyon, 1 fil, 2 kale Skor = 1*(5)+3*(1)+5*(2) = = 18 Beyazlar: 5 piyon, 1 kale Skor = 1*(5)+5*(1) = = 10 Bu durumun iki taraf için skorları: siyahlar için = = 8 beyazlar için = = -8
+3*(1)+5*(2) = = 18. Beyazlar: 5 piyon, 1 kale. Skor = 1*(5)+5*(1) = = 10. Bu durumun iki taraf için skorları: siyahlar için = = 8. beyazlar için = = -8.")
49
Değerlendirme fonksiyonları
Oyunun sonucunun çok derinlerde olduğu durumlarda durumların değerlendirilmesi için kullanılan fonksiyonlardır. Satranç için bu fonksiyon genellikle önceden belirlenen özniteliklerin doğrusal toplamı olarak düşünülür. Eval(s) = w1 f1(s) + w2 f2(s) + … + wn fn(s) Örnek, w1 = 9 ve f1(s) = (beyaz vezir sayısı) – (siyah vezir sayısı), vs. Ağırlıklı toplam, bileşenlerin birbirinden bağımsız olduğunu varsayar.
 = w1 f1(s) + w2 f2(s) + … + wn fn(s) Örnek, w1 = 9 ve. f1(s) = (beyaz vezir sayısı) – (siyah vezir sayısı), vs. Ağırlıklı toplam, bileşenlerin birbirinden bağımsız olduğunu varsayar.")
50
Satranç için değerlendirme fonksiyonu
Asıl iş: f’leri ve w’leri belirlemek: Etrafı boş olan piyonlar kötüdür. Şahın korumaları var mı? Hareket becerin ne durumda? Tahtanın ortasının kontrolü sende mi? Oyun süresince w’ lerin değerleri değişir mi?

51
Tic-Tac-Toe için Değerlendirme fonksiyonu

52
Tic-Tac-Toe için Değerlendirme fonksiyonu
(ilk hamlemiz, 2 derinlikli arama)
")
53
Tic-Tac-Toe için Değerlendirme fonksiyonu
(2. hamlemiz, 2 derinlikli arama)
")
54
Sınırlamalar Örnek: arama için 100 saniyelik zaman tanınmıştır. Her saniyede 104 düğüm araştırılmalıdır her harekette 106 düğüm Yaklaşımlar: Kesme denemesi (cutoff test): Derinlik sınırı Değerlendirme fonksiyonları
: Derinlik sınırı. Değerlendirme fonksiyonları.")
55
Sınırlı Derinlikte ya da Kesmekle Arama (cutting off / cutoff search)
Aşağıdaki değerlerle çalışmak mümkün mü? bm = 106, b=35 m=4 Yalnız 4 hamle ileriyi görmek satranç oyuncusu için başarısızlıktır! 4 hamle ≈ acemi oyuncu 8 hamle ≈ tipik bir program, usta oyuncu 12 hamle ≈ Deep Blue, Kasparov

56
Sınırlı Derinlikte Arama (Cutoff search)
MinimaxCutoff MinimaxValue ile aynıdır. Terminal yerine Cutoff Kullanılır. Utility yerine Eval kullanılır. Satrançta yeterli mi? Hamle yapma süresi eğer 100 saniye ise ve 104 düğüm/saniye hızda inceleme yapabiliyorsak her hareket için 106 düğüm inceleyebiliriz. bm = 106 ile sınırlıysa b=35 ise m=4 olabilir. 4-katlı ileri-bakış (look-ahead) amatör bir satranç oyuncusu 4 kat (hamle) ileri bakan bir program en iyi olasılıkla amatör oyuncuları yenebilir. 4-kat ≈ amatör oyuncu - insan 8-kat ≈ master seviyesinde insan 12-kat ≈ Deep Blue, Kasparov Çözüm: Sınırlı derinlikte aramaya alfa beta budamayı eklemek
 amatör bir satranç oyuncusu. 4 kat (hamle) ileri bakan bir program en iyi olasılıkla amatör oyuncuları yenebilir. 4-kat ≈ amatör oyuncu - insan. 8-kat ≈ master seviyesinde insan. 12-kat ≈ Deep Blue, Kasparov. Çözüm: Sınırlı derinlikte aramaya alfa beta budamayı eklemek.")
57
Sınırlı Derinlikte Arama’da Ufuk Etkisi (Horizon Effect)
Aramayı farklı derinliklerde yapmanın etkisi: C2’deki beyaz kale a2’deki piyonu alır mı? 1 derinlik Bir piyon kazançta olduğundan alır. 2 derinlik Bir piyona bir kale değmez. Almaz. 3 derinlik Bir piyon + bir kaleye, bir kale değer. Alır. 4 derinlik bir piyon + bir kaleye, 2 kale değmez. Almaz.

58
Ufuk Etkisi Vezir kaybı Piyonun kaybı Vezirin kaybı Ufuk = Minimax derinliği Derinine ilerlemekle felaketi önleyemesek de, onu geciktirebiliriz Çözüm: sezgisel devam

59
Sezgisel Devam Strateji durumlarda çok önemli;
Örn. oyun taşının kaybı, piyonun vezire çevrilmesi, ... Arama, derinlik sınırının dışında da yapmalı! Derinlik sınırı

60
Şans oyunları Örnek: Tavla: Oyun ağacının biçimi:

61
Şans oyunlarında “Yarar”ın yayılması
C düğümü için yarar fonksiyonu: MAX s1 s2 s3 s4 d1 d2 d3 d4 d5 S(C,d3) C Min Di: zarın değeri P(di): Di’nin oluşma olasılığı S(C,Di): Di değerinde C’den ulaşılabilen durum Yarar(s): s’in değerlendirilmesi Beklenen_max( C ) =
 C. Min. Di: zarın değeri. P(di): Di’nin oluşma olasılığı. S(C,Di): Di değerinde C’den ulaşılabilen durum. Yarar(s): s’in değerlendirilmesi. Beklenen_max( C ) =")
62
Expectiminimax Bileşenleri
Terminal (Sonuç) düğümü min düğümü max düğümü Şans düğümü Şans düğümünde gelebilecek zar, kağıt, vs. gibi durumlar olasılıklarına göre dizilirler. Örnek: Tavlada atılan çift zar için 21 değişik durum (düğüm) oluşabilir. (6 aynı çift zar, 15 değişik çift zar), yani her seviye için 21 şans düğümü vardır.
 düğümü. min düğümü. max düğümü. Şans düğümü. Şans düğümünde gelebilecek zar, kağıt, vs. gibi durumlar olasılıklarına göre dizilirler. Örnek: Tavlada atılan çift zar için 21 değişik durum (düğüm) oluşabilir. (6 aynı çift zar, 15 değişik çift zar), yani her seviye için 21 şans düğümü vardır.")
63
Expectiminimax Benim yapabileceğim olası hamleler Karşı tarafın
atabileceği zarlar Karşı tarafın yapabileceği olası hamleler Benim atabileceğim zarlar Benim yapabileceğim olası hamleler

64
Expectiminimax EXPECTIMINIMAX(n) =
UTILITY(n) eğer n oyun sonu (terminal) durumu ise max ( Ardıl (n) ) eğer n MAX seviyesinde ise min ( Ardıl (n) ) eğer n MIN seviyesinde ise ∑ P(s) * Ardıl(s) eğer n şans düğümü ise
 eğer n oyun sonu (terminal) durumu ise. max ( Ardıl (n) ) eğer n MAX seviyesinde ise. min ( Ardıl (n) ) eğer n MIN seviyesinde ise. ∑ P(s) * Ardıl(s) eğer n şans düğümü ise.")
65
Expectiminimax Örnek Benim yapabileceğim olası hamleler Karşı tarafın
atabileceği zarlar Karşı tarafın yapabileceği olası hamleler Benim açımdan Durum skorları

66
Expectiminimax - Örnek

67
Expectiminimax – Örnek 2

68
Expectiminimax – Örnek 3
Soldaki ağaçta, Max için en iyi seçenek a1 yoludur. Sağdaki ağaçta, Max için en iyi seçenek a2 yoludur.

69
Expectiminimax özellikleri
Tam çözüm? Evet (eğer ağaç sınırlı ise) En iyi çözüm? Evet (şans faktörü göz önünde olmalı) Zaman karmaşıklığı? O(bmnm) Bellek karmaşıklığı? O(nmbm) (derinlemesine arama) n şans faktörünün dallanma sayısı Tavla için b ≈ 20, n = 21 tam çözüm şu anki koşullarda olanaksız gibi. Pratikte en fazla 3 seviye mümkün. ‘TDGammon’ adlı oyun 2 derinlikli arama yapar. Çok iyi bir değerlendirme fonksiyonu var. Sonuç: dünya şampiyonu
 En iyi çözüm Evet (şans faktörü göz önünde olmalı) Zaman karmaşıklığı O(bmnm) Bellek karmaşıklığı O(nmbm) (derinlemesine arama) n şans faktörünün dallanma sayısı. Tavla için b ≈ 20, n = 21 tam çözüm şu anki koşullarda olanaksız gibi. Pratikte en fazla 3 seviye mümkün. ‘TDGammon’ adlı oyun 2 derinlikli arama yapar. Çok iyi bir değerlendirme fonksiyonu var. Sonuç: dünya şampiyonu.")
70
Tahmin ve Öğrenme Bilgisayar kullanıcının hareket log’larını kaydedebilir. Kullanıcının bir sonraki hareketini bu log’lara göre tahmin edebilir. Tüm olasılıkları hesaba katmaya gerek kalmaz. Bu tahmine göre yapması en iyi hareketi yapabilir. Önceki hareketler Low Kick, Low Punch, Uppercut % Low Kick, Low Punch, Low Punch % Low Kick, Low Punch, Low Kick % Şimdiki durum: Low Kick, Low Punch, ? Ör: Virtual Fighter 4

71
Değerlendirme fonksiyonunu öğrenmek
Deep Blue durum değerlendirme fonksiyonundaki ağırlıkları (w1, w2,.. ,wn) öğrenmiştir. f(p) = w1f1(p) + w2f2(p) wnfn(p) Nasıl?
 öğrenmiştir. f(p) = w1f1(p) + w2f2(p) wnfn(p) Nasıl")
72
Değerlendirme fonksiyonunu Öğrenmek
Grand master seviyesindeki oyuncuların 1000’den fazla oyunundaki her hamlenin yer aldığı “şu durumda şunu yaptı“ veri tabanı Tüm hamleler için, önceki durumdan gidilebilecek tüm durumların içinde yapılanın (veri tabanında yer alanın) seçileceği (f(p)’si büyük) şekilde w’ lerin düzenlenmesi
 seçileceği (f(p)’si büyük) şekilde w’ lerin düzenlenmesi.")
73
Rastgele olmayan oyun uygulamaları
Dama (Checkers): Chinook 1994’de dünya şampiyonu Marion Tinsley ile başabaş oynadı, aynı yıl Tinsley sağlık sebeplerinden oyunlardan çekildi ve Chinook o zamandan beri dünya şampiyonu. Günümüzde dama yapay zeka ve oyun algoritmaları ile tamamen çözülmüş durumdadır. Satranç: Deep Blue 1997’de 6 oyun sonunda dünya satranç şampiyonu Garry Kasparov’u yendi. Deep Blue saniyede 200 milyon düğümü arayabilmekte, oldukça iyi bir değerlendirme fonksiyonu kullanmakta, gerektiğinde 40-kat hamle ileriyi görebilecek derecede arama yapabilmektedir.
: Chinook 1994’de dünya şampiyonu Marion Tinsley ile başabaş oynadı, aynı yıl Tinsley sağlık sebeplerinden oyunlardan çekildi ve Chinook o zamandan beri dünya şampiyonu. Günümüzde dama yapay zeka ve oyun algoritmaları ile tamamen çözülmüş durumdadır. Satranç: Deep Blue 1997’de 6 oyun sonunda dünya satranç şampiyonu Garry Kasparov’u yendi. Deep Blue saniyede 200 milyon düğümü arayabilmekte, oldukça iyi bir değerlendirme fonksiyonu kullanmakta, gerektiğinde 40-kat hamle ileriyi görebilecek derecede arama yapabilmektedir.")
74
Rastgele olmayan oyun uygulamaları
Othello (reversi): Günümüzde insan dünya şampiyonları bilgisayarlara karşı yarışamamaktadır, bilgisayarlar bu alanda çok üstündür.
: Günümüzde insan dünya şampiyonları bilgisayarlara karşı yarışamamaktadır, bilgisayarlar bu alanda çok üstündür.")
75
Rastgele olmayan oyun uygulamaları
Go: İnsanlar 2015 yılına kadar halen üstünlüklerini korumaktaydı. Bunun nedeni, 19x19’luk oyun tahtasında b=361 olmasıdır. Arama teknikleri yerine örüntü tanıma teknikleri daha yaygın kullanılmaktadır. İlk olarak, Ağustos 2008’de her biri 32 işlemciye sahip 25 sunucuda çalışan Mygo profesyonel bir go oyuncusunu yendi. Ama dahası da oldu! Ekim 2015, Şubat 2016…Google DeepMind

76
Bilgisayarla satranç oynamak
Newell ve Simon: 10 yıl içinde dünya satranç şampiyonunun bir bilgisayar olacak 1958 : Satranç oynayan ilk bilgisayar IBM 704 1967 : Mac Hack programı insanların katıldığı bir turnuva da başarıyla yarıştı 1983 : Belle programı, Amerika Satranç Federasyonundan master ünvanını aldı. 1980’lerin ortaları : Carnegie Mellon üniversitesinde bilim adamları sonradan Deep Blue’ya dönüşecek çalışmayı başlattı. 1989: Projeyi IBM devraldı.

77
Bilgisayarla satranç oynamak
11 Mayıs 1997, Gary Kasparov, 6 oyunluk maçta Deep Blue’ya 3.5 a 2.5 yenildi. 2 oyun deep blue, 1 oyun Kasparov aldı, 3 oyun berabere

78
Yöntemlerin Gelişimi ve Kullanımı
Shannon, Turing Minimax arama 1950 Kotok/McCarthy Alpha-beta budama 1966 MacHack Dönüşüm tabloları 1967 Chess 3.0+ Iterative-deepening 1975 Belle Özel donanım 1978 Cray Blitz Paralel arama 1983 Hitech Paralel değerlendirme 1985 Deep Blue yukarıdakilerin hepsi 1997

79
Satranç ustası İnsan ve Deep Blue arasındaki farklar:
Deep Blue saniyede 200,000,000 ‘in üzerinde pozisyonu inceleyebilir ve değerlendirebilir. Bir usta ise saniyede 3 pozisyon değerlendirebilir. Deep Blue’ nun bilgisi azdır, ama hesaplama yeteneği çok yüksektir. Ustanın çok büyük satranç bilgisi vardır, ama hesaplama yeteneği sınırlıdır. İnsan satranç oynadığı zaman duyumundan, önsezisinden yararlanıyor. Deep Blue’ nun duyma, sezme yeteneği yoktu. Deep Blue, bir uluslararası büyük usta ve beş IBM araştırmacı bilim İnsanının rehberliğinden faydalanmıştır (1997 yılı). Bir ustaya ise antrenörü ve çok iyi satranç oynayabilme yeteneği yardım eder. İnsan kendi hatalarından ve başarılarından öğrenebilme yeteneğine sahiptir. Deep Blue ise, geliştirildiği dönemde öğrenme sistemi değildi; bu nedenle, rakibinden öğrenmek veya satranç tahtasındaki durumu “düşünmek” için yapay zeka kullanma yeteneğine sahip değildi.
. Bir ustaya ise antrenörü ve çok iyi satranç oynayabilme yeteneği yardım eder. İnsan kendi hatalarından ve başarılarından öğrenebilme yeteneğine sahiptir. Deep Blue ise, geliştirildiği dönemde öğrenme sistemi değildi; bu nedenle, rakibinden öğrenmek veya satranç tahtasındaki durumu düşünmek için yapay. zeka kullanma yeteneğine sahip değildi.")
80
Satranç ustası İnsan ve Deep Blue arasındaki farklar:
Programın korku duygusu, fikrinin dağıtılması endişesi yoktur (örneğin, Kasparov’un sabit bakışlarından). Bir ustanın ise insani zayıflıkları vardır, canı sıkılabilir, konsantrasyon dağılabilir vb. Programın oyun anlayışındaki değişimler ,geliştirme ekibi tarafından yapılmalıdır. Usta ise her oyundan önce, sonra, oyun içinde oyununda / taktiklerinde değişiklik yapabilir. İnsan, rakibini değerlendirerek onun zayıf yönlerini öğrenebilir ve bundan yararlanabilir. Program ise satranç pozisyonlarını çok iyi değerlendirse de rakibinin zayıf yönlerinden yararlanamaz. İnsan, değerlendirebildiği pozisyonlar içinden seçim yapar. Program ise mümkün pozisyonlar içinden en iyisini seçebilir. (Deep Blue, geliştirildiği ve sınandığı dönemde (1997 yılı) bile, saniyede 200 milyon pozisyon içinde arama yapabiliyordu)
. Bir ustanın ise insani zayıflıkları. vardır, canı sıkılabilir, konsantrasyon dağılabilir vb. Programın oyun anlayışındaki değişimler ,geliştirme ekibi tarafından. yapılmalıdır. Usta ise her oyundan önce, sonra, oyun içinde oyununda / taktiklerinde değişiklik yapabilir. İnsan, rakibini değerlendirerek onun zayıf yönlerini öğrenebilir ve bundan. yararlanabilir. Program ise satranç pozisyonlarını çok iyi değerlendirse de. rakibinin zayıf yönlerinden yararlanamaz. İnsan, değerlendirebildiği pozisyonlar içinden seçim yapar. Program ise. mümkün pozisyonlar içinden en iyisini seçebilir. (Deep Blue, geliştirildiği. ve sınandığı dönemde (1997 yılı) bile, saniyede 200 milyon pozisyon içinde. arama yapabiliyordu)")
81
Öte yandan… Drew McDermott (Prof. Dr., Computer Science, Yale University, AI expert) : ‘Deep Blue’nun gerçekte satrançtan anlamadığını söylemek, bir uçağın kanatlarını çırpmadığı için uçmadığını söylemeye benzer.’ Uzaylılar dünyaya gelse ve bize satrançta meydan okusalar; Yarışmaya Deep Blue’u mu, Kasparov’u mu gönderirdiniz…?

82
İçinde şans faktörü olan oyunlar
Tavla – atılan zarlara göre oyun oynanır. Kağıt oyunları – kağıtların dağılımına göre oyun oynanır. Oyun ağacını oluşturmak için her türlü varyasyonun göz önüne alınması gerekir.

85
Özet Oyunlar zevklidir.
Yapay Zeka hakkında pratik yeni fikirler üretirler. Hesaplama karmaşıklığı sebebiyle mükemmellik sağlanamayabilir. Bunun yerine yaklaşımlar, kestirimler kullanılır.

Benzer bir sunumlar