Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
Konuşma dosyaları üzerinde yapılabilecekler hakkında bir çalışma
Konuşma İşleme Konuşma dosyaları üzerinde yapılabilecekler hakkında bir çalışma

2
Giriş Rasgele istatistik sinyaller üzerinde yapılan işlemlerin konuşma sinyaline uygulanması Konuşma (speech), ses (audio) değildir fmax(konuşma) = 3.4 kHz fmax(ses) = 20 kHz Sinyal, hemen her zaman parçalara ayrılır ve işlemler stationary kabul edilen bu parçalar üzerinde yapılır
 = 3.4 kHz. fmax(ses) = 20 kHz. Sinyal, hemen her zaman parçalara ayrılır ve işlemler stationary kabul edilen bu parçalar üzerinde yapılır.")
3
Uygulamalar Bu doküman boyunca yapılacak uygulamalar aşağıdaki konuşma dosyası üzerinde olacaktır konusma.wav

4
Voiced vs. Unvoiced Konuşma, voiced (ötümlü) ve unvoiced (ötümsüz) olarak ikiye ayrılır Voiced, yüksek seslere; unvoiced, kısık seslere ya da gürültüye karşılık gelir Stationary kabul edilen parçaların voiced/unvoiced olarak sınıflandırılması yapılacak diğer işlemler için önemlidir Sınıflandırma: Sinyalin enerjisi Normalize otokorelasyon katsayıları Sıfır geçişleri

5
V/UV Classification – Enerji metodu
Sinyalin toplam enerjisi belli bir threshold değerinden yüksekse voiced olur. Burdaki m, alınan parçadaki sample sayısıdır

6
Uygulama Dokümanın en başında verilen konuşma dosyası
Matlab’ta açılacak Parçalara bölünecek Tüm parçaların enerjilerinin bir değerden yüksek olup olmadığına bakılacak İşlem tekrar kullanılabilir olması için bir fonksiyon olarak hazırlanacak

7
Uygulama function [ samples,vuv ] = vuv_energy( file_name )
%Verilen ses dosyasini voiced / unvoiced olarak siniflandirir % Fonksiyon oncelikle dosyayi acar ve 20 ms lik % parcalara boler. Eger dosya 20 ms olarak tam % bolunemiyorsa son 20 ms den kisa olan bolum % kullanilmaz. % % Daha sonra bolunen parcalarin enerjileri hesaplanir % enerjisi 1.5 ten az olan parcalar unvoiced kabul edilir [speech,fs,nbits] = wavread(file_name); window_ms = 20; threshold = 1.5; % alinacak parcalarin sample sayisi window = window_ms*fs/1000; % sinyal uzunlugu kontrolu speech = speech(1:(length(speech) - mod(length(speech),window)),1); samples = reshape(speech,window,length(speech)/window); energies = sqrt(sum(samples.*samples))'; vuv = energies > threshold;
![Uygulama function [ samples,vuv ] = vuv_energy( file_name )](http://slideplayer.biz.tr/slide/2001869/8/images/7/Uygulama+function+%5B+samples%2Cvuv+%5D+%3D+vuv_energy%28+file_name+%29.jpg "%Verilen ses dosyasini voiced / unvoiced olarak siniflandirir. % Fonksiyon oncelikle dosyayi acar ve 20 ms lik. % parcalara boler. Eger dosya 20 ms olarak tam. % bolunemiyorsa son 20 ms den kisa olan bolum. % kullanilmaz. % % Daha sonra bolunen parcalarin enerjileri hesaplanir. % enerjisi 1.5 ten az olan parcalar unvoiced kabul edilir. [speech,fs,nbits] = wavread(file_name); window_ms = 20; threshold = 1.5; % alinacak parcalarin sample sayisi. window = window_ms*fs/1000; % sinyal uzunlugu kontrolu. speech = speech(1:(length(speech) - mod(length(speech),window)),1); samples = reshape(speech,window,length(speech)/window); energies = sqrt(sum(samples.*samples)) ; vuv = energies > threshold;")
8
Uygulama Konuşma sinyalinin uzunluğu 500ms 20ms lik toplam 25 parça
Kırmızı ile gösterilen voiced / unvoiced data noktaları kendinden sonra gelen 20ms konuşma parçasının voiced ya da unvoiced olduğunu gösterir

9
LPC Analizi Konuyla ilgili anahtar kelimeler
Linear Predictive Coding Linear Regression Time series analysis All-pole filtering Sistem kendi katsayılarını değiştirir Giriş sinyaline göre sistem değişir Sistem sinyali, önceki değerleriyle hesaplamaya çalışır

10
LPC Sistem s[n] : işlenen sinyal e[n] : hata sinyali
ai : LPC katsayıları Sistem, katsayılarını e[n]’nin enerjisini minimum yapacak şekilde ayarlar
![LPC Sistem s[n] : işlenen sinyal e[n] : hata sinyali](http://slideplayer.biz.tr/slide/2001869/8/images/10/LPC+Sistem+s%5Bn%5D+%3A+i%C5%9Flenen+sinyal+e%5Bn%5D+%3A+hata+sinyali.jpg "ai : LPC katsayıları. Sistem, katsayılarını e[n]’nin enerjisini minimum yapacak şekilde ayarlar.")
11
Uygulama - LPC Görülebilir sonuçlar elde edebilmek için voiced bir parça üzerinde LPC analiz ve sentez işlemleri yapılacak LPC sentez filtresinin genlik tepkesinin sinyalin genlik spektrumu ile olan ilgisi incelenecek. V/UV sınıflandırma için vuv_energy kullanılacak

12
Uygulama - LPC Bulunan voiced parçalardan ikincisi kullanılacak
vuv_energy’nin voiced olarak belirlediği ilk parçanın bir kısmı unvoiced olabilir Matlab LPC katsayılarını direk verir ama e[n] i direk vermez

13
Uygulama - LPC function [ sample, lpc_coef, e ] = lpc_a( file_name, predictor ) %Basit lpc analizi % Verilen dosya icindeki voiced parcalar bulunur % Ikinci voiced parcanin lpc katsayilari ve bu lpc analizinin % hatasi hesaplanir [samples,vuv] = vuv_energy(file_name); % ikinci voiced pencere seçilir for i = 1:length(vuv) if i ~= 1 & vuv(i - 1) == 1 & vuv(i) == 1 sample = samples(1:length(samples),i); break end end %%%% lpc_coef = lpc(sample,predictor); e = filter(lpc_coef, 1, sample);
 %Basit lpc analizi % Verilen dosya icindeki voiced parcalar bulunur % Ikinci voiced parcanin lpc katsayilari ve bu lpc analizinin % hatasi hesaplanir [samples,vuv] = vuv_energy(file_name); % ikinci voiced pencere seçilir for i = 1:length(vuv) if i ~= 1 & vuv(i - 1) == 1 & vuv(i) == 1 sample = samples(1:length(samples),i); break end end %%%% lpc_coef = lpc(sample,predictor); e = filter(lpc_coef, 1, sample);")
14
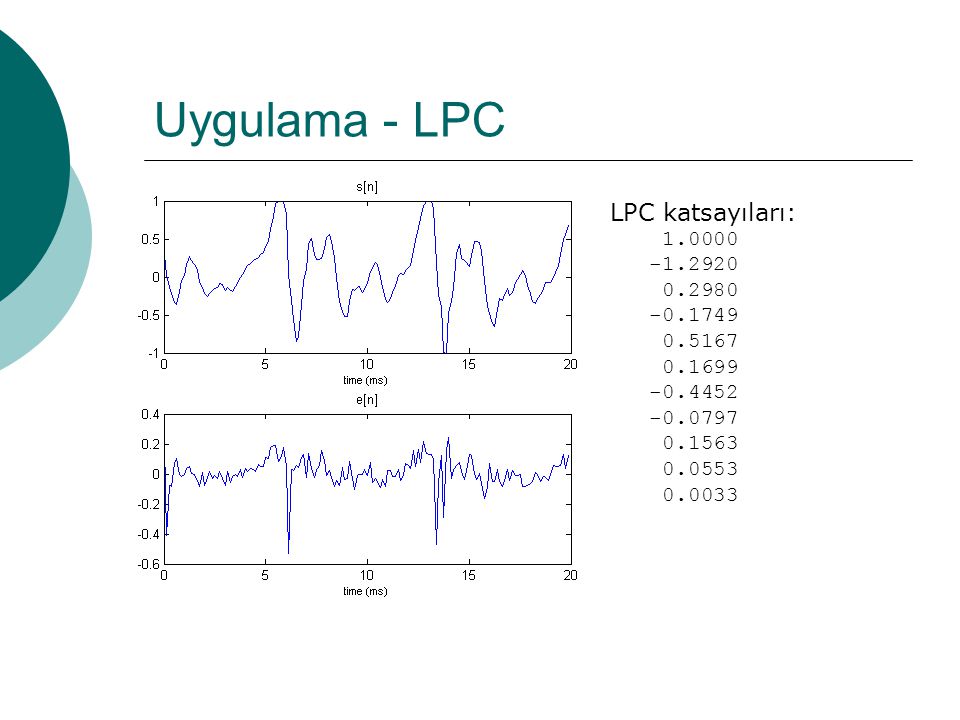
Uygulama - LPC LPC katsayıları: 1.0000 -1.2920 0.2980 -0.1749 0.5167
0.1699 0.1563 0.0553 0.0033
15
Uygulama - LPC Zaman bölgesi sinyallere bakarak denebilir
İletilmesi gereken veri miktarı ciddi miktarda azalmıştır LPC Analiz işlemi aynı zamanda bir sıkıştırma işlemidir denebilir

16
Uygulama - LPC Frekans bölgesi analiz
%sinyal parcasinin frekans spektrumu sample_f = fft(sample,1024); %1/A(z) filtresinin durtu tepkesi ir = filter(1,lpc_coef,[1 zeros(1:1023,1)]); %1/A(z) filtresinin frekans tepkesi fr = fft(ir); %genlik spektrumunun yarisi cizdirilir cunku diger yarisi %cizilen yarinin simetrigidir semilogy(0:1/512:1-1/512,abs(sample_f(1:512))) hold; %genlik tepkesinin, sinyalin spekturumuna oturabilmesi %icin bir miktar yukseltilir plot(0:1/512:1-1/512,3*abs(fr(1:512)))
; %1/A(z) filtresinin durtu tepkesi ir = filter(1,lpc_coef,[1 zeros(1:1023,1)]); %1/A(z) filtresinin frekans tepkesi fr = fft(ir); %genlik spektrumunun yarisi cizdirilir cunku diger yarisi %cizilen yarinin simetrigidir semilogy(0:1/512:1-1/512,abs(sample_f(1:512))) hold; %genlik tepkesinin, sinyalin spekturumuna oturabilmesi %icin bir miktar yukseltilir plot(0:1/512:1-1/512,3*abs(fr(1:512)))")
17
Uygulama - LPC Mavi grafik sinyalin genlik spektrumu
Kırmızı grafik LPC Sentez (1/A(z)) filtresinin genlik tepkesi 1/A(z) filtresinin genlik tepkesinin tepe noktaları sinyalin formantlarıdır
) filtresinin genlik tepkesi. 1/A(z) filtresinin genlik tepkesinin tepe noktaları sinyalin formantlarıdır.")
18
LSF – LSP (Line Spectral Frequencies – Pairs)
LPC katsayıları özel bir işlemle LSF’lere dönüştürülür Bu sayede elde edilen LSP’ler 0-1 ya da 0-pi aralığında Pozitif Küçükten büyüğe ya da büyükten küçüğe sıralı İletimde kolaylık sağlar

19
LSF – LSP P(z) ve Q(z) polinomlarının kökleri LSF’leri verir Bu kökler
Birim çember üzerinde Interlaced (Birbiri içine girmiş) Buna karşılık 1/A(z) filtresinin kökleri Fazlasıyla dağınık Eğer otokorelasyon metoduyla hesaplanmışsa hepsi birim çember içinde
 Buna karşılık 1/A(z) filtresinin kökleri. Fazlasıyla dağınık. Eğer otokorelasyon metoduyla hesaplanmışsa hepsi birim çember içinde.")
20
1/A(z) kökleri poles = roots(lpc_coef); zplane([],poles);
![1/A(z) kökleri poles = roots(lpc_coef); zplane([],poles);](http://slideplayer.biz.tr/slide/2001869/8/images/20/1%2FA%28z%29+k%C3%B6kleri+poles+%3D+roots%28lpc_coef%29%3B+zplane%28%5B%5D%2Cpoles%29%3B.jpg "1/A(z) kökleri poles = roots(lpc_coef); zplane([],poles);")
21
Uygulama – LSF % P(z) katsayilari p = [1,lpc_coef(2:end) + fliplr(lpc_coef(2:end)),1]; poles_P = roots(p); zplane([],poles_P); hold; % Q(z) katsayilari q = [1,lpc_coef(2:end) - fliplr(lpc_coef(2:end)),-1]; poles_Q = roots(q); zplane([],poles_Q);
![Uygulama – LSF % P(z) katsayilari p = [1,lpc_coef(2:end) + fliplr(lpc_coef(2:end)),1]; poles_P = roots(p);](http://slideplayer.biz.tr/slide/2001869/8/images/21/Uygulama+%E2%80%93+LSF+%25+P%28z%29+katsayilari+p+%3D+%5B1%2Clpc_coef%282%3Aend%29+%2B+fliplr%28lpc_coef%282%3Aend%29%29%2C1%5D%3B+poles_P+%3D+roots%28p%29%3B.jpg "zplane([],poles_P); hold; % Q(z) katsayilari. q = [1,lpc_coef(2:end) - fliplr(lpc_coef(2:end)),-1]; poles_Q = roots(q); zplane([],poles_Q);")
22
Uygulama – LSF 0 ve 1 de işe yaramayan birer kök var
Bunlardan kurtulmak için P(z) ve Q(z) polinomlarını modifiye etmek gerekir
 ve Q(z) polinomlarını modifiye etmek gerekir.")
23
Uygulama – LSF 0 ve 1 deki kökler çizdirme esnasında kullanılmadı

24
LSF – LSP P(z) polinomunun köklerinin gösterdiği frekanslar formantlardır Q(z) polinomunun kökleri ise sinyalin genlik spektrumunun zarfının çizilmesini sağlar
 polinomunun kökleri ise sinyalin genlik spektrumunun zarfının çizilmesini sağlar.")
25
Uygulama – LSF Sinyalin kendi genlik spektrumunun çizilmesi grafiği fazla karmaşıklaştırdığından sadece zarfı çizildi

26
Hidden Markov Model Deterministik bir olayı stokastik bir şekilde modelleme Modellenecek sistemin bir Markov chain olduğunu kabul ederek izlenebilir parametrelerden gizli parametrelerin hesaplanması

27
HMM - Örnek x: gizli durumlar y: izlenebilir çıktılar
a: geçiş olasılıkları b: çıktı olasılıkları

28
HMM Kullanım Alanları Pattern Recognition Bioinformatics
Hand-written Word Recognition Adaptive Power Management Speech Recognition …

29
HMM - Ergodic Durumların her birinden tüm durumlara geçiş mümkün

30
HMM - LTR Durum geçişleri soldan sağa yönde, ters yönde geçiş yok

31
HMM Markov Chain A = [aij] : state transition matrix Durumdan duruma geçme olasılığı Π = πi : initial probabilities Başlangıç durumu olasılıkları B = [bjot] = [bjk] : observation probability matrix j durumunda k çıktısının olma olasılığı
![HMM Markov Chain. A = [aij] : state transition matrix Durumdan duruma geçme olasılığı. Π = πi : initial probabilities Başlangıç durumu olasılıkları.](http://slideplayer.biz.tr/slide/2001869/8/images/31/HMM+Markov+Chain.+A+%3D+%5Baij%5D+%3A+state+transition+matrix+Durumdan+duruma+ge%C3%A7me+olas%C4%B1l%C4%B1%C4%9F%C4%B1.+%CE%A0+%3D+%CF%80i+%3A+initial+probabilities+Ba%C5%9Flang%C4%B1%C3%A7+durumu+olas%C4%B1l%C4%B1klar%C4%B1..jpg "B = [bjot] = [bjk] : observation probability matrix j durumunda k çıktısının olma olasılığı.")
32
HMM - aij = (# of states) X (# of states) a11 a12 a13 a14 a15 a16 a21
0.3 0.5 0.2 0.4 0.7 0.1 1.0 = (# of states) X (# of states)
 X (# of states)")
33
HMM - πi π1 π2 π3 π4 π5 π6 0.5 Durum sayısı uzunluğunda bir vektör

34
HMM - bjk Durum sayısı X Görülebilecek çıktı sayısı b11 b21 b31 b41
… b1M b2M b3M b4M b5M b6M (# of states) X (# of outputs) Durum sayısı X Görülebilecek çıktı sayısı
 X (# of outputs) Durum sayısı X Görülebilecek çıktı sayısı.")
35
HMM - Örnek 6 kutu içinde çeşitli renk toplar var
10 farklı renk var her kutuda her renkten eşit olmayan sayıda top var Başlangıç kutusunu belirlemek için yazı-tura atılıyor (Yazı :1 Tura: 2) 50 kere Zar atılıp bir kutu seçiliyor Seçilen kutudan rasgele bir top alınıyor Rengi kaydedilip top yerine konuyor
 50 kere. Zar atılıp bir kutu seçiliyor. Seçilen kutudan rasgele bir top alınıyor. Rengi kaydedilip top yerine konuyor.")
36
HMM Çıktılara bakarak topların hangi kutulardan çekildiğinin bulunması
Her bir çıktı için olasılıkların hesaplanması Baum-Welch gibi bir beklenti artırma (expectation maximization) algoritması kullanımı
 algoritması kullanımı.")
37
HMM – Baum Welch Bir HMM’in parametrelerinin (A,B) HMM: ise
maximum-likelihood tahminleri maximum a posteriori tahminleri HMM: ise Baum-Welch, verilen çıktıların olma olasılığını maksimize eden HMM’i bulur

38
HMM – Baum Welch Algoritma verilen başlangıç olasılığı ile başlatılır
t zamanında j durumunda olan, O1, O2, … Ot çıktı sırasının olasılığını hesaplar (forward probabilities)
")
39
HMM – Baum Welch Çıktı sırasının oluşmasının olasılığı bu değerlerin toplanmasıyla bulunabilir Bu olasılığa Baum-Welch olasılığı denir O çıktısının izlenme olasılığı, mümkün tüm durum sıraları üzerinden toplanmış olur

40
HMM – Viterbi Çıktıyı oluşturmuş olabilecek maksimum olasılıklı durum sırasını verir Baum-Welch toplama işlemi yaparken Viterbi maksimumunu alır PV genelde PBW den küçüktür PBW nin PV ye eşit olması sadece tek bir durum sırası mümkün olduğunda olur

41
HMM – Viterbi En olası durum sırasını hesaplamak da mümkündür
t zamanında s1 durumundayken t-1 zamanındaki en olası durumu kaydetmekle yapılır Bu değerler tüm j ler için hesaplandıktan sonra en olası durum sırası data üzerinde geri giderek bulunur

42
HMM – Örnek 3 vazo, R G B toplar O = RGGBRB П(j) = {0.8, 0.2, 0.0}
b1(G) = 0.5 b2(G) = 0.4 b3(R) = 0.1 b1(B) = 0.2 b2(B) = 0.5 b3(R) = 0.5 П(j) = {0.8, 0.2, 0.0}
 = 0.5. b2(G) = 0.4. b3(R) = 0.1. b1(B) = 0.2. b2(B) = 0.5. b3(R) = 0.5. П(j) = {0.8, 0.2, 0.0}")
43
HMM – Örnek function [ alfa, phi, mu ] = hmm( A, B, I, O )
alfa = zeros(length(O),length(I)); for i = 1:length(O) for j = 1:length(I) if i == 1 alfa(1,j) = I(j)*B(1,j); continue end for k = 1:length(I) alfa(i,j) = alfa(i,j) + alfa(i-1,k)*A(k,j); alfa(i,j) = alfa(i,j)* B(O(i),j);
![HMM – Örnek function [ alfa, phi, mu ] = hmm( A, B, I, O )](http://slideplayer.biz.tr/slide/2001869/8/images/43/HMM+%E2%80%93+%C3%96rnek+function+%5B+alfa%2C+phi%2C+mu+%5D+%3D+hmm%28+A%2C+B%2C+I%2C+O+%29.jpg "alfa = zeros(length(O),length(I)); for i = 1:length(O) for j = 1:length(I) if i == 1. alfa(1,j) = I(j)*B(1,j); continue. end. for k = 1:length(I) alfa(i,j) = alfa(i,j) + alfa(i-1,k)*A(k,j); alfa(i,j) = alfa(i,j)* B(O(i),j);")
44
HMM – Örnek 1 2 3 4 5 6

45
HMM – Örnek function [ alfa, phi, mu ] = hmm( A, B, I, O )
phi = zeros(length(O),length(I)); mu = zeros(length(O),length(I)); for i = 1:length(O) for j = 1:length(I) if i == 1 phi(1,j) = I(j)*B(1,j); continue end for k = 1:length(I) val = phi(i-1,k)*A(k,j); if val > phi(i,j) phi(i,j) = val; mu(i,j) = k; phi(i,j) = phi(i,j)* B(O(i),j);
![HMM – Örnek function [ alfa, phi, mu ] = hmm( A, B, I, O )](http://slideplayer.biz.tr/slide/2001869/8/images/45/HMM+%E2%80%93+%C3%96rnek+function+%5B+alfa%2C+phi%2C+mu+%5D+%3D+hmm%28+A%2C+B%2C+I%2C+O+%29.jpg "phi = zeros(length(O),length(I)); mu = zeros(length(O),length(I)); for i = 1:length(O) for j = 1:length(I) if i == 1. phi(1,j) = I(j)*B(1,j); continue. end. for k = 1:length(I) val = phi(i-1,k)*A(k,j); if val > phi(i,j) phi(i,j) = val; mu(i,j) = k; phi(i,j) = phi(i,j)* B(O(i),j);")
46
HMM – Örnek 1 2 3 4 5 6 1 2 3 4 5 6

47
HMM – Training Baum Welch
Algoritma rasgele bir değerle başlatılır t zamanında j durumunda olacak, O1, O2, … Ot çıktı sırasının olasılığını hesaplar (forward probabilities)
")
48
HMM – Training Baum Welch
t zamanında j durumunda olan modelin, Ot+1, … OT çıktı sırasıyla bitme olasılığını hesaplar (backward probabilities)
")
49
HMM – Training Baum Welch

50
HMM – Training Baum Welch
Hesaplanan değerlerle A, B ve П hesaplanır ve yerlerine konup işlem tekrar gerçekleştirilir

Benzer bir sunumlar








 27.03.2008.>")




 Sistemlerin Frekans Tepkileri>")


 Aşağıdaki şekillerden hangisi karedir? AB C D.>")


