Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
ANALİTİK YÖNTEM VALİDASYONU 4.ders

2
İstatistik ve Biyoistatistik
Üzerinde çalışılan bir konu ile ilgili elde edilen rakamsal verilerin doğru olarak toplanması, özetlenmesi ve sonuçların yorumlanması için yapılan bütün işlemler istatistik olarak tanımlanır. İstatistik çok geniş kapsamlı ve çok çeşitli metotları olan bir bilim dalıdır. İstatistiğin biyolojik ilimlere uygulanan şekline de biyoistatistik denir. İstatistiksel analiz, bir veri takımında zaten var olan bilgiyi açığa çıkarır, yeni bir bilgi yaratmaz. Bununla beraber, istatistik, verilerimize farklı bir yolla bakmamızı ve veri kalitesi ve yorumu ile ilgili objektif ve akıllı kararlar vermemizi de sağlar.

3
İlmi araştırmaların amacı, yapılan gözlem ve deneylerden genel sonuçlara ulaşmaktır. İstatistiksel metotlar ise her alandaki çalışmaların yardımcısıdır. Bu metotlar, yapılan bir çalışmadan elde edilen rakamsal verilere tatbik edilir ve bu metotlar sayesinde, araştırma sonuçları % 100 olmasa bile % 99 veya % 95 ihtimalle hükümlere bağlanabilir. Burada önemli olan bir konuda çalışılan örneklerin o popülasyonu temsil etmesidir.

4
İstatistiğin Önemi Araştırma sonuçlarıyla ilgili sayfalar dolusu veri ve bilgi yığını birkaç grafik ve tablo ile daha kısaca gösterilebilir. Araştırmaya başlamadan önce araştırmanın planlanmasında istatistik metotlarına göre uygun planlama yapılarak, daha bilimsel ve ekonomik bir çalışma gerçekleştirilebilir. İstatistiksel testler, araştırma sonuçlarının önemli olup olmadığı konusunda bir kriter oluşturur. Bu sayede bütün dünyada araştırma sonuçlarının değerlendirilmesinde ortak bir dil ortaya konmuştur. Bu metotlar olmasaydı, her bilim adamı kendine göre sonuçları önemli bulacaktı. Bu da sonuçların yorumlanmasında karmaşaya yol açacaktı. Bu yüzden araştırma sonuçları, istatistiksel metotlarla değerlendirilmelidir. Bu yüzden, bilimsel dergiler istatistikle değerlendirilmeyen araştırma sonuçlarını makale olarak yayınlamazlar.

5
Her araştırma için uygun istatistiksel metotlar vardır
Her araştırma için uygun istatistiksel metotlar vardır. Bunları seçip uygulamak gerekir. Bu uygulamayla bilimsel araştırmalar sonuçlanır ve bir anlam kazanır. Günümüzde bilgisayarlara verileri girildiğinde, hazır paket programlar (Excel, JMP, SPSS gibi) sayesinde kolayca ve kısa zamanda istatistiksel testler uygulanmaktadır. Bilgisayar zaman tasarrufu sağlar, ancak hangi istatistiksel testin uygulanacağı ve verilerin bilgisayara nasıl girileceğinin de bilinmesi gerekmektedir. Bilgisayarın verdiği sonuçların da değerlendirmesi gerekmektedir.
 sayesinde kolayca ve kısa zamanda istatistiksel testler uygulanmaktadır. Bilgisayar zaman tasarrufu sağlar, ancak hangi istatistiksel testin uygulanacağı ve verilerin bilgisayara nasıl girileceğinin de bilinmesi gerekmektedir. Bilgisayarın verdiği sonuçların da değerlendirmesi gerekmektedir.")
6
Bir Araştırmada Takip Edilecek Sıra Nasıl Olmalıdır?
Araştırma konusunun tespiti ve bununla ilgili literatürlerin toplanması, Araştırmanın planlanması, Deney ve ölçüm metotlarının araştırıcı tarafından bizzat öğrenilmesi, Araştırma planının uygulanması (gerekli deney ve ölçümlerin yapılarak verilerin elde edilmesi) Verilerin ortalamaları alınarak, tablo ve grafik halinde gösterilmesi (özetleme), Uygun istatistiksel metotların seçimi ve elde edilen verilere uygulanması, Araştırma sonuçlarının yorumu ve genelleme.
 Verilerin ortalamaları alınarak, tablo ve grafik halinde gösterilmesi (özetleme), Uygun istatistiksel metotların seçimi ve elde edilen verilere uygulanması, Araştırma sonuçlarının yorumu ve genelleme.")
7
Rastgele Hataların İstatistiksel Olarak Değerlendirilmesi
Rastgele hatalar, ölçüm sonuçlarının istatistiksel olarak incelenmesi ile değerlendirilir (ortalama, standart sapma, standart hata vb.). Aynı numune üzerinde ne kadar analitik ölçüm yapılırsa yapılsın, veriler üzerine rastgele dağılım şeklinde yansıyan rastgele veya belirsiz hatalar nedeniyle bir veri dağılımı elde edildiğini hatırlayalım. Ölçüm sayısı arttıkça, hata azaldığı için; çok fazla sayıda ölçüm yapıldığında ve nedeni belli olan hatalar en aza indirgendiğinde, işte bu rastlantı şeklinde hatalar da grafiğe geçirilerek, Gauss (çan) hata eğrisi şeklinde bir eğri elde edilir. İstatistiksel analize başlarken, analitik sonuçların bir Gauss dağılımı (normal dağılım) gösterdiğini varsayıyoruz. Elbette analitik veriler, Gauss tipine uymayan dağılımlar da gösterebilir. Fakat istatistiksel değerlendirmelerde, diğer dağılımların da Gauss dağılımına yakın olduğu varsayılır.
. Aynı numune üzerinde ne kadar analitik ölçüm yapılırsa yapılsın, veriler üzerine rastgele dağılım şeklinde yansıyan rastgele veya belirsiz hatalar nedeniyle bir veri dağılımı elde edildiğini hatırlayalım. Ölçüm sayısı arttıkça, hata azaldığı için; çok fazla sayıda ölçüm yapıldığında ve nedeni belli olan hatalar en aza indirgendiğinde, işte bu rastlantı şeklinde hatalar da grafiğe geçirilerek, Gauss (çan) hata eğrisi şeklinde bir eğri elde edilir. İstatistiksel analize başlarken, analitik sonuçların bir Gauss dağılımı (normal dağılım) gösterdiğini varsayıyoruz. Elbette analitik veriler, Gauss tipine uymayan dağılımlar da gösterebilir. Fakat istatistiksel değerlendirmelerde, diğer dağılımların da Gauss dağılımına yakın olduğu varsayılır.")
8
Deneysel verilerin dağılımı
Verilerin ortalamanın etrafında simetrik olarak dağılıp dağılmadığı, verinin nasıl ele alınacağını etkiler. Ortalama değer - % 50 + % 50 Simetrik veri Eğik veri (Gauss dağılımı) (Normal dağılım-çan eğrisi) Ortalama etrafında veriler simetrik dağılıyorsa Ortalama etrafında veriler simetrik dağılmıyorsa 8
 (Normal dağılım-çan eğrisi) Ortalama etrafında veriler simetrik dağılıyorsa. Ortalama etrafında veriler simetrik dağılmıyorsa. 8.")
9
Örneklem ve Popülasyon: Bilimsel bir çalışmada, hakkında bilgi edinmek istenilen varlıklar topluluğuna popülasyon (evren) denir. İstatistik analiz yaparken; popülasyon, alınabilecek bütün ölçümlerin tamamıdır. Popülasyondan seçilmiş tekillerin kümesine ise örneklem denir. Yani örneklem, analiz için seçilen popülasyonun alt kümesidir. Örnek olarak; yüz binlerce tablet üreten bir vitamin hapı üretim hattı düşünelim. Genelde kalite kontrol amacı ile, her bir tableti ayrı ayrı incelemek için zaman ve kaynak ayrılamaz. Dolayısıyla, istatistik örnekleme ilkelerine uyarak, analiz için seçilmiş tabletlerden oluşan bir örneklem (numune) alırız. Sonra bu örneklemi inceleyerek, popülasyonun nitelikleriyle ilgili bir yargı geliştiririz. İstatistik örneklem ile analitik numune yaklaşık eş anlamlıdır.
 alırız. Sonra bu örneklemi inceleyerek, popülasyonun nitelikleriyle ilgili bir yargı geliştiririz. İstatistik örneklem ile analitik numune yaklaşık eş anlamlıdır.")
10
Bağıl frekansın (sıklık) ortalamadan sapmanın bir fonksiyonu olarak grafiğe geçirilmesi ile elde edilen iki Gauss eğrisi şekilde görülmektedir. Bu gibi eğriler, popülasyon ortalaması (µ) ve popülasyon standart sapması (σ) adı verilen iki parametrenin fonksiyonu olarak gösterilebilir. Örneklem ortalaması ( ) ve örneklem standart sapması (s) da birer istatistiktir. Ancak bu istatistikler, µ ve σ parametrelerinin tahmini değerleridir. Normal hata eğrileri. B eğrisi için standart sapma, A eğrisinin iki katıdır yani σB = 2σA. Yatay eksen, ölçme birimi cinsinden ortalamadan sapmadır ve (x - µ) büyüklüğü, her bir x ölçümünün popülasyon ortalamasından sapmasıdır.
 ve popülasyon standart sapması (σ) adı verilen iki parametrenin fonksiyonu olarak gösterilebilir. Örneklem ortalaması ( ) ve örneklem standart sapması (s) da birer istatistiktir. Ancak bu istatistikler, µ ve σ parametrelerinin tahmini değerleridir. Normal hata eğrileri. B eğrisi için standart sapma, A eğrisinin iki katıdır yani σB = 2σA. Yatay eksen, ölçme birimi cinsinden ortalamadan sapmadır ve (x - µ) büyüklüğü, her bir x ölçümünün popülasyon ortalamasından sapmasıdır.")
11
İstatistikçiler, örneklem ortalaması ile popülasyon ortalaması arasında bir ayırım yapma gereği duymuşlardır. Örneklem ortalaması bir veri popülasyonu içinden seçilmiş sınırlı sayıda ölçmelerin aritmetik ortalamasıdır. Buradaki n, örneklem kümesindeki ölçme sayısıdır. Popülasyon ortalaması µ ise popülasyonun gerçek ortalamasıdır. Buradaki n de, popülasyondaki toplam ölçme sayısıdır. Hiçbir sistematik hata yoksa, popülasyon ortalaması, ölçülen büyüklüğün gerçek değeridir. Küçük örneklem verileri, sonsuz sayıdaki veriyi tam olarak temsil edemediği için, özellikle küçük n değerinde , µ’den genelde farklıdır X ve µ arasındaki olası fark, ölçme sayısı arttıkça hızla düşer, normal olarak n, 20-30’a ulaşınca bu fark ihmal edilebilir bir düzeye iner.

12
Ortalama değere bütün sonuçların katkısı vardır (n sayıda deney)
Ortalama değere bütün sonuçların katkısı vardır (n sayıda deney). n/2 sayısı ortalama değerden büyük, n/2 sayısı da ortalama değerden küçüktür (eğer sistematik bir hata yoksa). Dolayısıyla, + ve – değerlerin toplamı da sıfırdır. Bilindiği üzere, analiz sayısı arttıkça, ortalama değer doğru (gerçek) değere yaklaşır. Analiz sayısı sonsuz olunca da, doğru değer (µ, popülasyon ortalaması), ortalama değere eşit olur. Yani en çok elde edilen sonuç, veri takımının ortalaması olan bu µ değeridir. Elbette ki bu ortalamaya göre sonuçların dağılımı da simetriktir.
. n/2 sayısı ortalama değerden büyük, n/2 sayısı da ortalama değerden küçüktür (eğer sistematik bir hata yoksa). Dolayısıyla, + ve – değerlerin toplamı da sıfırdır. Bilindiği üzere, analiz sayısı arttıkça, ortalama değer doğru (gerçek) değere yaklaşır. Analiz sayısı sonsuz olunca da, doğru değer (µ, popülasyon ortalaması), ortalama değere eşit olur. Yani en çok elde edilen sonuç, veri takımının ortalaması olan bu µ değeridir. Elbette ki bu ortalamaya göre sonuçların dağılımı da simetriktir.")
13
Popülasyon standart sapması (σ): Çok sayıda veri popülasyonu kesinliğinin bir ölçüsü olan σ, aşağıdaki eşitlik ile verilir: Burada n, popülasyonu oluşturan tekrarlanan verilerin sayısıdır. Önceki şekilde, standart sapmaları farklı olan A ve B gibi, iki veri popülasyonu görülmektedir. Daha geniş fakat daha düşük B eğrisini veren veri takımı için standart sapma, A eğrisini veren ölçümlerin standart sapmasının iki katıdır. Bu eğrilerin genişliği, iki takım verinin kesinliğinin bir ölçüsüdür. Bu nedenle, A eğrisini oluşturan verilerin kesinliği, B eğrisinin temsil ettiği kesinlikten iki kat daha iyidir. Başka bir şekilde, yatay eksen aşağıdaki gibi yeni bir değişkenle gösterilerek, bir başka tip normal hata eğrisi elde edilmiştir. Burada birimsiz bir büyüklük olan z, standart sapma birimi cinsinden bir verinin ortalamadan sapmasıdır.

14
Bu normal hata eğrisinin birkaç genel özelliği vardır:
X-µ=σ olduğunda z, bir standart sapmaya eşit, X-µ=2σ olduğunda z, iki standart sapmaya eşit olup, benzer şekilde devam eder. Yani z, bir sonucun popülasyon ortalamasından sapmasının, standart sapmanın kaç katı olduğunu gösterir. Bağıl frekansın z’ye karşı grafiği, standart sapmanın büyüklüğüne bakılmaksızın bütün veriler için tek bir Gauss eğrisi verir. Bu normal hata eğrisinin birkaç genel özelliği vardır: a- Ortalama değer, maksimum frekansı gösteren orta noktadır. b- Pozitif ve negatif sapmalar maksimumun iki yanında simetrik bir dağılım gösterir. c- Sapmaların büyüklüğü arttıkça, frekansta üstel bir azalma görülür. Bu nedenle, küçük rastgele belirsizlikler çok büyük belirsizliklerden çok daha sık gözlenir. Elde edilen herhangi bir dağılım, bu formülle standart normal dağılıma dönüştürülür.

15
Örneklem standart sapması (s): Az sayıdaki verilere uygulanır ve önceki standart sapma eşitliği değişir. Burada popülasyon ortalaması µ yerine, örneklem ortalaması olan alınır. Ayrıca az sayıda ölçüm yapıldığı için, n yerine de n-1 (serbestlik derecesi sayısı) alınır. Burada elde edilen s, popülasyon standart sapması olan σ’nın, daha az tek yönlü sapma gösteren tahmini bir değeridir. Serbestlik derecesi sayısı: Bağımsız veri sayısını gösterir. Serbestlik derecesi, istatistiksel olarak deney sonuçlarındaki hatayı en aza indirgemek için kullanılır. Sistemdeki bilinmeyenlerin sayısıyla, yine aynı sistemi ifade eden denklem sayısının farkıdır. Ya da gözlem sayısından tahmin edilecek parametre sayısının çıkarılmasıyla elde edilen sayıdır (serbestçe seçilebilecek değişken sayısı da denilir). Bir veri takımının kesinliğinin bağımsız bir ölçümü, böylelikle n-1 sapma ile sağlanır.
 alınır. Burada elde edilen s, popülasyon standart sapması olan σ’nın, daha az tek yönlü sapma gösteren tahmini bir değeridir. Serbestlik derecesi sayısı: Bağımsız veri sayısını gösterir. Serbestlik derecesi, istatistiksel olarak deney sonuçlarındaki hatayı en aza indirgemek için kullanılır. Sistemdeki bilinmeyenlerin sayısıyla, yine aynı sistemi ifade eden denklem sayısının farkıdır. Ya da gözlem sayısından tahmin edilecek parametre sayısının çıkarılmasıyla elde edilen sayıdır (serbestçe seçilebilecek değişken sayısı da denilir). Bir veri takımının kesinliğinin bağımsız bir ölçümü, böylelikle n-1 sapma ile sağlanır.")
16
s’nın küçük olması metodun iyi ve analizcinin tecrübeli olduğunu gösterir. Standart sapmanın bağıl hatası, deney sayısı arttıkça azalır. Azalma, deney sayısı 10 civarına gelince iyice azalır ve olduğu zaman da yaklaşık olarak sabit kalır. s’nın bağıl hatası, % (bias) 10 20 30 40 50 Deney sayısı, n 16
 Deney sayısı, n. 16.")
17
Aynı doğrultuda olmak şartıyla küçük s veren bir teknik, büyük s verenden daha güvenilirdir. s ne kadar küçük ise veriler ortalama etrafında o kadar merkezlenmiştir denilir. Gauss eğrisinin en yüksek max. noktasının aritmetik ortalamayı verdiğini artık biliyoruz. Yani orada sıfır sapma vardır. Aritmetik ortalamanın, dağılımın orta noktasını gösteren ve dağılımı temsil eden bir ölçü olduğunu da biliyoruz. Ancak bu veri, dağılımın yaygınlığı hakkında bilgi vermez. Bu bilgiyi başka bir istatistiksel parametre verir. 47,1 s 94,2 s n büyüdükçe, X ve s, µ ve σ’ya yaklaşır. Yani, n → ∞ iken, X → µ ve s → σ’ya eşit olur. 17

18
Dağılımın yaygınlığı hakkında bilgi veren s (standart sapma) ve s’nin karesi (s2) yani örneklem varyansıdır. İstatistik hesaplarda s2 önemli bir parametredir. Bu değer, istatistik açısından önemli bir büyüklük olan popülasyon varyansı, σ2 için de tahmini bir değerdir. s, dağılımdaki her bir değerin ortalamaya göre ne kadar uzaklığı olduğunu, s2 ise dağılımın ne yaygınlıkta olduğunu veren bir ölçüdür. s’nin birimi, verilerinki ile aynı olduğu halde, varyansın biriminin, verilerin biriminin karesi olduğuna dikkat ediniz. Varyans, aslında iyi bir kesinlik ölçüsüdür. Fakat kimyacılar, bilimsel bir çalışma da, kesinliğin ölçüsü olarak s’yi s2’ye tercih eder. Çünkü, hesaplanmak istenen sonuç ve s aynı boyuttandır. Varyans ise (%)2 ile verilir. Yani, bir ölçümün kesinliğini ölçümün kendisi ile ilişkilendirmek, birimler aynı olunca daha da kolaydır. Oysa, varyansı kullanmanın üstünlüğü de, varyansların birçok durumda toplanabilir olmasındandır.
2 ile verilir. Yani, bir ölçümün kesinliğini ölçümün kendisi ile ilişkilendirmek, birimler aynı olunca daha da kolaydır. Oysa, varyansı kullanmanın üstünlüğü de, varyansların birçok durumda toplanabilir olmasındandır.")
19
Ortalamanın standart sapması (Ortalamanın standart hatası, Sm): Bir veri grubunun standart sapmasının gruptaki veri sayısının kareköküne bölümüdür. Sm, ortalamanın s’sı yani standart hatadır. Sm, s ile orantılı iken, ile ters orantılıdır. s’nin güvenirliği: n arttıkça, s’nin güvenirliğinin (yani σ’ya yakınlık derecesi) hızlı bir şekilde arttığını biliyoruz. n yaklaşık olarak 20’den daha büyük olduğunda, s ve σ’nın aynı olacağı da kabul edilebilir. s’nin güvenirliğini arttırmak için veri birleştirilmesi: Elde birden çok veri alt kümesi varsa, bir yerine birden çok veri alt kümesi kullanarak, popülasyon standart sapması, daha doğru olarak tahmin edilebilir. Her veri alt kümesi için bütün ölçmelerde rastgele hata kaynaklarının aynı olduğu varsayılır. Buradan, popülasyon standart sapmasının σ, tahmini değeri olan birleşik standart sapma (Sbirleşik) hesaplanır. Bu değer, tekil s değerlerinin ağırlıklı ortalamasıdır.
 hızlı bir şekilde arttığını biliyoruz. n yaklaşık olarak 20’den daha büyük olduğunda, s ve σ’nın aynı olacağı da kabul edilebilir. s’nin güvenirliğini arttırmak için veri birleştirilmesi: Elde birden çok veri alt kümesi varsa, bir yerine birden çok veri alt kümesi kullanarak, popülasyon standart sapması, daha doğru olarak tahmin edilebilir. Her veri alt kümesi için bütün ölçmelerde rastgele hata kaynaklarının aynı olduğu varsayılır. Buradan, popülasyon standart sapmasının σ, tahmini değeri olan birleşik standart sapma (Sbirleşik) hesaplanır. Bu değer, tekil s değerlerinin ağırlıklı ortalamasıdır.")
20
Sbirleşik hesaplamak için, her alt grubun ortalamadan sapmalarının kareleri alınır, sonra her alt grubun kareleri toplanır ve uygun serbestlik derecesi sayısına bölünür. Bölümün karekökü alınarak Sbirleşik elde edilir. Her alt grup için bir serbestlik derecesi kullanılmış demektir. Bu yüzden Sbirleşik için serbestlik derecesi sayısı, toplam ölçüm sayısından alt grup sayısının çıkarılması ile bulunur. Çok sayıda veri takımından birleşik standart sapmayı hesaplamak için kullanılan eşitlik:

21
ÖRNEK Şeker hastalarında glikoz seviyeleri rutin olarak ölçülüp kaydedilir. Glikoz düzeyi kısmen yüksek olan bir hastada glikoz derişimleri, farklı aylarda spektrofotometrik bir analitik yöntemle tayin edilmiştir. Glikoz düzeyini ayarlamak için diyete alınan bir hastada, diyetin etkinliğini belirlemek üzere aşağıdaki değerler bulunmuştur. Yöntem için birleşik standart sapmayı bulunuz. (Ortalama) 21
 21.")
23
Gauss Eğrisi Altında Kalan Alanlar
İki sınır değeri ile Gauss eğrisi altında kalan alan, ölçülen değerin bu iki sınır arasında bulunma olasılığını verir. Çok sayıda veri için, Gauss eğrisi altında kalan alanın %68,2’inin, ortalamadan 1 standart sapma (±σ)’lık aralıkta bulunduğu gösterilebilir. Yani verilerin %68,2’i bu sınırlar arasındadır. Ayrıca, bütün verilerin yaklaşık %95,6’ı ortalamaya göre ±2σ ve %99,7’si de ±3σ aralığındadır. Ayrıca, yapılan tek bir ölçmenin sonucunun ±2σ aralığına düşme olasılığı ise %95,6’dır.
’lık aralıkta bulunduğu gösterilebilir. Yani verilerin %68,2’i bu sınırlar arasındadır. Ayrıca, bütün verilerin yaklaşık %95,6’ı ortalamaya göre ±2σ ve %99,7’si de ±3σ aralığındadır. Ayrıca, yapılan tek bir ölçmenin sonucunun ±2σ aralığına düşme olasılığı ise %95,6’dır.")
24
Sıfır sapma, hiç hata yok
Eğri altında kalan alanın % 68,2’si ±1 % 95,6’sı ±2 % 99,7’si ±3 ile verilir. -1 +1 -2 +2 -3 +3 68,2 0,15 0,15 95,6 99,7 Eğer tek bir deney yapılmışsa; Bulunan sonuç % 68,2 ihtimalle, doğru değer X, µ’den en çok ±1 kadar uzakta Bulunan sonuç % 95,6 ihtimalle, doğru değer X, µ’den en çok ±2 kadar uzakta Bulunan sonuç % 99,7 ihtimalle, doğru değer X, µ’den en çok ±3 kadar uzakta Bulunan sonuç % 99,9 ihtimalle ise, doğru değer X, µ’den en çok ±3,29 kadar uzakta bulunur. 24

25
Güven aralıkları (±z) ve Güven sınırları (%)
Tekrarlanmış analitik sonuçlar setinin ortalaması merkez olmak üzere, popülasyon ortalamasının da belli bir yüzdede yer alması beklenen, sayısal bir aralık tanımlanmalıdır. Güven aralığı (GA) olarak bilinen bu aralık, ortalamanın standart sapması (s) ile ilişkilidir. Kimyasal analizlerde, pek çok sayıda ölçüm almadan gerçek ortalama (yani popülasyon ortalaması, µ) bulunamaz. Fakat istatistik kullanarak, sınırlı sayıda ölçümle elde edilen ortalama değer ( ) merkez olmak üzere, öyle bir aralık bulunabilir ki, popülasyon ortalamasının (µ) da belli bir olasılıkla bu aralıkta yer alması beklenir. Bu sınırlar güven sınırları (ya da güven seviyeleri), bu sınırların belirlediği aralık da güven aralığı olarak bilinir. Güven aralığı, güven sınırının büyüklüğüdür ve güven seviyesi genellikle %95 alınır. Örneğin; potasyum ölçümlerinden elde edilen bir veri takımı için popülasyon ortalamasının %99 olasılıkla %7,25±%0,15 K olduğu söylenebilir. Buna göre, ortalama değer, %99 olasılıkla %7,10 -%7,40 K aralığında yer almalıdır.
 olarak bilinen bu aralık, ortalamanın standart sapması (s) ile ilişkilidir. Kimyasal analizlerde, pek çok sayıda ölçüm almadan gerçek ortalama (yani popülasyon ortalaması, µ) bulunamaz. Fakat istatistik kullanarak, sınırlı sayıda ölçümle elde edilen ortalama değer ( ) merkez olmak üzere, öyle bir aralık bulunabilir ki, popülasyon ortalamasının (µ) da belli bir olasılıkla bu aralıkta yer alması beklenir. Bu sınırlar güven sınırları (ya da güven seviyeleri), bu sınırların belirlediği aralık da güven aralığı olarak bilinir. Güven aralığı, güven sınırının büyüklüğüdür ve güven seviyesi genellikle %95 alınır. Örneğin; potasyum ölçümlerinden elde edilen bir veri takımı için popülasyon ortalamasının %99 olasılıkla %7,25±%0,15 K olduğu söylenebilir. Buna göre, ortalama değer, %99 olasılıkla %7,10 -%7,40 K aralığında yer almalıdır.")
26
Güven aralığının büyüklüğü, s’yi ne kadar doğrulukla bildiğimize, yani standart sapmanın (s) gerçek standart sapmaya (σ) ne kadar yakın olduğuna bağlıdır. s, σ’ya yeterince yakın olduğu zaman, güven aralığı, s’nin sadece 2 veya 3 tekrara dayandığı durumdakinden önemli derecede daha dar olabilir. σ biliniyorken, ya da s’nin σ’ya yakın olduğu bilinen durumlarda güven aralığı: İstatistik bir değerlendirmede, güven sınırları % ve bu seviyelerdeki güven aralıkları, z olarak (yani σ, s cinsinden) verilir. Aşağıdaki şekildeki grafikte görüldüğü gibi; güven sınırları (yani, eğrinin altında kalan toplam alan yüzdeleri) yükseldikçe (%90, 95, 99 gibi) güven aralığı da (z, 0,67 1,28 1,64 1,96 2,58 gibi) genişler. Örneğin; herhangi bir Gauss eğrisinin altındaki alanın %50’si, – 0,67 σ ile + 0,67 σ arasında kalmaktadır.
 verilir. Aşağıdaki şekildeki grafikte görüldüğü gibi; güven sınırları (yani, eğrinin altında kalan toplam alan yüzdeleri) yükseldikçe (%90, 95, 99 gibi) güven aralığı da (z, 0,67 1,28 1,64 1,96 2,58 gibi) genişler. Örneğin; herhangi bir Gauss eğrisinin altındaki alanın %50’si, – 0,67 σ ile + 0,67 σ arasında kalmaktadır.")
27
Gauss eğrisi (normal hata eğrisi) altında kalan alanlar:
-z +z Güven seviyeleri (%) (sınırları) +0,67 б -0,67 б % 50 Bağıl frekans %80 +1,28 б Güven aralıkları -1,28 б -1,64 б %90 +1,64 б -1,96 б %95 +1,96 б %99 -2,58 б +2,58 б -4б -3б -2,5 б -2б -1б +1б 2б +2,5 б 3б 4б 5 б ±z değerleri Verilerin yaklaşık %99’u, normal hata eğrisinin altında ve yaklaşık ±2,5 σ aralığında bulunur. Buna göre, bir hata eğrisinde %99 güvenle, en büyük veriyle en küçük veri arasındaki fark ise 5 σ büyüklüğünde olur.
 (sınırları) +0,67 б. -0,67 б. % 50. Bağıl frekans. %80. +1,28 б. Güven aralıkları. -1,28 б. -1,64 б. %90. +1,64 б. -1,96 б. %95. +1,96 б. %99. -2,58 б. +2,58 б. -4б. -3б. -2,5 б. -2б. -1б. +1б. 2б. +2,5 б. 3б. 4б. 5 б. ±z değerleri. Verilerin yaklaşık %99’u, normal hata eğrisinin altında ve yaklaşık ±2,5 σ aralığında bulunur. Buna göre, bir hata eğrisinde %99 güvenle, en büyük veriyle en küçük veri arasındaki fark ise 5 σ büyüklüğünde olur.")
28
Gauss eğrisi (normal hata eğrisi) altında kalan alanlar, yukarıdaki şekillerle de ifade edilebilir. Örneğin; yaptığımız her 100 ölçmenin 90’ının gerçek ortalamanın (µ), X±1,64 σ’lık aralığı içine düştüğünü kabul edebiliriz. Burada güven seviyesi %90 ve güven aralığı – 1,64 σ’dan + 1,64 σ’ya kadardır. İşte burada kullanılan olasılık düzeyi yani güven seviyesi (GS), % cinsinden gerçek ortalamanın belli bir aralıkta yer alması olasılığıdır. Bir sonucun güven aralığı dışında yer alması olasılığı ise, genellikle anlamlılık seviyesi olarak adlandırılır.
, X±1,64 σ’lık aralığı içine düştüğünü kabul edebiliriz. Burada güven seviyesi %90 ve güven aralığı – 1,64 σ’dan + 1,64 σ’ya kadardır. İşte burada kullanılan olasılık düzeyi yani güven seviyesi (GS), % cinsinden gerçek ortalamanın belli bir aralıkta yer alması olasılığıdır. Bir sonucun güven aralığı dışında yer alması olasılığı ise, genellikle anlamlılık seviyesi olarak adlandırılır..")
29
Bilinen bir σ mevcutsa ve tek bir x ölçümü yapılmışsa, popülasyon ortalamasının µ, x±zσ aralığında olması gerektiğini söyleyebiliriz. Burada z (ortalamadan sapma) değeri, kabul edilen güven seviyesine bağlı bir parametredir. z=(X-µ)/σ eşitliğini yeniden düzenleyerek, tek bir ölçümün güven sınırları için, genel bir ifade bulunursa ( z, pozitif veya negatif değerler alabilir): Fakat tek bir ölçümle doğru değer tahmini çok az başvurulan bir yoldur. Bunun yerine, µ için daha iyi bir tahmin elde etmek amacıyla, n tane ölçümün deneysel ortalamasını ( ) kullanırız. Bu durumda, eşitlikteki X yerine ve σ yerine de ortalamanın standart hatası ( ) kullanılır:
 kullanırız. Bu durumda, eşitlikteki X yerine ve σ yerine de ortalamanın standart hatası ( ) kullanılır:")
30
Standardize edilmiş z değerleri:

31
Örnek: a- Önceki örnekten bir veri olan 1108 mg/L glikoz için ve aynı örnekteki numunenin ortalama değeri 1100,3 mg/L için %80 ve %95 güven aralıklarını hesaplayınız. Her durumda, sbirleşik= 19 olarak hesaplanmış ve σ’nın bu değere yeterince yakın olduğu kabul edilmiştir (yani burada, s = σ kabulü yapılır). Çizelgeden iki güven seviyesi için z=1,28 ve 1,96 olduğunu bulunuz. Bu değerler, GA eşitliğinde yerine konulursa: Bu hesaplamalardan, popülasyon ortalamasının (µ) (yani sistematik hata yokluğunda gerçek değerin) %80 olasılıkla, 1076 ve 1124,6 mg/L glikoz arasında kaldığına dikkat ediniz. Ayrıca, 1063,1 ve 1137,5 mg/L arasında kalma olasılığı ise %95’dir. b- Aynı örnekteki 7 ölçüm için ise; gerçek ortalamanın 1091,1-1109,5 mg/L glikoz arasında kalma olasılığı %80 ve 1086,2-1114,4 mg/L glikoz arasında kalma olasılığı da %95’dir.
 (yani sistematik hata yokluğunda gerçek değerin) %80 olasılıkla, 1076 ve 1124,6 mg/L glikoz arasında kaldığına dikkat ediniz. Ayrıca, 1063,1 ve 1137,5 mg/L arasında kalma olasılığı ise %95’dir. b- Aynı örnekteki 7 ölçüm için ise; gerçek ortalamanın 1091,1-1109,5 mg/L glikoz arasında kalma olasılığı %80 ve 1086,2-1114,4 mg/L glikoz arasında kalma olasılığı da %95’dir.")
32
Örnek: Önceki örnekteki numune için %95 güven aralığını 1100,3±10,0 mg/L glikoza azaltmak için kaç ölçüm yapılmalıdır? Burada teriminin ±10,0 mg/L glikoza eşit olmasını isteriz: %95’den daha yüksek bir olasılıkla, gerçek ortalamanın, deneysel ortalamanın ±10,0 mg/L sınırları dahilinde olması için yaklaşık 14 ölçüm yapılması gerektiği görülmektedir. 7 ölçüm yerine 14 ölçüm yapmakla, nispeten büyük kazanç sağlarız ve güven aralığını daralttığımıza da dikkat ediniz.

33
σ’nın bilinmediği durumlarda güven aralığı:
σ’yı doğru olarak hesaplamamızı önleyen, sınırlı numune miktarı ve zaman gibi sınırlamalardır. Böyle bir durumda, sadece ortalamayı değil, aynı zamanda kesinliği de hesaplamak için tekrarlanan ölçümlerden bir takım oluşturulmalıdır. Bilindiği gibi, küçük bir veri takımından hesaplanan σ belirsizdir. Bu yüzden, σ’nın iyi bir tahmini yapılamadığında, güven sınırları oldukça genişler. s’deki değişebilirliği hesaba katmak için, önemli bir diğer istatistiki parametre olan t’yi kullanırız. Tek bir ölçüm yapılmışsa, σ yerine s konularak, t tamamen z gibi tanımlanır: n tane ölçümün ortalaması için ise ikinci eşitlik kullanılır. z gibi t de güven seviyesine bağlıdır. Bununla beraber t, serbestlik derecesi sayısına da bağlıdır. Daha geniş t çizelgelerinde, serbestlik derecesi sonsuza giderken, t→z olacaktır. Tekrarlanan n tane ölçümün ortalaması ( ) için güven sınırları, z eşitliğinde olduğu gibi, t’den türetilebilir: İstatistiki hata
 için güven sınırları, z eşitliğinde olduğu gibi, t’den türetilebilir: İstatistiki hata.")
34
t-testi (student t testi)
t istatistiği, küçük veri grupları için genellikle student t olarak bilinir. Student t testi, ihtimaliyetin ölçümü için kullanılan istatistiki bir araçtır. Güven aralıklarının ifade edilmesi ve farklı deneylerden elde edilen sonuçların karşılaştırılması için de kullanılır. Böylelikle % 99 yada % 95 olasılıkla, doğruya yakın ortalamalar bulunabilir. t-testi, az sayıda tayin (analiz/ölçme/deney) yapıldığı zaman uygulanır. Az sayıda tayinden hem ortalama değer, hem de s hesaplanır. Ancak, s değeri kullanılarak yapılan işlemlerdeki hatalar büyük olur. t-değerleri böyle hataları en aza indirgemek amacıyla geliştirilmiştir. t-değerleri, analiz sayısının artmasıyla küçülür ve sonunda z değerleri haline döner. Az sayıda analiz sonucundan bulunan ortalama değerin, doğru değerden en çok ne kadar farklı olduğunun aranmasında, güven sınırları bağıntısından yararlanılır: 34
 yapıldığı zaman uygulanır. Az sayıda tayinden hem ortalama değer, hem de s hesaplanır. Ancak, s değeri kullanılarak yapılan işlemlerdeki hatalar büyük olur. t-değerleri böyle hataları en aza indirgemek amacıyla geliştirilmiştir. t-değerleri, analiz sayısının artmasıyla küçülür ve sonunda z değerleri haline döner. Az sayıda analiz sonucundan bulunan ortalama değerin, doğru değerden en çok ne kadar farklı olduğunun aranmasında, güven sınırları bağıntısından yararlanılır: 34.")
36
a- Yöntemin kesinliği ile ilgili ek bilgi olmadığını varsayarak,
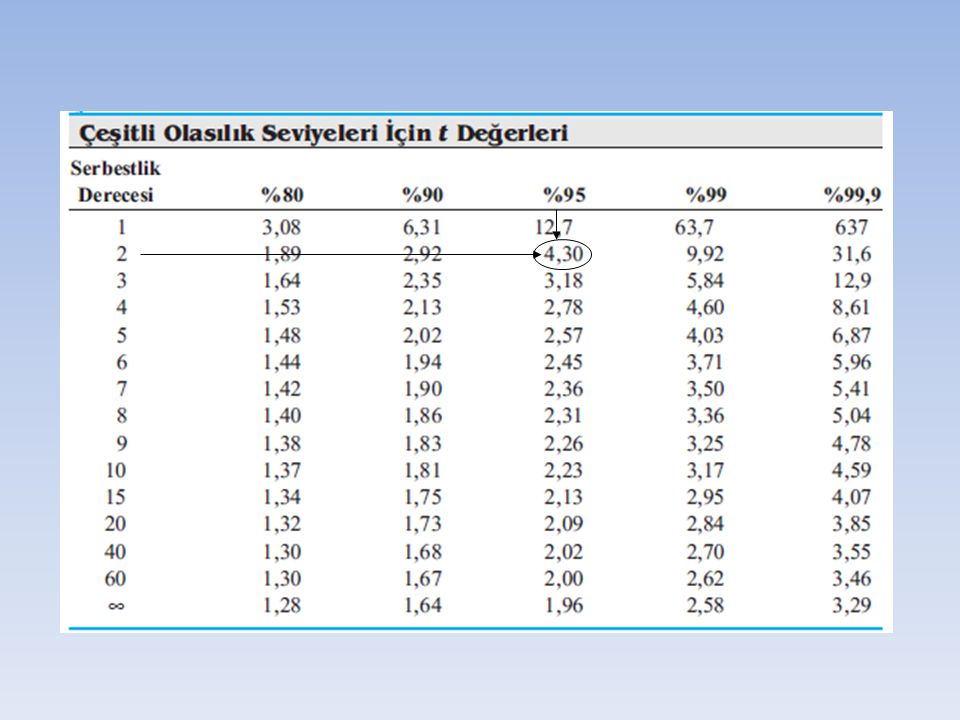
Örnek: Bir kimyacı, bir kan numunesinin alkol içeriği için aşağıdaki verileri elde etmiştir: %C2H5OH: 0,084; 0,089; ve 0,079. a- Yöntemin kesinliği ile ilgili ek bilgi olmadığını varsayarak, b- Önceki tecrübelere dayanarak, s→σ= %0,005 C2H5OH olduğunu varsayarak, Ortalamanın %95 güven aralığını hesaplayınız. Çizelgeden serbestlik derecesi 2 ve %95 güven seviyesi için t= 4,30’dur. Böylece:

37
b- Elimizde σ’nın iyi bir tahmini olduğunu varsayarsak (z=1,96 σ, %95 için):
σ için kullanılan değerden emin olunmasının, güven aralığını önemli miktarda daralttığına dikkat ediniz.

38
Örnek: Bir alaşımda Cu %’si tayin edilmiş ve ortalama değer 16,35 olarak bulunmuştur. Tayin için 4 analiz yapıldığına ve metodun s’ı %0,15 olduğuna göre, doğru değerin de içinde bulunacağı sınırları %95 güven seviyesinde tespit ediniz. 4 analiz yani 3 serbestlik derecesi ve %95 güven seviyesi için t-tablosundan t-değeri 3,18 bulunur. Buna göre: Bu sonuç, doğru değerin %95 ihtimalle %16,11-%16,59 arasında bir yerde bulunacağını ifade eder. Yukarıda verilen analizde analiz sayısı 4 değil de 9 olsaydı ve ortalama değer ile s de değişmemiş olsaydı, doğru değerin içinde bulunacağı sınırlar: Buna göre doğru değerin, %95 güvenle %16,23-%16,47 arasında bir yerde bulunacağı ifade edilir. Bu örnekte aralık, 0,24’ten 0,12’e inmiştir. Yani analiz sayısı arttıkça, doğru değerle ortalama değer arasındaki aralık daralır ve sonunda ortalama değer doğru değere eşit hale gelir.

Benzer bir sunumlar






 Kİ-KARE DAĞILIMI VE ÖZELLİKLERİ>")













