Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
İrem Soydal ~ Yurdagül Ünal soydal@hacettepe.edu.trsoydal@hacettepe.edu.tr yurdagul@hacettepe.edu.tryurdagul@hacettepe.edu.tr

2
Basit bir bilgi erişim sistemi (BES) dört parçadan oluşur: ◦ [ D, Q, F, R(q 1, d j ) ] D => dermede bulunan belgelerin mantıksal temsili/görüntüsünün oluşturduğu küme (içerik belirteçleri/dizin terimleri) Q => kullanıcı ihtiyaçlarının mantıksal temsillerinin oluşturduğu küme (kullanıcı “sorgu”ları) F => belge ve sorgu gösterimlerinin ve bunlar arasındaki bağlantıların/ilişkilerin gösterildiği iskelet yapı R (q 1, d j ) => sıralama fonksiyonu Bu fonksiyon, sorgu (q 1 ∈ Q) ve belge (d j ∈ D) gösterimlerini bir rakamla (sıra) ilişkilendirir. Bu tip bir sıralama sorgu için getirilecek belgelerin belirli bir kritere (örn. ilgililik) göre düzenlenmesini sağlar.
![ Basit bir bilgi erişim sistemi (BES) dört parçadan oluşur: ◦ [ D, Q, F, R(q 1, d j ) ] D => dermede bulunan belgelerin mantıksal temsili/görüntüsünün oluşturduğu küme (içerik belirteçleri/dizin terimleri) Q => kullanıcı ihtiyaçlarının mantıksal temsillerinin oluşturduğu küme (kullanıcı sorgu ları) F => belge ve sorgu gösterimlerinin ve bunlar arasındaki bağlantıların/ilişkilerin gösterildiği iskelet yapı R (q 1, d j ) => sıralama fonksiyonu Bu fonksiyon, sorgu (q 1 ∈ Q) ve belge (d j ∈ D) gösterimlerini bir rakamla (sıra) ilişkilendirir.](http://images.slideplayer.biz.tr/25/8805453/slides/slide_2.jpg "Bu tip bir sıralama sorgu için getirilecek belgelerin belirli bir kritere (örn. ilgililik) göre düzenlenmesini sağlar..")
3
Bir bilgi erişim sisteminde derlemdeki belgeler gerektiğinde hızlı bir biçimde erişilebilmesi için ? ? ? ? saklanır. Bir dizin, derlemde bulunan her bir belgeye en hızlı biçimde erişimi sağlayan ve özel veri yapıları kullanılarak oluşturulan bir yapıdır. Dizinleme, verilere yavaş olan bellek (Hard Disk) yerine çok daha hızlı olan ana hafızadan (RAM) erişimi mümkün kılar. Bilgi erişim sistemlerinde derlemlerin boyutları düşünüldüğünde dizinleme olmadan arama sonuçlarına hızlı erişimin mümkün olmadığı açıktır. dizinlenerek
 yerine çok daha hızlı olan ana hafızadan (RAM) erişimi mümkün kılar. Bilgi erişim sistemlerinde derlemlerin boyutları düşünüldüğünde dizinleme olmadan arama sonuçlarına hızlı erişimin mümkün olmadığı açıktır. dizinlenerek.")
4
Derlemdeki belgelerimiz: ◦ D1 : bilgi erişim ve bilgi dizinleme ◦ D2 : sanal dünya ve bilgi ◦ D3 : kütüphane ve veri saklama ◦ D4 : dünyada ekonomik durum ◦ D5 : günlük ekonomik veriler ◦ D6 : haftalık veya günlük mali veriler olsun

5
Derlemin özellikleri: 6 farklı belge var Toplamda 25 kelime var Durma kelimeleri çıkarılmadı Gövdeleme yapılmadı D1 : bilgi erişim ve bilgi dizinleme D2 : sanal dünya ve bilgi D3 : kütüphane ve veri saklama D4 : dünyada ekonomik durum D5 : günlük ekonomik veriler D6 : haftalık mali ve günlük mali veriler D1 : bilgi erişim ve bilgi dizinleme D2 : sanal dünya ve bilgi D3 : kütüphane ve veri saklama D4 : dünyada ekonomik durum D5 : günlük ekonomik veriler D6 : haftalık mali ve günlük mali veriler TerimlerBelgeler D1D1 D2D2 D3D3 D4D4 D5D5 D6D6 T1bilgi110000 T2erişim100000 T3ve111001 T4dizinleme100000 T5sanal010000 T6dünya010000 T7kütüphane001000 T8veri001000 T9saklama001000 T10dünyada000100 T11ekonomik000110 T12durum000100 T13günlük000011 T14veriler000011 T15haftalık000001 T16mali000001

6
Ne gerek var? ◦ Çok büyük belge derlemlerini düz bir belge-terim matrisi ile dizinlemek çok zor. ◦ Bir derlemi sorgularken en önemli noktalardan biri hızlı sonuç almak. Sorgu terimleri ile dizin terimlerinin çakıştırılma işleminin mümkün olduğunca hızlı gerçekleşmesi gerek. ◦ Ters dizin kütükleri bu büyük dermelerin dizinlenmesinde kolaylık ve bu dermeleri sorgulamada hız sağlıyor.

7
1. Belgeler içerisinde geçen kelimeler ayrıştırılır (parsing) ve her bir kelime ilgili belgenin numarası ile işaretlenir. DOC #1 Now is the time for all good men to come to the aid of their country DOC #2 It was a dark and stormy night in the country manor. The time was past midnight
 ve her bir kelime ilgili belgenin numarası ile işaretlenir. DOC #1 Now is the time for all good men to come to the aid of their country DOC #2 It was a dark and stormy night in the country manor. The time was past midnight.")
8
2. Tüm belgeler ayrıştırılıp çıkan kelimeler tabloya eklendikten sonra tablo kelimelere göre alfabetik olarak sıralanır.

9
3. Tek bir belgede geçen birden fazla kelime birleştirilir ve kelimenin belge içerisinde geçme sıklığı da tabloya eklenir.

10
4. Tablo, sözlük (dictionary) ve kayıtlar (postings) olmak üzere ikiye ayrılır.
 ve kayıtlar (postings) olmak üzere ikiye ayrılır.")
11
Ters dizinler üzerinde erişim fonksiyonlarının uygulamasını daha sonra inceleyeceğiz. ERİŞİM FONKSİYONLARI [ D, Q, F, R(q 1, d j ) ] F, R(q 1, d j ) ]
 ] F, R(q 1, d j ) ].")
12
Eşleştirme: ◦ Erişim fonksiyonu, derlemde bulunan belgelerle kullanıcı sorgularının hangi oranda eşleştiğini bulan ve bu eşleşmeyi derecelendiren (skor değeri) yöntemdir. Benzerlik: ◦ Erişim fonksiyonu, kullanıcı sorgusunu derlemde bulunan her bir belge ile teker teker karşılaştırarak her bir belge– sorgu çifti için bir benzerlik değeri üretir. Sıralama: ◦ Erişim fonksiyonu tarafından verilen her bir belge–sorgu skoru büyükten küçüğe doğru sıralanarak kullanıcıya sorgu ile ilgili olan belgelerin yer aldığı erişim çıktısı listesi sunulur.

13
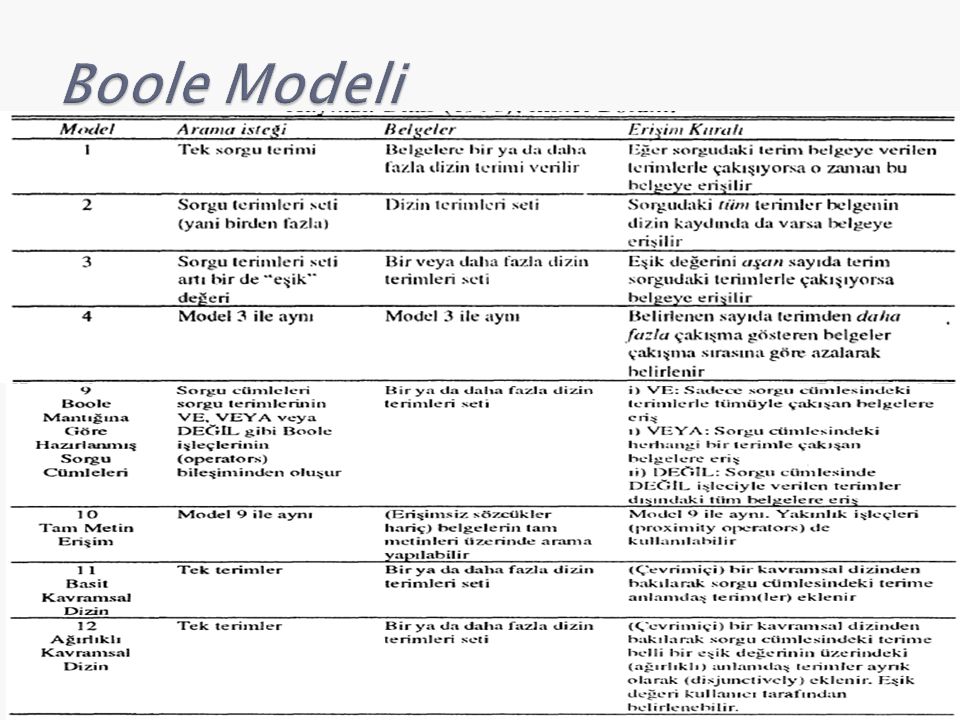
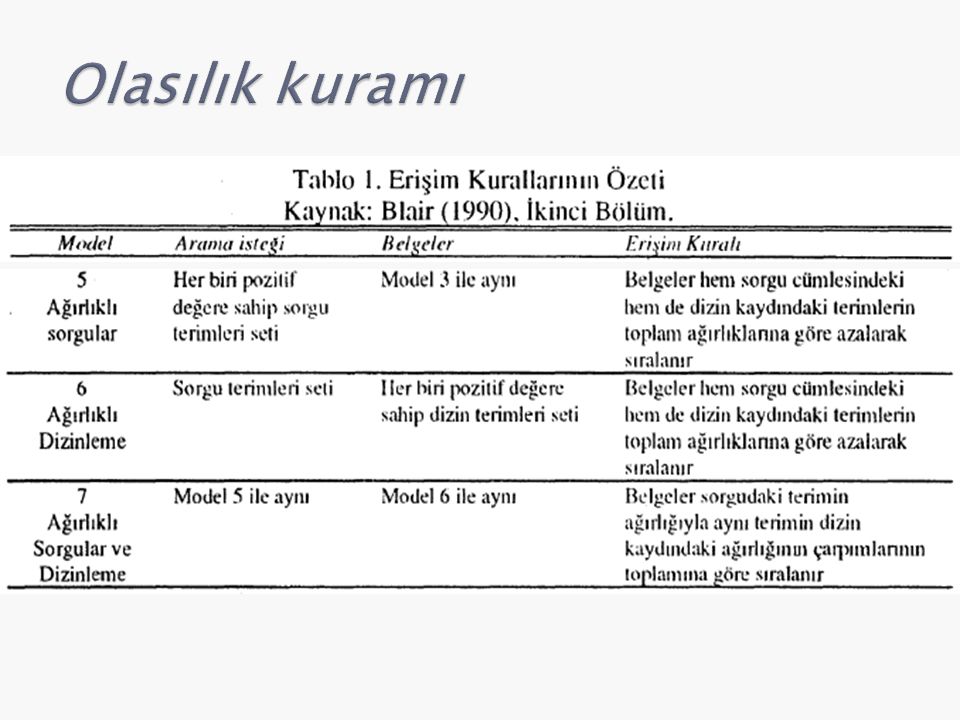
Bilgi erişim sistemlerinde kullanılan erişim kuralları (fonksiyonları/modelleri) kabaca üç başlık altında sınıflanabilir: ◦ Boole (kesin çakışma - exact match) ◦ Vektör uzayı ◦ Olasılık kuramı Bunların dışında modern bilgi erişimde kullanılan daha karmaşık modeller de var: ◦ Dil Modeli, Gizli Anlam Dizinleme, Sinir Ağları (neural networks), vb.
 kabaca üç başlık altında sınıflanabilir: ◦ Boole (kesin çakışma - exact match) ◦ Vektör uzayı ◦ Olasılık kuramı Bunların dışında modern bilgi erişimde kullanılan daha karmaşık modeller de var: ◦ Dil Modeli, Gizli Anlam Dizinleme, Sinir Ağları (neural networks), vb.")
18
Özellikler De Morgan’s Kuralı ¬ (a V b) (¬ a) (¬ b) ¬ (a b) (¬ a) V (¬ b)
 (¬ a) (¬ b) ¬ (a b) (¬ a) V (¬ b)")
19
Boole mantığında bir derleme yöneltilen sorgu içinde kullanılan terim derlem içindeki belgelerde ya vardır ya yoktur (ikili [binary] ağırlıklandırma kullanılıyor) => Buna göre sorgu çalıştırıldığında aranan terim ve belge arasında çakışma varsa belge “ilgili”, yoksa “ilgisiz” olarak değerlendirilecektir. ◦ Bir terimin bir belgede bir kez geçmesi ile bin kez geçmesi arasında bir farklılık yoktur. Bu ne demek?
![ Boole mantığında bir derleme yöneltilen sorgu içinde kullanılan terim derlem içindeki belgelerde ya vardır ya yoktur (ikili [binary] ağırlıklandırma kullanılıyor) => Buna göre sorgu çalıştırıldığında aranan terim ve belge arasında çakışma varsa belge ilgili , yoksa ilgisiz olarak değerlendirilecektir.](http://images.slideplayer.biz.tr/25/8805453/slides/slide_19.jpg "◦ Bir terimin bir belgede bir kez geçmesi ile bin kez geçmesi arasında bir farklılık yoktur. Bu ne demek .")
20
Boole modelinin temel avantajı tasarımındaki basitlik. En önemli dezavantajı ise tam çakışma (exact match) erişim kuralının çok az ya da çok fazla sonuç getirebilecek olması. Benzerlik derecelendirmesi yok: sorgu ile belgenin ne kadar ilgili olduğunu gösteren bir skor değeri üretilmiyor bunun yerine ilgili / ilgisiz (1/0) yargısı var. Eşleştirmelerde terim ağırlıklandırma yok: bir belge içerisinde 1 kez geçen terimle 100 kez geçen terim aynı ağırlıkta, bu belge içeriğini ifade eden değerli terimleri seçmemizi engelliyor. Sorgu oluşturmak zor: kullanıcıların bilgi ihtiyaçlarını ifade edebilmek için karmaşık sorgular kurabilmesi gerekiyor. Hata toleransı yok: bilgi ihtiyacı tam ifade edilmek zorunda, yaklaşık sonuç alma olasılığı yok.
 erişim kuralının çok az ya da çok fazla sonuç getirebilecek olması. Benzerlik derecelendirmesi yok: sorgu ile belgenin ne kadar ilgili olduğunu gösteren bir skor değeri üretilmiyor bunun yerine ilgili / ilgisiz (1/0) yargısı var. Eşleştirmelerde terim ağırlıklandırma yok: bir belge içerisinde 1 kez geçen terimle 100 kez geçen terim aynı ağırlıkta, bu belge içeriğini ifade eden değerli terimleri seçmemizi engelliyor. Sorgu oluşturmak zor: kullanıcıların bilgi ihtiyaçlarını ifade edebilmek için karmaşık sorgular kurabilmesi gerekiyor. Hata toleransı yok: bilgi ihtiyacı tam ifade edilmek zorunda, yaklaşık sonuç alma olasılığı yok..")
21
Bir terimin bir belgedeki geçiş sıklığı belgenin hem belirli bir konu ile olan ilgililiğini hem de derlemdeki diğer belgelerle olan yakınlığını belirler. Bugün biliniyor ki terim ağırlıklandırması erişim performansını fark edilir derecede artırıyor. Bu ağırlıklandırma yöntemi Boole mantığında yer almadığı için vektör uzayı yaklaşımı ortaya çıktı.

22
Vektör uzayı modelinin temel özelliği kısmi çakışmaya (partial matching) olanak tanıması. Bu kısmi çakışma hem sorgu terimlerinin hem de belgelerdeki dizin terimlerinin ağırlıklandırılması ile gerçekleştirilebiliyor. Bu terim ağırlıkları kullanıcı sorgusu ile sistemde tutulan belgelerde yer alan dizin terimlerinin benzerliklerinin hesaplanması için kullanılıyor.

23
Erişilen belgelerin benzerlik derecelerine göre azalan sıralama ile dizilmesi sonucu vektör modeli sorgu terimleri ile kısmi olarak çakışan (partial match) belgeleri de dikkate almış olur. Yapılan incelemeler bu şekilde (terim ağırlıklarına göre en ilgiliden daha ilgisize göre) sıralanmış bir sonuç listesinin, kullanıcıların bilgi ihtiyaçlarını daha net bir şekilde karşılaması açısından Boole modeli ile elde edilen sonuç listesinden daha iyi olduğunu gösteriyor.
 sıralanmış bir sonuç listesinin, kullanıcıların bilgi ihtiyaçlarını daha net bir şekilde karşılaması açısından Boole modeli ile elde edilen sonuç listesinden daha iyi olduğunu gösteriyor..")
24
Matematiksel arka plan

25
http://www.aof.anadolu.edu.tr/kitap/IOLTP/2288/unite04.pdf

27
Verilen a,b ve c vektörleri için bir birine en yakın olanlar hangileridir. Bir birine en yakın olan vektörler a ve b, neden?

28
Vektörler arasında hesaplanan cos Ø değeri açıyı değil açısının cos değerini gösteriyor. Ø açsı büyüdükçe açının cos değeri küçülüyor. O zaman cos Ø değeri ne kadar büyükse vektörler birbirine o kadar yakındır diyebiliriz. Vektörler arasındaki cos Ø değeri iki vektörün bir birine ne kadar yakın olduğunu gösterir. İki vektör arasındaki açının kosinüsünün 1.0 çıkması iki vektörün aynı ya üst üste olduğunu gösterir. Yani aralarındaki Ø açısı 0(sıfır). Vektörler arasındaki bu açı Bilgi Erişim alanında benzerlik ölçüsü (similarity) olarak adlandırılır.
. Vektörler arasındaki bu açı Bilgi Erişim alanında benzerlik ölçüsü (similarity) olarak adlandırılır..")
29
Boole modelindeki en büyük problem belge-sorgu eşleşmeleri için bir derece (rank) belirlenememesiydi. Vektör yaklaşımı ile bu sorun bu bir nebze giderildi. Şimdi sorun, belge içerisindeki her terimin aynı önemle değerlendirilmesi. Oysa bir terim bir belge içerisindeki ne kadar çok geçiyorsa ? ? ? ?. Diğer taraftan bir belgede sıklığı yüksek olan bir terim aynı zamanda derlemdeki diğer belgeler içinde de sık geçiyorsa ? ? ? ? ? ? O halde bir belge içinde çok geçen ancak derlemde çok sayıda belgede bulunmayan terimler bizim için daha anlamlı. Bu nedenle erişim fonksiyonunda bu tür terimler daha değerli olmalı ama nasıl? o terim o belge için o kadar değerlidir. ilgili terimin ayırt edici özelliği veya belge içindeki diğer terimlere göre göreceli değeri “düşük” olacaktır. (Söz konusu terim dizin terimi olarak tercih edilmeyecektir, hatta bazı durumlarda“stop words” listesine bile eklenmesi düşünülebilir.)
.")
30
Ters dizin kütüğünde terimler için 0/1 ağırlığı yerine tf*idf çarpımı kullanılır. tf (term frequency): Terim sıklığı anlamına gelir ve bir terimin bir belge içerisindeki geçeme sayısını ya da sıklığını (frequency) ifade eder. tf değerini hesaplamak için 2 yöntem var: Birincisinde; terimin ilgili belge içerisinde geçme sayısı (sıklığı) doğrudan kullanılır, İkincisinde; terimin ilgili belge içerisinde geçme sayısı (sıklığı), ilgili belgedeki toplam kelime sayısına bölünür ve sayı normalleştirilir. idf (inverse document frequency): Devrik belge sıklığı anlamına gelir ve bir terimin derlemdeki diğer belgelerde geçme sıklığını ifade eder. idf toplam belge sayısının belirli bir terimi içeren belge sayısına bölündükten sonra ölçeği küçültmek için logaritmasının alınması ile bulunur. idf hesaplanırken aşağıdaki formül kullanılır: N=Derlemde bulunan toplam belge sayısı df(i)= i teriminin geçtiği belge sayısı i i
: Terim sıklığı anlamına gelir ve bir terimin bir belge içerisindeki geçeme sayısını ya da sıklığını (frequency) ifade eder. tf değerini hesaplamak için 2 yöntem var: Birincisinde; terimin ilgili belge içerisinde geçme sayısı (sıklığı) doğrudan kullanılır, İkincisinde; terimin ilgili belge içerisinde geçme sayısı (sıklığı), ilgili belgedeki toplam kelime sayısına bölünür ve sayı normalleştirilir. idf (inverse document frequency): Devrik belge sıklığı anlamına gelir ve bir terimin derlemdeki diğer belgelerde geçme sıklığını ifade eder. idf toplam belge sayısının belirli bir terimi içeren belge sayısına bölündükten sonra ölçeği küçültmek için logaritmasının alınması ile bulunur. idf hesaplanırken aşağıdaki formül kullanılır: N=Derlemde bulunan toplam belge sayısı df(i)= i teriminin geçtiği belge sayısı i i.")
31
Örneğin 10.000 belgelik bir derlem olduğunu düşünelim. Aşağıdaki örneklerde pay; derlemdeki toplam belge sayısını, payda ise derlemde terimi içeren belge sayısını göstermektedir: - Terimi içeren belge sayısı arttıkça idf değeri azalıyor. - İlgili terim kullanılarak yapılacak bir sorguda idf değeri yüksek çıkan belgelerin gelmesi daha etkili sonuç listesi elde edileceği anlamına geliyor. Belgelerin idf değerleri

32
wij= tf ij * log (N/df j ) wij= t j teriminin d i belgesi için ağırlığı N= derlemdeki toplam belge sayısı df j = t j teriminin belge sıklığı tf ij = t j teriminin d i belgesinde geçme sıklığı (terim sıklığı)
 wij= t j teriminin d i belgesi için ağırlığı N= derlemdeki toplam belge sayısı df j = t j teriminin belge sıklığı tf ij = t j teriminin d i belgesinde geçme sıklığı (terim sıklığı)")
33
“bilgi” teriminin D 1 belgesi için tf ve idf değerleri nedir? tf(“bilgi”) = 2 idf(“bilgi”)=log(6/2) = 0,477 tf(“bilgi”)*idf(“bilgi”) = 0,954 Derlemdeki belgelerimiz: D 1 : bilgi erişim ve bilgi dizinleme D 2 : sanal dünya ve bilgi D 3 : kütüphane ve veri saklama D 4 : dünyada ekonomik durum D 5 : günlük ekonomik veriler D 6 : haftalık mali ve günlük mali veriler “ve” teriminin D 6 belgesi için tf ve idf değerleri nedir? tf(“ve”) = 1 idf(“ve”)=log(6/4) = 0,176 tf(“ve”)*idf(“ve”) = 0,176 “mali” teriminin D 6 belgesi için tf ve idf değerleri nedir? tf(“mali”) = 2 idf(“ mali ”)=log(6/1) = 0,778 tf(“ mali ”)*idf(“ mali ”) = 1,556 Örnekler içinde en değerli kelime hangisi? Neden?
 = 2 idf( bilgi )=log(6/2) = 0,477 tf( bilgi )*idf( bilgi ) = 0,954 Derlemdeki belgelerimiz: D 1 : bilgi erişim ve bilgi dizinleme D 2 : sanal dünya ve bilgi D 3 : kütüphane ve veri saklama D 4 : dünyada ekonomik durum D 5 : günlük ekonomik veriler D 6 : haftalık mali ve günlük mali veriler ve teriminin D 6 belgesi için tf ve idf değerleri nedir. tf( ve ) = 1 idf( ve )=log(6/4) = 0,176 tf( ve )*idf( ve ) = 0,176 mali teriminin D 6 belgesi için tf ve idf değerleri nedir. tf( mali ) = 2 idf( mali )=log(6/1) = 0,778 tf( mali )*idf( mali ) = 1,556 Örnekler içinde en değerli kelime hangisi. Neden .")
34
Derlemdeki terimlere göre ters dizin kütüğündeki terim ağırlıklarını D 1 için güncelleyelim. tf(“bilgi”)*idf(“bilgi”)= 2*0,477 = 0,954 tf(“erişim”)*idf(“erişim”)= 1*0,778 = 0,778 tf(“dizinleme”)*idf(“dizinleme”)= 1*0,778= 0,778 tf(“ve”)*idf(“ve”)= 1*0,176 = 0,176 TerimlerBelgeler D1D1 D2D2 D3D3 D4D4 D5D5 D6D6 T1 bilgi0.95410000 T2 erişim0.77800000 T3 ve0.17611001 T4 dizinleme0.77800000 T5 sanal010000 T6 dünya010000 T7 kütüphane001000 T8 veri001000 T9 saklama001000 T10 dünyada000100 T11 ekonomik000110 T12 durum000100 T13 günlük000011 T14 veriler000011 T15 haftalık000001 T16 mali000001 Derlemdeki belgelerimiz: D 1 : bilgi erişim ve bilgi dizinleme D 2 : sanal dünya ve bilgi D 3 : kütüphane ve veri saklama D 4 : dünyada ekonomik durum D 5 : günlük ekonomik veriler D 6 : haftalık mali ve günlük mali veriler
*idf( bilgi )= 2*0,477 = 0,954 tf( erişim )*idf( erişim )= 1*0,778 = 0,778 tf( dizinleme )*idf( dizinleme )= 1*0,778= 0,778 tf( ve )*idf( ve )= 1*0,176 = 0,176 TerimlerBelgeler D1D1 D2D2 D3D3 D4D4 D5D5 D6D6 T1 bilgi T2 erişim T3 ve T4 dizinleme T5 sanal T6 dünya T7 kütüphane T8 veri T9 saklama T10 dünyada T11 ekonomik T12 durum T13 günlük T14 veriler T15 haftalık T16 mali Derlemdeki belgelerimiz: D 1 : bilgi erişim ve bilgi dizinleme D 2 : sanal dünya ve bilgi D 3 : kütüphane ve veri saklama D 4 : dünyada ekonomik durum D 5 : günlük ekonomik veriler D 6 : haftalık mali ve günlük mali veriler.")
35
Tonta, Y. (1995). Bilgi erişim sistemleri. (http://yunus.hacettepe.edu.tr/~soydal/bby156_2013/3/BilgiErisimSistemleri_tonta1995.pdf)http://yunus.hacettepe.edu.tr/~soydal/bby156_2013/3/BilgiErisimSistemleri_tonta1995.pdf Buckland, M. (1991). Information as thing. (http://people.ischool.berkeley.edu/~buckland/thing.html)http://people.ischool.berkeley.edu/~buckland/thing.html Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s.17-29. (Tam metin)Tam metin Diğer yardımcı kaynaklar: Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval. (Tam metin)Tam metin Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval. (Tam metin)Tam metin Bu derste kullanılan slaytların çoğunluğu Information organization and retrieval (R. Larson & W. Sack, 2001) Bilgi erişim ilkeleri (Y. Tonta, 2002) Bilgi erişim (G. Köse, 2012) derslerine ait slaytlardan derlenmiştir.
. Information as thing. ( Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s (Tam metin)Tam metin Diğer yardımcı kaynaklar: Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval. (Tam metin)Tam metin Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval. (Tam metin)Tam metin Bu derste kullanılan slaytların çoğunluğu Information organization and retrieval (R. Larson & W. Sack, 2001) Bilgi erişim ilkeleri (Y. Tonta, 2002) Bilgi erişim (G. Köse, 2012) derslerine ait slaytlardan derlenmiştir..")
Benzer bir sunumlar