Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
BM-308 Paralel Programlamaya Giriş Bahar 2016 (3. Sunu) (Yrd. Doç. Dr. Deniz Dal)
 (Yrd. Doç. Dr. Deniz Dal)")
2
High Performance Computing (HPC) yani Yüksek Başarımlı Hesaplama (YBH) kavramının temelinde bilgisayarların hesaplama (işlemci) güçlerini bir araya getirerek tek bir sistem gibi çalıştırma düşüncesi yatmaktadır. Bu sayede elde edilen yüksek hesaplama gücü ile sonuç üretmesi günler hatta haftalar alan programlardan daha kısa sürede ve maksimum başarım ile sonuç alınması hedeflenmektedir. Bir Elin Nesi Var İki Elin Sesi Var

3
Cluster mimarisi, birden fazla sıradan bilgisayarın ya da sunucunun birbirine bir ağ üzerinden bağlanması ve böylece tek bir yüksek performanslı yapı olarak çalıştırılması için geliştirilmiş bir teknolojidir. Yüksek başarımlı hesaplamalarda daha kısa sürede daha kesin sonuç elde etmek için işlemci sayısı ve hafıza miktarlarının artırılması gerekmektedir. İşlemci sayısının tek bir sunucu üzerinde artırıldığı durumda belli bir işlemci sayısından sonra maliyet katlanarak artar. Bu durumda makul bir maliyete sahip 2 (dual) veya 4 (quad) işlemcili sunucuların birleştirilmesi ile oluşturulan HPC Cluster çözümleri çok daha az maliyetle performans problemini halleder. KÜME (CLUSTER) MİMARİSİ İLE YBH
 veya 4 (quad) işlemcili sunucuların birleştirilmesi ile oluşturulan HPC Cluster çözümleri çok daha az maliyetle performans problemini halleder. KÜME (CLUSTER) MİMARİSİ İLE YBH.")
4
BÜYÜYEBİLMEYE AÇIKLIK: Daha yüksek hesaplama gücüne ihtiyaç duyulduğu zaman sadece cluster içindeki sunucu (compute node) sayısı istenilen adette artırılarak istenen güç elde edilir. MALİYET: Bir sunucunun maliyeti içerisine konacak işlemci sayısının artmasıyla yükselir. Ancak işlemci sayısını artırma metodu olarak sunucu sayısını artırma yoluna gidilirse maliyet çok büyük ölçüde azalır. YEDEKLİLİK: Sunucu kümesi içindeki herhangi bir sunucunun arızalanması cluster sisteminin çalışmasını engellemez. Sunucu sayısı kadar yedeklilik sağlanır. CLUSTER SİSTEMLERİN AVANTAJLARI

5
Cluster’ı oluşturan sunucuların tek bir sistem gibi çalışması için birbirleriyle çok hızlı haberleşmelerini sağlayacak bir ağ alt yapısına (interconnect) ihtiyaç vardır. Gigabit Ethernet teknolojisinin bant genişliği 1Gb/s iken Infiniband Duplex teknolojisinin bant genişliği 40 Gb/s dir. CLUSTER SİSTEMLERİNDE INTERCONNECT computation/communication ratio?????

6
BEOWULF CLUSTER

8
IBM BLUE GENE

9
MÜHENDİSLİK Uçak, gemi ve otomobil tasarımı Ürün tasarımı ve testleri Araç çarpışma testleri Nükleer kazalar sonucu oluşabilecek serpintiler EKONOMİ Uzun vadeli ekonomik öngörüler Yüksek doğrulukta borsa tahminleri Bankaların risk analizi HAVA TAHMİNLERİ 4 ya da 5 günlük hava tahminlerinin süresi HPC ile 10 güne kadar çıkmaktadır. MALZEME TAHMİNLERİ Yarıiletken cihaz simulasyonları İnşaat sektörü için hafif ve dayanıklı malzeme tasarımı İlaçların etki tahmin simülasyonu SAVUNMA SANAYİ Savaş oyunları simülasyonu Şifre kırma HPC SİSTEMLERİN GENEL KULLANIM ALANLARI

10
Paralel Programlama Ucuz Mu? ÖRNEK 1: 100 metrelik bir duvar örülmek isteniyor. Bir işçi 1 metrelik duvarı yarım günde örüyorsa duvar örme işlemi 50 günde biter. İşçi sayısını 100’e çıkarırsak ne olur? Süre kesinlikle azalır. Peki ya işçilere ödeyeceğimiz ücret ve ekipman temini? ÖRNEK 2: Bir teknisyen bir otomobilin eski bir lastiğini yenisiyle 15 dakikada değiştiriyorsa bütün lastiklerin değişmesi 1 saat sürer. Peki 4 teknisyen aynı anda işe koyulursa?

11
Parallel Processing Want 2x speedup now? Use 2 processors! Simple Example: adding 8 numbers 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 3 + 3 + 4 + 5 + 6 + 7 + 8 6 + 4 + 5 + 6 + 7 + 8 10 + 5 + 6 + 7 + 8 15 + 6 + 7 + 8 21+ 7 + 8 28 + 8 36 Sequential (1 Proc.) 7 steps 1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 3 + 7 + 5 + 6 + 7 + 8 10 + 11 + 7 + 8 21 + 15 36 Parallel (2 Procs.) 4 steps = 1.75x faster (approaches 2x with more numbers) Idea: give diff. parts of problem to diff. procs. In general: up to N times faster with N procs.
 7 steps Parallel (2 Procs.) 4 steps = 1.75x faster (approaches 2x with more numbers) Idea: give diff. parts of problem to diff. procs. In general: up to N times faster with N procs..")
12
von Neumann Architecture For over 50 years, virtually all computers have followed a common machine model known as the von Neumann Computer. Named after the Hungarian mathematician John von Neumann. A von Neumann computer uses the stored-program concept. The CPU executes a stored program that specifies a sequence of read and write operations on the memory. Basic design: o Memory is used to store both program and data instructions o Program instructions are coded data which tell the computer to do something o Data is simply information to be used by the program o A central processing unit (CPU) gets instructions and/or data from memory, decodes the instructions and then sequentially performs them.
 gets instructions and/or data from memory, decodes the instructions and then sequentially performs them..")
13
Seri Hesaplama Nedir? Traditionally, software has been written for serial computation: o To be run on a single computer having a single Central Processing Unit (CPU); o A problem is broken into a discrete series of instructions. o Instructions are executed one after another. o Only one instruction may execute at any moment in time.
; o A problem is broken into a discrete series of instructions. o Instructions are executed one after another. o Only one instruction may execute at any moment in time..")
14
Paralel Hesaplama Nedir? In the simplest sense, parallel computing is the simultaneous use of multiple compute resources to solve a computational problem. To be run using multiple CPUs A problem is broken into discrete parts that can be solved concurrently Each part is further broken down to a series of instructions Instructions from each part execute simultaneously on different CPUs

15
Ortak Paylaşım Bellekli Model (Shared Memory)
")
16
Shared Memory Architecture General Characteristics Shared memory parallel computers vary widely, but generally have in common the ability for all processors to access all memory as global address space. Multiple processors can operate independently but share the same memory resources. Changes in a memory location effected by one processor are visible to all other processors.

17
Dağıtık Bellekli Model (Distributed Memory)
")
18
Dağıtık-Paylaşım Bellekli Model (Hybrid)
")
19
Data ve Task Parallelism 20 kişilik bir öğrenci grubuna 5 farklı sorudan oluşan bir sınav yapılıyor. Soruları değerlendirmek üzere 5 kişilik bir öğretmen grubu görevlendiriliyor. 1. Senaryo: Herbir öğretmen bütün öğrencilerin sınav kağıtlarında sadece bir soruyu değerlendirmekten sorumlu tutuluyor. (1. öğretmen 1. soruları, 2. öğretmen 2. soruları....) 2. Senaryo: Sınav kağıtları 5 e bölünüyor ve herbir öğretmen kendisine verilen 4 adet sınav kağıdındaki bütün soruları değerlendirmekten sorumlu tutuluyor. Her iki senaryo için de herbir hoca toplamda 20 soru değerlendirmiş olur. 1. senaryo task parallelism e 2. senaryo ise data parallelism e örnek olarak verilebilir.
 2. Senaryo: Sınav kağıtları 5 e bölünüyor ve herbir öğretmen kendisine verilen 4 adet sınav kağıdındaki bütün soruları değerlendirmekten sorumlu tutuluyor. Her iki senaryo için de herbir hoca toplamda 20 soru değerlendirmiş olur. 1. senaryo task parallelism e 2. senaryo ise data parallelism e örnek olarak verilebilir..")
20
Flynn's Classical Taxonomy * There are different ways to classify parallel computers. One of the more widely used classifications, in use since 1966, is called Flynn's Taxonomy. * Flynn's taxonomy distinguishes multi-processor computer architectures according to how they can be classified along the two independent dimensions of Instruction and Data. Each of these dimensions can have only one of two possible states: Single or Multiple. * The matrix below defines the 4 possible classifications according to Flynn. S I S D Single Instruction, Single Data S I M D Single Instruction, Multiple Data M I S D Multiple Instruction, Single Data M I M D Multiple Instruction, Multiple Data

21
Single Instruction, Single Data (SISD) * A serial (non-parallel) computer * Single instruction: only one instruction stream is being acted on by the CPU during any one clock cycle * Single data: only one data stream is being used as input during any one clock cycle * Deterministic execution * This is the oldest and until recently, the most prevalent form of computer * Examples: most PCs, single CPU workstations and mainframes
 * A serial (non-parallel) computer * Single instruction: only one instruction stream is being acted on by the CPU during any one clock cycle * Single data: only one data stream is being used as input during any one clock cycle * Deterministic execution * This is the oldest and until recently, the most prevalent form of computer * Examples: most PCs, single CPU workstations and mainframes")
22
SIMD Single Instruction Multiple data MIMD Multiple Instruction Multiple data

23
SPMD Single Program Multiple data Eg., master-slave program: If ( myid.eq. 0 ) then … master does work else … slaves do different work endif SPMD is most commonly used model Can incorporate SIMD and MIMD Each process runs same program but may execute different instructions Each process assigned a rank (myid)
 then … master does work else … slaves do different work endif SPMD is most commonly used model Can incorporate SIMD and MIMD Each process runs same program but may execute different instructions Each process assigned a rank (myid).")
24
a.outb.outc.out Each process runs its own program MPMD Multiple Program Multiple data

25
Partitioning One of the first steps in designing a parallel program is to break the problem into discrete "chunks" of work that can be distributed to multiple tasks. This is known as decomposition or partitioning. There are two basic ways to partition computational work among parallel tasks: domain decomposition and functional decomposition. Domain Decomposition In this type of partitioning, the data associated with a problem is decomposed. Each parallel task then works on a portion of the data.

26
Functional Decomposition In this approach, the focus is on the computation that is to be performed rather than on the data manipulated by the computation. The problem is decomposed according to the work that must be done. Each task then performs a portion of the overall work.

27
Parallel Programming Models Message Passing Model A set of tasks that use their own local memory during computation. Multiple tasks can reside on the same physical machine as well across an arbitrary number of machines. Tasks exchange data through communications by sending and receiving messages. Data Parallel Model Most of the parallel work focuses on performing operations on a data set. The data set is typically organized into a common structure, such as an array or cube A set of tasks work collectively on the same data structure, however, each task works on a different partition of the same data structure

28
4 Steps in Creating a Parallel Program Decomposition of computation in tasks Assignment of tasks to processes Orchestration of data access, comm, synch. Mapping processes to processors

29
Principles of Parallel Computing Parallelism and Amdahl’s Law Preserving data locality Load balancing Coordination and synchronization Performance modelling All of these items make parallel programming more difficult than sequential programming.

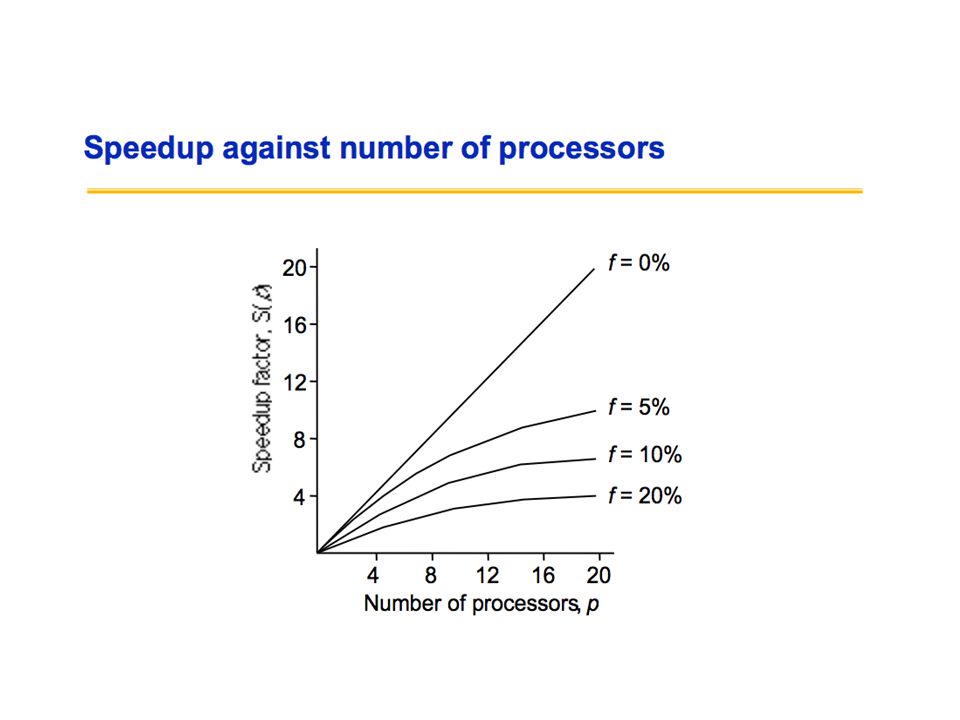
31
Amdahl's law states that the performance improvement to be gained from using some faster mode of execution is limited by the fraction of the time the faster mode can be used.

Benzer bir sunumlar




 problemleri (Matching and Assignment problems)>")











>")



>")

>")
