Sunuyu indir
0
SPSS’i çalıştırma

1
SPSS İlk Açılışı

2
Data View ve Variable View

3
Değişken Tanımlama - 1

4
Değişken Tanımlama - 2

5
Boş Veri Sayfası

6
Veri Girişi - 1

7
Veri Girişi - 2

8
Dosya Kaydetme 1 2 3

9
File Menüsü

10
SPSS Dosya Türleri - 1 Veri (Data) dosyası (.sav): Üzerinde işlem yapılacak verileri içerir. Çıktı (Output) dosyası (.spo): Bir işlem sonucunda elde edilen çıktıyı içerir. Komut (Syntax) dosyalari (.sps): SPSS’in özel programlama dilinde yazılmış program dosyaları
 dosyası (.spo): Bir işlem sonucunda elde edilen çıktıyı içerir. Komut (Syntax) dosyalari (.sps): SPSS’in özel programlama dilinde yazılmış program dosyaları.")
11
SPSS Dosya Türleri - 2 2. Çıktı dosyası 1. Veri dosyası
3. Komut dosyası

12
Edit Menüsü

13
Data Menüsü - 1

14
Data Menüsü – 2 (Sort Cases)
3 1 2 5 6. Veriler gelire göre artan sırada dizildi 4

15
Data Menüsü – 3 (Sort Cases)
Orijinal veriyi bu kez eğitim düzeyine göre sıralayalım. Eğitim düzeyi eşit olanları da kendi içlerinde gelirlerine göre sıralayalım.

16
Data Menüsü – 4 (Select Cases)
")
17
Data Menüsü – 5 (Select Cases)
")
18
Data Menüsü – 6 (Select Cases)
Örnek olarak verilerimiz içinde kilosu 60’a eşit ve büyük olanları seçelim. 1 3 4 2

19
Data Menüsü – 7 (Select Cases)
")
20
Data Menüsü – 8 (Select Cases)
SPSS’de Select Cases ile bir seçim yapıldığında, bundan sonra yapılacak tüm analizler (istatistiksel hesaplamalar, grafik çizimleri, hipotez testleri vb.) seçilmiş olan gözlemler üzerinden yapılır. Şimdi de kilosu 60 ile 70 arasında olan gözlemleri seçelim. Bunun için menüden “Select Cases” seçilir ve “If condition is satisfied”a tıklanarak şart kısmına şu yazılır: 60 <= kilo & kilo <=70 Burada iki şart & (ve) operatörü ile birbirine bağlanır. Bu sayede kilosu 60 ile 70 arasında olanlar seçilmiş olur.
 seçilmiş olan gözlemler üzerinden yapılır. Şimdi de kilosu 60 ile 70 arasında olan gözlemleri seçelim. Bunun için menüden Select Cases seçilir ve If condition is satisfied a tıklanarak şart kısmına şu yazılır: 60 <= kilo & kilo <=70. Burada iki şart & (ve) operatörü ile birbirine bağlanır. Bu sayede kilosu 60 ile 70 arasında olanlar seçilmiş olur.")
21
Data Menüsü – 9 (Select Cases)
1 2 3

22
Data Menüsü – 10 (Select Cases)
Şimdi de kilosu 60 tan büyük veya boyu 1,60’dan kısa olanları seçelim (60 ve 1,60 dahil değil). Bunun için yine Select Cases seçilir ve bu sefer if kısmındaki şarta şu yazılır: kilo > 60 | boy < 1.60
. Bunun için yine Select Cases seçilir ve bu sefer if kısmındaki şarta şu yazılır: kilo > 60 | boy <")
23
Data Menüsü – 11 (Select Cases)
2 3

24
Data Menüsü – 12 (Select Cases)
3 1 4 2
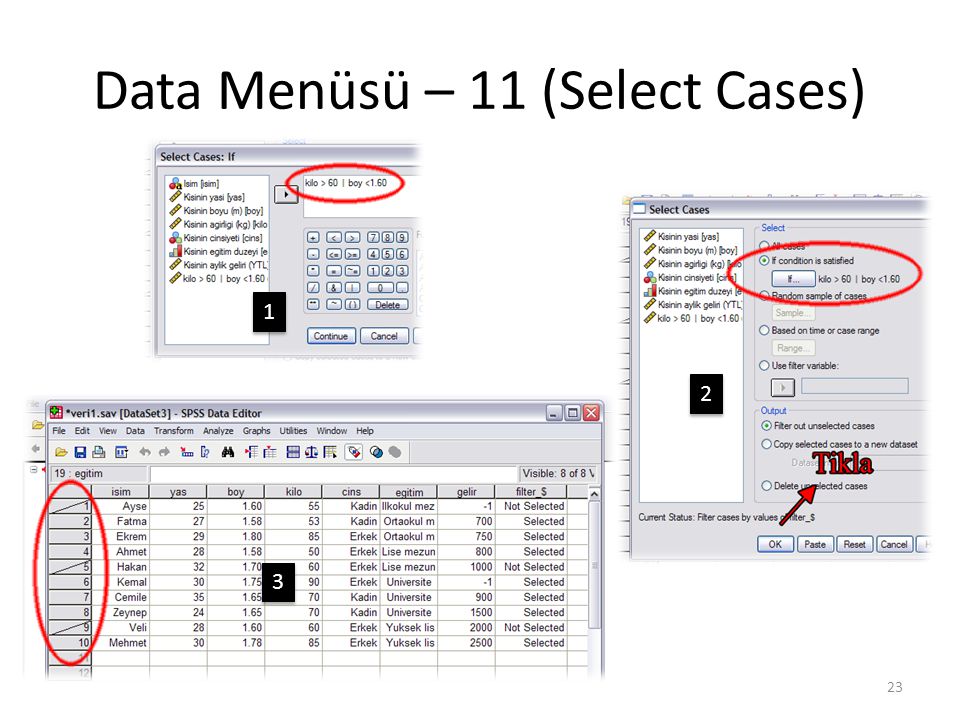
25
Data Menüsü – 13 (Select Cases)
")
26
Data Menüsü – 14 (Select Cases)
2 1 3 4
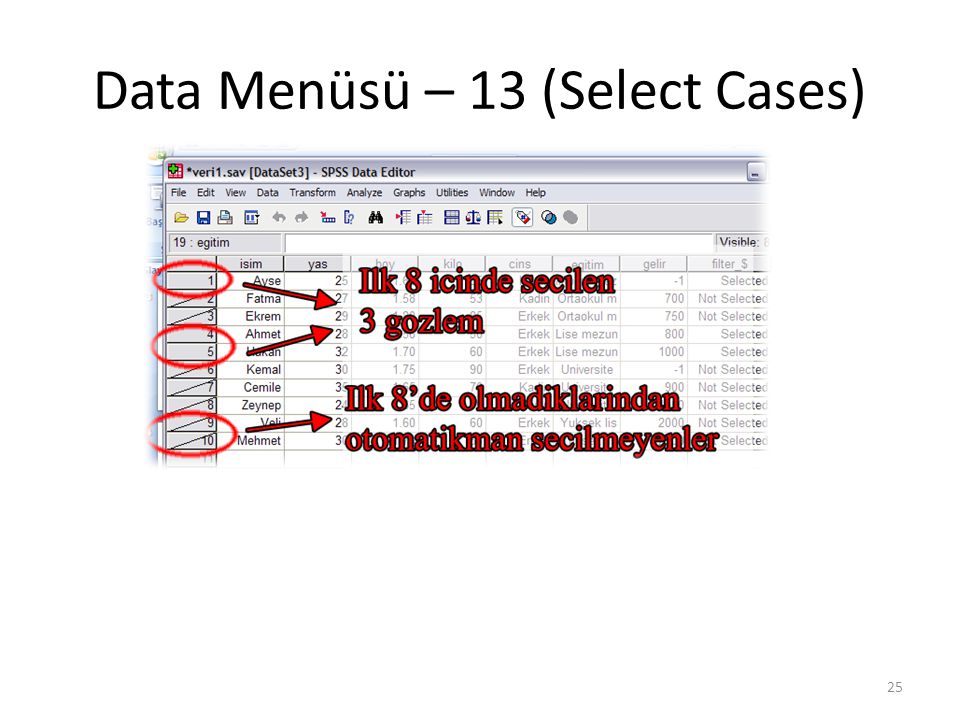
27
Data Menüsü – 15 (Select Cases)
")
28
Data Menüsü – 16 (Weight Cases)
SPSS’e toplu veri girişi yapıldığında, analizlere geçmeden önce weight cases seçeneği seçilmelidir. Bu sayede frekansların bulunduğu değişken SPSS’e tanıtılmış olur. Örneğin bir bölgedeki meslekler ve gelir gruplarına ait veri toplanmış ve aşağıdaki tablo elde edilmiş olsun: Meslek Gelir grubu Doktor Avukat Mühendis Öğretmen Çiftçi Diğer Düşük 10 8 12 20 25 70 Orta 50 65 60 80 Yüksek 40 35 15 5

29
Data Menüsü – 17 (Weight Cases)
Bu veriyi girmek için 3 değişken tanımlanır. Bunlardan ilk ikisi ‘meslek’ ve ‘gelir’ değişkenleri olup kategorik değişkenlerdir. Bu değişkenlerden meslek için Values kısmında Doktor (1), Avukat (2), Mühendis (3), Öğretmen (4), Çiftçi (5) ve Diğer (6) seçenekleri tanımlanır. Benzer tanımlama gelir değişkeni için Düşük (1), Orta (2) ve Yüksek (3) şeklinde yapılır. Üçüncü değişken ‘frekans’ olup bu değişkende özel bir tanımlama yapılmaz. Frekans değişkenine tablo içinde yer alan gözlem sayıları girilecektir. Bu işlemler yapılır ve veri aşağıdaki gibi girilir:
, Avukat (2), Mühendis (3), Öğretmen (4), Çiftçi (5) ve Diğer (6) seçenekleri tanımlanır. Benzer tanımlama gelir değişkeni için Düşük (1), Orta (2) ve Yüksek (3) şeklinde yapılır. Üçüncü değişken ‘frekans’ olup bu değişkende özel bir tanımlama yapılmaz. Frekans değişkenine tablo içinde yer alan gözlem sayıları girilecektir. Bu işlemler yapılır ve veri aşağıdaki gibi girilir:")
30
Data Menüsü – 18 (Weight Cases)
2 3

31
Data Menüsü – 19 (Weight Cases)
2 3 4
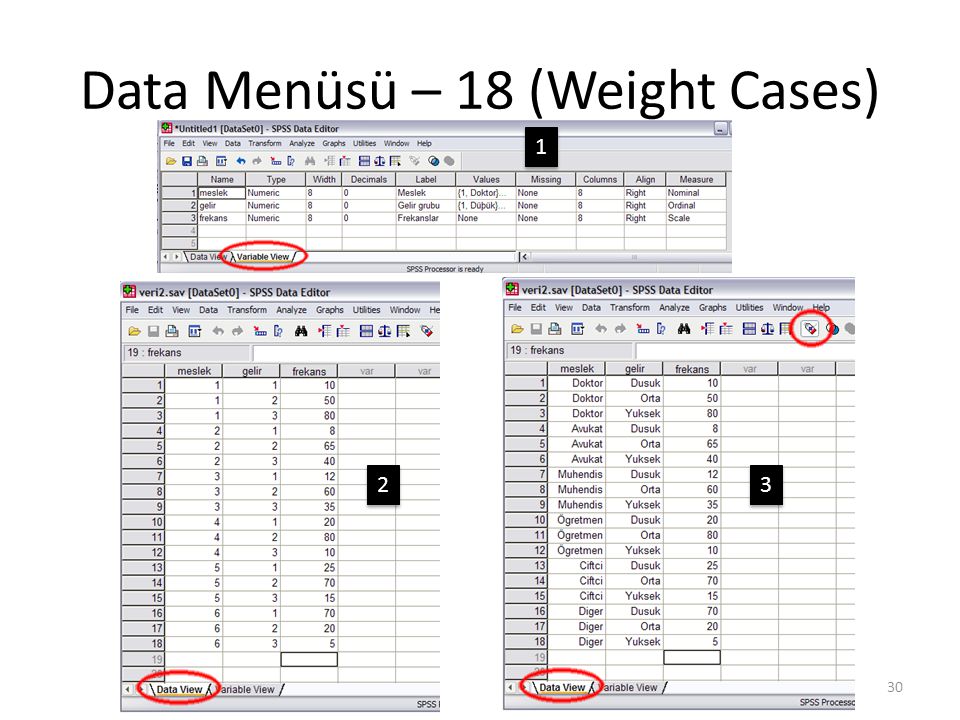
32
Transform Menüsü – 1

33
Transform Menüsü – 2 (Comp. Var.)
1 2

34
Transform Menüsü – 3 (Comp. Var.)
Her bir gözlem için Beden Kitle Endeksini (BKİ) hesaplayalım. BKİ = Kilo (kg) / Boy2 (m) formülünü kullanacağız. Beden Kitle Endeksi değerlerini ‘bki’ isimli yeni bir değişkende hesaplatacağız. Bunun için Transform menüsünden Compute Variable seçeneği seçilir ve açılan pencerede şu işlemler yapılır:
 hesaplayalım. BKİ = Kilo (kg) / Boy2 (m) formülünü kullanacağız. Beden Kitle Endeksi değerlerini ‘bki’ isimli yeni bir değişkende hesaplatacağız. Bunun için Transform menüsünden Compute Variable seçeneği seçilir ve açılan pencerede şu işlemler yapılır:")
35
Transform Menüsü – 4 (Comp. Var.)
1 2 3

36
Transform Menüsü – 5 (Comp. Var.)
1 2

37
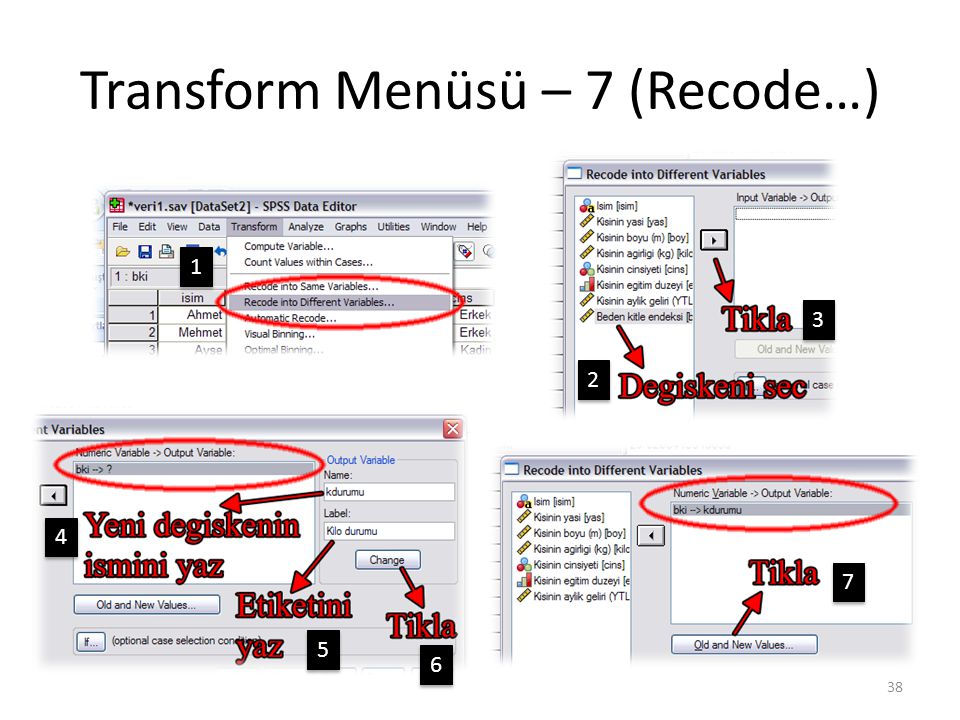
Transform Menüsü – 6 (Recode…)
Transform menüsünde yer alan ‘Recode into Same Variables’ ve ‘Recode into Different Variables’ seçeneklerini kullanarak kodlama yapılabilir. ‘Recode into Same Variables’da mevcut değişkenin üzerine kodlama yapılırken, ‘Recode into Different Varibles’da yeni bir değişken tanımlanıp üzerine kodlama yapılır. Örneğin beden kitle endeksini kullanarak kişilerin kilo durumunu incelemek isteyebiliriz. bki için literatürde aşağıdaki aralıklar tanımlanmıştır: bki < 20 ise zayıf, 20 ≤ bki < 25 ise normal, 25 ≤ bki < 30 ise kilolu, 30 ≤ bki < 40 ise şişman, bki ≥ 40 ise aşırı şişman. Şimdi bu ölçütü veri üzerinde kullanalım. Burada ‘kdurumu’ isimli yeni bir değişken üzerine kodlama yapacağız. Bunun için ‘Recode into Different Variables’ seçeneğini seçeceğiz.

38
Transform Menüsü – 7 (Recode…)
1 3 2 4 7 5 6

39
Transform Menüsü – 8 (Recode…)
2 3 12 1 14 13 15 4 6 5 18 7 16 19 17 8 10 9 11
40
Transform Menüsü – 9 (Recode…)
1 2 3

41
Transform Menüsü – 10 (Recode…)
Şimdi de yeni oluşan “kdurumu” değişkenimizin kategorilerini belirtelim. Bunun için “Variable View” penceresine gelinir ve “kdurumu” değişkeni için “Values”a tıklanır. Ardından aşağıdaki şekilde kategoriler belirlenir:

42
Transform Menüsü – 11 (Recode…)
")
43
Transform Menüsü – 12 (Recode…)
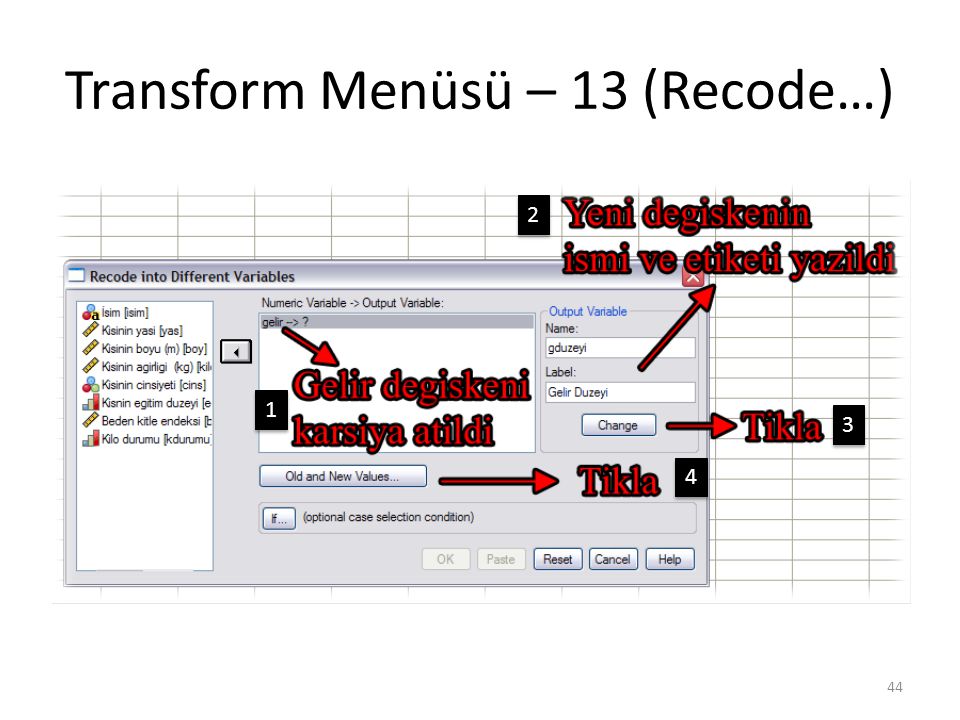
Bir diğer örnek olarak da gözlemleri gelirlerine göre gruplara ayıralım. Bunun için “gduzeyi” isimli bir yeni değişken oluşturacağız. Gelir düzeylerini aşağıdaki gibi belirleyelim: Gelir < 800 ise düşük, 800 ≤ Gelir < 1200 ise orta, Gelir ≥ 1200 ise yüksek. Bir önceki örnekte olduğu gibi ‘Recode into Different Variables’ seçeneğini seçeceğiz. Burada farklı olarak “Gelir” değişkeninde kayıp değerler de yer aldığından “missing values” için de kodlama yapılır. Sonuç olarak açılan pencerede aşağıdaki düzenlemeler yapılır.

44
Transform Menüsü – 13 (Recode…)
2 1 3 4

45
Transform Menüsü – 14 (Recode…)
3 1 2 5
46
Transform Menüsü – 15 (Recode…)
Bu işlemler sonucunda aşağıdaki pencere elde edilir. Burada yeni değişken için de kayıp değerin “-1” olarak alınacağına dikkat edelim.

47
Transform Menüsü – 16 (Recode…)
“Continue” dedikten sonra gelen pencerede de “OK” denildiğinde “gdurumu” değişkeni oluşturulmuş olur. Son olarak “Variable View”a gelinerek bu değişkenin de kategorileri ve kayıp değeri tanımlanır. Kategoriler tanımlanırken “Values”a tıklanır ve “1=Dusuk”, “2=Orta”, “3=Yuksek” tanımlamaları yapılır. Öte yandan kayıp değeri “-1” olarak kabul ettiğimizden “Missing”e tıklandığında “Discrete Missing Values” seçilir ve kutucuğa “-1” yazılır. Bu işlemler sonucunda “Data View”a dönüldüğünde yeni değişken aşağıdaki gibi oluşmuş olmalıdır:

48
Transform Menüsü – 17 (Recode…)
")
49
Transform Menüsü – 18 (Replace…)
“Transform” menüsünde son olarak “Replace Missing Values”u göreceğiz. Bazen analizler kayıp değerler yerine ilgili değişkenin ortalaması yazılır. Özellikle gözlem sayısı az olduğunda tercih edilen bu yöntemde, ortalamanın gözlemleri temsil ettiği varsayılır. Bu sayede kayıp değerler yerine ortalama alınarak gözlem sayısının eksilmesi önlenmiş olur. Veri setimizdeki “Gelir” değişkeni için bu işlemi yapmak isteyelim. 3 ve 7 numaralı gözlemler gelirlerini belirtmemişlerdir. Bu kişilerin gelir değerlerini, diğer gözlemlerin ortalamasına eşit almak istiyorsak “Transform” menüsünden “Replace Missing Values”a tıklanır.

50
Transform Menüsü – 19 (Replace…)
4 2 3

51
Transform Menüsü – 20 (Replace…)
")









![EĞİM EĞİM-1 :Bir dik üçgende dikey (dik) uzunluğun yatay uzunluğa oranına (bölümüne) eğim denir. Eğim “m” harfi ile gösterilir. [AB] doğrusu X ekseninin.](/7/1973076/big_thumb.jpg "EĞİM EĞİM-1 :Bir dik üçgende dikey (dik) uzunluğun yatay uzunluğa oranına (bölümüne) eğim denir. Eğim “m” harfi ile gösterilir. [AB] doğrusu X ekseninin.>")



 Sayfa düzenleyebilmeniz için “Giriş” bağlantısına tıklayınız. Giriş yaptıktan sonra sayfaların içeriğini.>")




larla Çalışmak>")

