Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
-ÇAPRAZ TABLOLAR -İKİ DEĞİŞKENLİ ANALİZ -ANALİZE BAŞKA BİR DEĞİŞKEN EKLEMEK -ÖRNEKLEM SEÇİMİ -HEDEFLENMİŞ ÖRNEKLEM SEÇİMİ -RASGELE ÖRNEKLEM SEÇİMİ -YENİ BİR VERİ SETİ İÇİN ÖRNEKLEM SEÇMEK

2
ÇAPRAZ TABLOLAR Çapraz tablolar temel olarak, iki değişken arasındaki ilişkiyi analiz etmek için kullanılır. Bu, araştırmacıya değişkenler arasındaki ilişkiyi ve ilgili her bir değişkenin kategorilerinin kesişimlerini inceleme olanağı sağlar. İkili tablolamanın en basit türü, iki değişkenli analizdir.

3
İKİ DEĞİŞKENLİ ANALİZ Örneğe göre , iki değişken için çapraz tablolama yapmak için şu menüleri takip etmek gerekir; SPSS Data ekranında, Birinci Sütunda cinsiyet, İkinci sütunda, Oy Vereceği parti olan basit bir anket sonucu olan datamız olsun. Çapraz tablo analizi için, datanızın bulunduğu ekranda aşağıdaki menüyü takip etmelisiniz.

4
ANALYSE > DESCRIPTIVE STATISTICS > CROSSTABS

5
Açılan ekranda, Bağımlı değişkeni (Örnekte, “Türkiye AB’ye üye olmalıdır” ifadesi) Row(s) penceresine, bağımsız değişkeni (Örnekte, Cinsiyet) Column(s) penceresine taşıyınız.
 Row(s) penceresine, bağımsız değişkeni (Örnekte, Cinsiyet) Column(s) penceresine taşıyınız.")
6
Çıktı tablosunda yer alacak bilgileri belirleyebilmek için “CELLS” tuşuna tıklanarak aşağıdaki ekran açılır.

7
Ekranda “Percentages” bölümünde “Column” bölümü seçilerek AB ÜYELİĞİ verisinin yüzdelerinin gelmesi sağlanır. Ardından, “Continue” ve “OK” tıklanarak çıktı ekranına geçilir

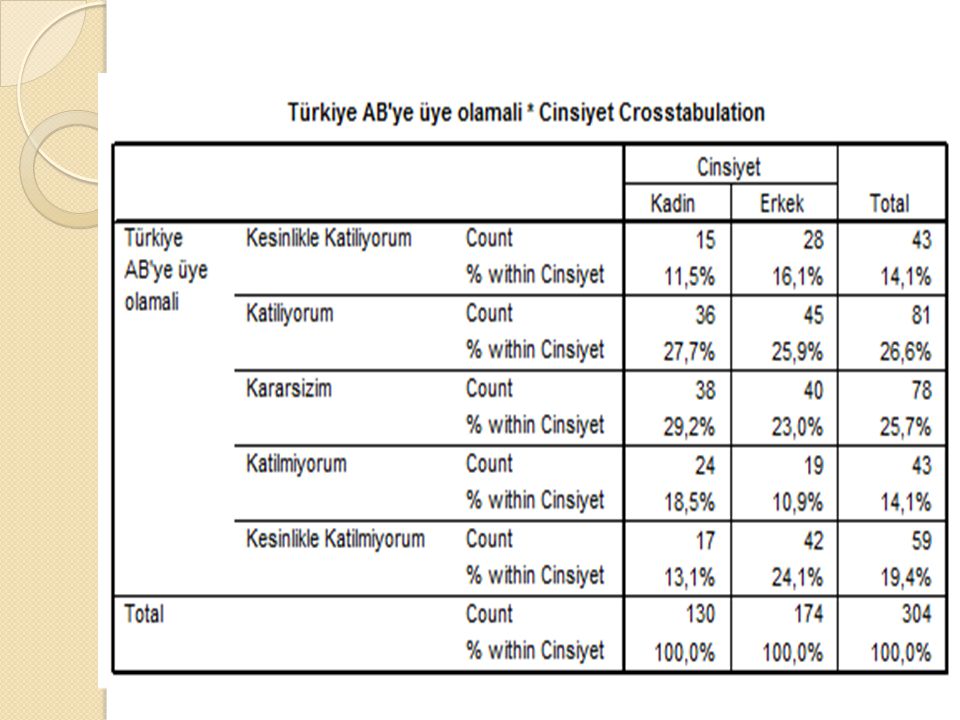
9
Tablodaki verilere baktığımızda en belirgin farkın Kesinlikle katılmıyorum kategorisinde olduğu gözlenmektedir. Bu kategorideki verilerden Türkiye’nin AB’ye üye olması görüşüne erkeklerin % 24,1’i kesinlikle katılmazken, bu oran % 17’dir.

10
ANALİZE BAŞKA BİR DEĞİŞKEN EKLEMEK
Şimdi, bir önceki bölümde kabaca incelediğimiz iki değişkenli ilişkiyi daha derinlemesine nasıl inceleyebileceğimiz görelim. Bunun için öncelikle aşağıdaki menüyü seçiniz. DATA » SPLIT FILE Karşınıza aşağıdaki pencere gelecektir.

11
Buradan “Compare Groups” düğmesini seçtikten sonra, ilişkiye dahil etmek istediğiniz değişkeni seçerek (Örnekte, Eğitim Düzeyi) “Group Based on” kutucuğuna taşıyınız ve OK tuşunu tıklayınız.
 Group Based on kutucuğuna taşıyınız ve OK tuşunu tıklayınız.")
12
Şimdi Data View penceresinin sol altında, Split File On uyarsı belirecektir. Bu uyarı bundan sonra oluşturulacak tabloların belirlenen bir değişkene göre (Örneğimizde, Eğitim) bölüneceği anlamına gelmektedir. Şimdi “Crosstabs” (ANALYSE > DESCRIPTIVE STATISTICS > CROSSTABS) menüsüne dönmeli ve iki değişkenli analiz için yaptığımız işlemlerin aynısını tekrarlamalıyız.
 menüsüne dönmeli ve iki değişkenli analiz için yaptığımız işlemlerin aynısını tekrarlamalıyız.")
13
Karşımıza aşağıdakinin benzeri bir tablo çıkacaktır
Karşımıza aşağıdakinin benzeri bir tablo çıkacaktır. Bu tabloyu kullanarak cevaplayıcıların AB üyeliği hakkındaki görüşlerinin, cinsiyet ve eğitim değişkenlerine göre değişimini inceleyebiliriz.

14
ÖRNEK SEÇİMİ SPSS yazılımı, bir kullanıcının bir veri setinden örnek almasına olanak sağlar. Bu, hedefli ya da rastgele bir örnek olabilir.

15
HEDEFLENMİŞ SEÇİM Zaman zaman belirli veri setindeki yer alan tüm verileri araştırmanızda kullanmak istemeyebilirsiniz. Özellikle verileri siz toplamadıysanız, ihtiyaç duymadığınız verilerden kurtulmanız gerekecektir. Örneğin bayan öğretmenler üzerine bir araştırma yapıyorsanız, erkek öğretmenlere ait verilerin, veri setinden çıkartılması gerekecektir. Eğer Türkiye İstatistik Kurumu ya da başka bir kurum tarafından toplanan verileri kullanmayı planlıyorsanız SPSS’in bu özelliği işinizi oldukça kolaylaştıracaktır. Mevcut veri setinden çalışacağımız örneği seçmek için aşağıdaki menüleri takip edin:

16
DATA » SELECT CASES

17
“Select Cases” i seçtiğimizde karşımıza iletişim kutusu çıkacaktır
“Select Cases” i seçtiğimizde karşımıza iletişim kutusu çıkacaktır. Burada analiz etmeyi istediğimiz katılımcı türlerini seçebilir ve dolayısıyla araştırma kriterlerinize uymayanları çalışma dışında bırakabiliriz.

18
Bunun için, “Select ... If condition is satisfied” altındaki “If” tuşuna tıklamalıyız. Karşımıza aşağıdaki gibi bir “If” iletişim kutusu karşınıza çıkacaktır.

19
Şimdi sınırlandırmak istediğiniz değişkeni sağdaki kutucuğa taşıyın
Şimdi sınırlandırmak istediğiniz değişkeni sağdaki kutucuğa taşıyın. Örnekte cinsiyeti temsil eden D1 değişkeni kullanılmıştır. Yapılan ilk kodlamada (Variable View – Values seçeneği) Erkelere “1”, Kadınlara “2”kodunu vermiştik. Burada sadece kadınları dikkate alacağımız için değişkeni “D1 > 1” olarak tanımladık. Eğer yaş değişkenini ele alsaydık ve 20 ile 30 yaş aralığı ile ilgilenseydik, tanımı “20 < Yaş < 30” şeklinde yapacaktık. Şimdi sırasıyla Continue ve OK tuşlarına tıklayınız. Data View penceresinin sağ alt köşesinde “Filter On” uyarısı ve bu filtreleme sonucu devre dışı kalan değişkenler üzerinde çapraz bir çizgi oluşacaktır. Artık oluşturduğunuz filtreyi devre dışı bırakana kadar, yapılacak tüm hesaplamalarda sadece kadın cevaplayıcılara ait veriler kullanılacaktır. Filtreyi kaldırabilmek için “Select Cases” iletişim kutusundaki “Reset” fonksiyonunu kullanınız.
 Erkelere 1 , Kadınlara 2 kodunu vermiştik. Burada sadece kadınları dikkate alacağımız için değişkeni D1 > 1 olarak tanımladık. Eğer yaş değişkenini ele alsaydık ve 20 ile 30 yaş aralığı ile ilgilenseydik, tanımı 20 < Yaş < 30 şeklinde yapacaktık. Şimdi sırasıyla Continue ve OK tuşlarına tıklayınız. Data View penceresinin sağ alt köşesinde Filter On uyarısı ve bu filtreleme sonucu devre dışı kalan değişkenler üzerinde çapraz bir çizgi oluşacaktır. Artık oluşturduğunuz filtreyi devre dışı bırakana kadar, yapılacak tüm hesaplamalarda sadece kadın cevaplayıcılara ait veriler kullanılacaktır. Filtreyi kaldırabilmek için Select Cases iletişim kutusundaki Reset fonksiyonunu kullanınız.")
20
RASGELE SEÇİM Şimdi veri setinden rasgele bir örnek grubunu seçmeyi istediğimizi varsayalım. Bunun için yine “Select Cases” (DATA-SELECT CASE) iletişim kutusunu kullanabiliriz.
 iletişim kutusunu kullanabiliriz.")
21
Bu sefer, ilgili “Select
Bu sefer, ilgili “Select ... Random sample of cases” radyo düğmesini seçtikten sonra “Sample” tuşuna tıklayalım. Karşımıza aşağıda gösterilen “Random Sample” iletişim kutusu çıkacaktır: 2 seçeneğimiz var : Biri yaklaşık(approximately) seçneğidir. Veri setlerinin hepsi seçtiğimiz yüzdeye bölünmeyebilir ve tam sayı elde edemeyebiliriz. Bu durumda bunu kullanırız. Diğeri de tam olarak(exactly) seçeneğidir. burdan da n sayıda veriden belirleyeceğimiz sayıda örnek seçebiliriz. (Bu örnek için, örneklerin %20’si seçilecektir. )
 seçneğidir. Veri setlerinin hepsi seçtiğimiz yüzdeye bölünmeyebilir ve tam sayı elde edemeyebiliriz. Bu durumda bunu kullanırız. Diğeri de tam olarak(exactly) seçeneğidir. burdan da n sayıda veriden belirleyeceğimiz sayıda örnek seçebiliriz. (Bu örnek için, örneklerin %20’si seçilecektir. )")
22
“Continue” ve ardından “Select Cases” iletişim kutusuna döndüğümüzde“OK”e tıklayalım. Bu işlem sonrası “Data Editor” penceresinin görünümü aşağıda verilmiştir.Dikkat edersek veri setinin yaklaşık % 80’nin üzerinde bir önceki uygulamada olduğu gibi diyagonal bir çizgi oluşmuştur. Bu çizgi, filtre devre dışı bırakılana kadar söz konusu değişkenlerin hesaplamalara dâhil edilmeyeceğini göstermektedir

23
Parametrik olmayan testler
Binomial Ki-kare Runs

24
Binom Testi Tek örneklemli binom testi sınıflama ölçeğiyle veri toplanmış bağımlı değişken için kullanılır. Bağımlı değişken hakkındaki veriler iki düzeylidir (“binomial”; örneğin, cinsiyet için Erkek-Kadın biçiminde). Mevcut verilerin öngörülen bir sayıdan/yüzdeden farklı olup olmadığını test etmek için kullanılır. Örneğin, hsb2turkce veri dosyasını kullanarak öğrencilerin cinsiyete göre dağılımının %50’den (yani 0,5) farklı olup olmadığını test edelim
. Mevcut verilerin öngörülen bir sayıdan/yüzdeden farklı olup olmadığını test etmek için kullanılır. Örneğin, hsb2turkce veri dosyasını kullanarak öğrencilerin cinsiyete göre dağılımının %50’den (yani 0,5) farklı olup olmadığını test edelim.")
25
Hipotezi; Boş Hipotez (H0): “Örneklemdeki erkek ve kız öğrenciler eşit (yani %50-%50) dağılmışlardır.” (50’den farklı değildir) Araştırma Hipotezi (H1): “Öğrencilerin cinsiyete göre dağılımı eşit değildir.” (çift kuyruk testi). H0 : ų = ų 0 H1: ų ų 0 (çift kuyruk testi) Boş hipotezleri büyüktür/küçüktür diye de kurabilirsiniz. O zaman tek kuyruk (büyükse sol, küçükse sağ) test yapılır. Örneğin, H0 : “Kız öğrencilerin oranı %50’den daha yüksektir.” H1 :“Kız öğrencilerin oranı %50’den daha düşüktür.” H0 : ų > ų 0 H1 : ų < ų 0 (sol kuyruk testi)
: Öğrencilerin cinsiyete göre dağılımı eşit değildir. (çift kuyruk testi). H0 : ų = ų 0. H1: ų ų 0 (çift kuyruk testi) Boş hipotezleri büyüktür/küçüktür diye de kurabilirsiniz. O zaman tek kuyruk (büyükse sol, küçükse sağ) test yapılır. Örneğin, H0 : Kız öğrencilerin oranı %50’den daha yüksektir. H1 : Kız öğrencilerin oranı %50’den daha düşüktür. H0 : ų > ų 0. H1 : ų < ų 0 (sol kuyruk testi)")
26
Binom Testi - Spss Mönüden
Analyze -> Nonparametric tests-> Binomial’i seçin Test değişkenleri olarak Cinsiyet’i seçin. Test oranı olarak 0.5 girin. OK seçeneğine basın.

27
Sonucu :

28
Yorumu : Öğrencilerin cinsiyete göre dağılımı 91 erkek (%46) 109 (%55) kız şeklindedir. Ancak aradaki fark istatistiksel açıdan anlamlı değildir (p = 0,229). Yani şansa bağlı olarak bu şekilde bir oranın çıkması muhtemeldir. Boş hipotez kabul edilir. Öğrencilerin cinsiyete göre dağılımında istatistiksel açıdan anlamlı bir fark yoktur. Başka bir deyişle, cinsiyete göre dağılım hipotezde öngörülen %50’den farklı değildir
 109 (%55) kız şeklindedir. Ancak aradaki fark istatistiksel açıdan anlamlı değildir (p = 0,229). Yani şansa bağlı olarak bu şekilde bir oranın çıkması muhtemeldir. Boş hipotez kabul edilir. Öğrencilerin cinsiyete göre dağılımında istatistiksel açıdan anlamlı bir fark yoktur. Başka bir deyişle, cinsiyete göre dağılım hipotezde öngörülen %50’den farklı değildir.")
29
Ki-Kare Uyum İyiliği Testi
Ki- kare uyum iyiliği testi bir sınıflama değişkeni için gözlenen oranların hipotezde iddia edilen oranlara uyup uymadığını test etmek için kullanılır. Örneğin, öğrenci nüfusunun %10 Latin, %10 Asyalı, %10 Siyah ve %70 Beyaz öğrencilerden oluştuğunu iddia edelim. Örneklemde gözlenen oranların hipotezde verilen oranlardan farklı olup olmadığını hsb2turkce veri dosyasını kullanarak test edelim

30
Hipotezi; Boş Hipotez (H0): “Öğrencilerin ırka göre dağılımı %10 Latin, %10 Asyalı, %10 Siyah ve %70 Beyaz şeklindedir” Araştırma Hipotezi (H1): “Öğrencilerin ırka göre dağılımı %10 Latin, %10 Asyalı, %10 Siyah ve %70 Beyaz şeklinde değildir” (çift kuyruk testi). H0 : ų = ų 0 H1 : ų ų 0 (çift kuyruk testi) Boş hipotezleri büyüktür/küçüktür diye de kurabilirsiniz. O zaman tek kuyruk (büyükse sol, küçükse sağ) test yapılır. Örneğin, H0 : “Siyah öğrencilerin oranı %10’dan daha yüksektir.” H1 :“Siyah öğrencilerin oranı %10’dan daha düşüktür.” H0 : ų > ų 0 H1 : ų < ų 0 (sol kuyruk testi)
: Öğrencilerin ırka göre dağılımı %10 Latin, %10 Asyalı, %10 Siyah ve %70 Beyaz şeklinde değildir (çift kuyruk testi). H0 : ų = ų 0. H1 : ų ų 0 (çift kuyruk testi) Boş hipotezleri büyüktür/küçüktür diye de kurabilirsiniz. O zaman tek kuyruk (büyükse sol, küçükse sağ) test yapılır. Örneğin, H0 : Siyah öğrencilerin oranı %10’dan daha yüksektir. H1 : Siyah öğrencilerin oranı %10’dan daha düşüktür. H0 : ų > ų 0. H1 : ų < ų 0 (sol kuyruk testi)")
31
Ki-kare - Spss Menüden Analyze -> Nonparametric tests Chi Square’i seçin. Test değişkeni olarak öğrencinin ırkını seçin. Beklenen değerler olarak Values kısmına sırasıyla 10, 10, 10, 70 girin. OK’e tıklayın.

32
Sonucu :

33
Yorumu : Bu sonuçlar örneklemdeki öğrencilerin ırka göre dağılımının hipotezde öngörülen değerlerden farklı olmadığını göstermektedir. Gözlenen ve beklenen değerlerin birbirine yakın olduğunu ilk tablodan görebilirsiniz. (Sadece Asyalı öğrencilerin oranı beklenenden düşük.) Ki- kare ve p değeri de bunu gösteriyor (ki- kare=5,029; SD=3; p=0,170). Boş hipotez kabul edilir. Yazı içinde APA stiline göre gösterim: “Öğrencilerin ırka (Latin, Asyalı, Siyah ve Beyaz) göre dağılımı evrendeki dağılımdan – beklenen dağılım- farklı değildir (2(3)= 5,029, p = 0,170).”
 Ki- kare ve p değeri de bunu gösteriyor (ki- kare=5,029; SD=3; p=0,170). Boş hipotez kabul edilir. Yazı içinde APA stiline göre gösterim: Öğrencilerin ırka (Latin, Asyalı, Siyah ve Beyaz) göre dağılımı evrendeki dağılımdan – beklenen dağılım- farklı değildir (2(3)= 5,029, p = 0,170).")
34
Ki-kare Testi Ki- kare testi iki sınıflama değişkeni arasında ilişki olup olmadığını test etmek için kullanılır. Ki-kare test istatistiğini ve p değerini elde etmek için SPSS’de chi2 seçeneği tabulate komutuyla birlikte kullanılır. Hsb2turkce veri dosyasını kullanarak öğrencilerin gittiği okul türü (devlet/özel) ile cinsiyeti arasında bir ilişki olup olmadığını test edelim. Unutmayın, ki- kare testi her gözdeki beklenen değerin 5 veya daha fazla olduğunu varsayar. Bu örnekte bu koşul yerine getiriliyor. Koşul yerine getirilmezse Fisher kesin testi (Fisher’s exact test) kullanılır.
 ile cinsiyeti arasında bir ilişki olup olmadığını test edelim. Unutmayın, ki- kare testi her gözdeki beklenen değerin 5 veya daha fazla olduğunu varsayar. Bu örnekte bu koşul yerine getiriliyor. Koşul yerine getirilmezse Fisher kesin testi (Fisher’s exact test) kullanılır.")
35
Hipotezi ; Boş Hipotez (H0): “Öğrencilerin devam ettikleri okul türüyle (devlet/özel) cinsiyet arasında bir ilişki yoktur.” (birbirinden farklı değildir) Araştırma Hipotezi (H1): “Öğrencilerin devam ettikleri okul türüyle (devlet/özel) cinsiyet arasında bir ilişki vardır.” (çift kuyruk testi). H0 : ų = ų 0 H1 : ų ų 0 (çift kuyruk testi) Boş hipotezleri büyüktür/küçüktür diye de kurabilirsiniz. O zaman tek kuyruk (büyükse sol, küçükse sağ) test yapılır. Örneğin, H0 : “Kız öğrenciler devlet okullarını daha çok tercih etmektedirler.” H1: : “Kız öğrenciler devlet okullarını daha az tercih etmektedirler.” H0 : ų > ų 0 H1 : ų < ų 0 (sol kuyruk testi)
: Öğrencilerin devam ettikleri okul türüyle (devlet/özel) cinsiyet arasında bir ilişki yoktur. (birbirinden farklı değildir) Araştırma Hipotezi (H1): Öğrencilerin devam ettikleri okul türüyle (devlet/özel) cinsiyet arasında bir ilişki vardır. (çift kuyruk testi). H0 : ų = ų 0. H1 : ų ų 0 (çift kuyruk testi) Boş hipotezleri büyüktür/küçüktür diye de kurabilirsiniz. O zaman tek kuyruk (büyükse sol, küçükse sağ) test yapılır. Örneğin, H0 : Kız öğrenciler devlet okullarını daha çok tercih etmektedirler. H1: : Kız öğrenciler devlet okullarını daha az tercih etmektedirler. H0 : ų > ų 0. H1 : ų < ų 0 (sol kuyruk testi)")
36
Ki-kare Testi - Spss Mönüden
Analyze -> Descriptive statistics -> Crosstabs’i seçin Satıra okul türü, sütuna cinsiyeti yerleştirin. Statistics seçeneğine tıklayarak Chi square’i işaretleyin Cells seçeneğine tıklayarak Observed ve Expected’i işaretleyin. OK’e tıklayın

37
Sonucu :

38
Yorumu : İlk tabloda devlet okulu ve özel okula giden öğrencilerin cinsiyetlerine göre çapraz tablosu verilmiş. Gözlenen ve beklenen değerlerin birbirine çok yakın olduğunu görüyoruz. Ki- kare değeri de küçük ve istatistiksel açıdan anlamlı değil 2= 0,47, p = 0,849 Boş hipotez kabul edilir. “Öğrencilerin devam ettikleri okul ile cinsiyet arasında istatistiksel açıdan anlamlı bir ilişki yoktur (2= 0,47, p = 0,849).”
.")
39
Multiple Response Çoklu cevap yada çoklu ikili setlerin belirlenmesi ve analizi islemlerini yapar.

40
1.SORU: Çapraz tablolar ne için kullanılır ?
Çapraz tablolar temel olarak, iki değişken arasındaki ilişkiyi analiz etmek için kullanılır. Bu, araştırmacıya değişkenler arasındaki ilişkiyi ve ilgili her bir değişkenin kategorilerinin kesişimlerini inceleme olanağı sağlar. 2.SORU: Binom testinin ne için kullanıldığını kısaca yazınız. Tek örneklemli binom testi sınıflama ölçeğiyle veri toplanmış bağımlı değişken için kullanılır. Bağımlı değişken hakkındaki veriler iki düzeylidir (“binomial”; örneğin, cinsiyet için Erkek-Kadın biçiminde). Mevcut verilerin öngörülen bir sayıdan/yüzdeden farklı olup olmadığını test etmek için kullanılır. 3.SORU: Ki-Kare Uyum İyiliği Testi ne için kullanılır? Spss de nasıl uygulanır? Ki- kare uyum iyiliği testi bir sınıflama değişkeni için gözlenen oranların hipotezde iddia edilen oranlara uyup uymadığını test etmek için kullanılır. Kısaca Ki- kare testi iki sınıflama değişkeni arasında ilişki olup olmadığını test etmek için kullanılır. Analyze -> Nonparametric tests Chi Square’i seçin.
. Mevcut verilerin öngörülen bir sayıdan/yüzdeden farklı olup olmadığını test etmek için kullanılır. 3.SORU: Ki-Kare Uyum İyiliği Testi ne için kullanılır Spss de nasıl uygulanır Ki- kare uyum iyiliği testi bir sınıflama değişkeni için gözlenen oranların hipotezde iddia edilen oranlara uyup uymadığını test etmek için kullanılır. Kısaca Ki- kare testi iki sınıflama değişkeni arasında ilişki olup olmadığını test etmek için kullanılır. Analyze -> Nonparametric tests Chi Square’i seçin.")
Benzer bir sunumlar








>")










