Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
İrem Soydal ~ Yurdagül Ünal soydal@hacettepe.edu.trsoydal@hacettepe.edu.tr yurdagul@hacettepe.edu.tryurdagul@hacettepe.edu.tr

2
Bilgi erişim sistemlerinde kullanılan erişim kuralları (fonksiyonları/modelleri) kabaca üç başlık altında sınıflanabilir: ◦ Boole (kesin çakışma - exact match) Sorgu ve dizin terimleri arasında kesin eşleşme (exact match) gerektiren erişim fonksiyonları ◦ Vektör uzayı Sorgu ve dizin terimlerinin n-boyutlu bir uzaydaki vektörler olarak işlem gördüğü ve ağırlıklandırıldığı erişim fonksiyonu ◦ Olasılık kuramı Sorgu ve dizin terimlerinin olasılık kuramına göre ağırlıklandırılmasına dayalı erişim fonksiyonları
 kabaca üç başlık altında sınıflanabilir: ◦ Boole (kesin çakışma - exact match) Sorgu ve dizin terimleri arasında kesin eşleşme (exact match) gerektiren erişim fonksiyonları ◦ Vektör uzayı Sorgu ve dizin terimlerinin n-boyutlu bir uzaydaki vektörler olarak işlem gördüğü ve ağırlıklandırıldığı erişim fonksiyonu ◦ Olasılık kuramı Sorgu ve dizin terimlerinin olasılık kuramına göre ağırlıklandırılmasına dayalı erişim fonksiyonları")
3
Boole modelinin temel avantajı tasarımındaki basitlik. En önemli dezavantajı ise tam çakışma (exact match) erişim kuralının çok az ya da çok fazla sonuç getirebilecek olması. Benzerlik derecelendirmesi yok: sorgu ile belgenin ne kadar ilgili olduğunu gösteren bir skor değeri üretilmiyor bunun yerine ilgili / ilgisiz (1/0) yargısı var. Eşleştirmelerde terim ağırlıklandırma yok: bir belge içerisinde 1 kez geçen terimle 100 kez geçen terim aynı ağırlıkta, bu belge içeriğini ifade eden değerli terimleri seçmemizi engelliyor. Sorgu oluşturmak zor: kullanıcıların bilgi ihtiyaçlarını ifade edebilmek için karmaşık sorgular kurabilmesi gerekiyor. Hata toleransı yok: bilgi ihtiyacı tam ifade edilmek zorunda, yaklaşık sonuç alma olasılığı yok.
 erişim kuralının çok az ya da çok fazla sonuç getirebilecek olması. Benzerlik derecelendirmesi yok: sorgu ile belgenin ne kadar ilgili olduğunu gösteren bir skor değeri üretilmiyor bunun yerine ilgili / ilgisiz (1/0) yargısı var. Eşleştirmelerde terim ağırlıklandırma yok: bir belge içerisinde 1 kez geçen terimle 100 kez geçen terim aynı ağırlıkta, bu belge içeriğini ifade eden değerli terimleri seçmemizi engelliyor. Sorgu oluşturmak zor: kullanıcıların bilgi ihtiyaçlarını ifade edebilmek için karmaşık sorgular kurabilmesi gerekiyor. Hata toleransı yok: bilgi ihtiyacı tam ifade edilmek zorunda, yaklaşık sonuç alma olasılığı yok..")
4
Sorgu sonucu derecelendirilebiliyor Cosinüs ölçümüne göre her belgeye bir sorgu ile ilgili benzerlik değeri verilebiliyor Terim ağırlıklandırma ile sorgu sonucu elde edilen belgelerin kalitesini artırmak mümkün oluyor (yani daha başarılı bilgi erişim süreci) Hızlı ve etkin bir fonksiyon, hala popüler olarak kullanılıyor Terimleri birbirlerinden bağımsız görmesi dezavantajı (belgedeki kelimeler arası ilişkiler göz ardı ediliyor)
 Hızlı ve etkin bir fonksiyon, hala popüler olarak kullanılıyor Terimleri birbirlerinden bağımsız görmesi dezavantajı (belgedeki kelimeler arası ilişkiler göz ardı ediliyor)")
5
Olasılık modellerinde sorgu terimleri, kullanıcı geribildirimi aracılığı ile ilgili belgelerde bulunabilme olasılıkları temel alınarak ağırlıklandırılır; belge terimleri ise genellikle ikili ağırlıklandırılır (ilgili/ilgisiz – 1/0) Bir belgenin bir sorgu sonucunda ilgili olarak değerlendirilip değerlendirilemeyeceği ile ilgili bir çok model oluşturma teşebbüsü olmuştur Bu modeller erişilen belgeleri ilgililik olasılığına göre sıralamayı amaçlar. Buna olasılık sıralama prensibi (probability ranking principle) adı verilir Temeli, olasılığın doğru tahmin edilmesi ile ilgili bazı matematiksel formüllere dayanır
 adı verilir Temeli, olasılığın doğru tahmin edilmesi ile ilgili bazı matematiksel formüllere dayanır.")
6
Eğer bir erişim sisteminin her soruya verdiği yanıtlar koleksiyondaki belgelerin işe yararlık olasılığının azalan sırada dizilmesi şeklinde ise (ki burada sistemde tutulan belgelerin yapılan aramanın amacına ne kadar uygun olduğu ile ilgili olasılıklar mümkün olan en doğru şekilde tahmin edilmelidir), o zaman sistemde yer alan belgeler çerçevesinde sistemin kullanıcılarının gözündeki etkinliği en üst düzeyde olacaktır. Stephen E. Robertson, J. Documentation 1977

7
Bir kullanıcı kendi bilgi ihtiyacını kapsayan bazı özellikleri taşıyan Q sorgusunu sisteme yöneltti diyelim. Farklı kullanıcıların aynı ifadeyi kullanarak sorgu yöneltmesi onların başka kullanıcılarla aynı belgeyi ilgili olarak değerlendirecekleri anlamına gelmez. Bilgi erişim sisteminin görevi Q sorgusunu yönelten kullanıcıların sorguya karşılık gelecek olan her bir belgeyi ilgili olarak değerlendirip değerlendirmeyecekleri olasılığını hesaplamaktır. Robertson, Maron & Cooper, 1982

8
Belgelerin çok farklı özellikleri olabilir. Bazı belgeler kullanıcıların aradığı her özelliği karşılıyor olabilirken, bazı belgeler ise kısmen karşılıyor ya da hiç karşılamıyor olabilir. Sisteme sorgu yönelten kullanıcılar koleksiyonda yer alan tüm belgeleri değerlendirse bazıları, (aynı özellikleri taşıyan) belgeleri ilgili bazıları ise ilgisiz olarak değerlendirebilir. Bunun tam tersi de geçerlidir. Bir bilgi erişim sisteminin işlevi belgelerin aranılan belirli bir veya bir grup niteliğe göre ilgili olup olmama olasılığını hesaplamaktır. Robertson, Maron & Cooper, 1982
 belgeleri ilgili bazıları ise ilgisiz olarak değerlendirebilir. Bunun tam tersi de geçerlidir. Bir bilgi erişim sisteminin işlevi belgelerin aranılan belirli bir veya bir grup niteliğe göre ilgili olup olmama olasılığını hesaplamaktır. Robertson, Maron & Cooper,")
9
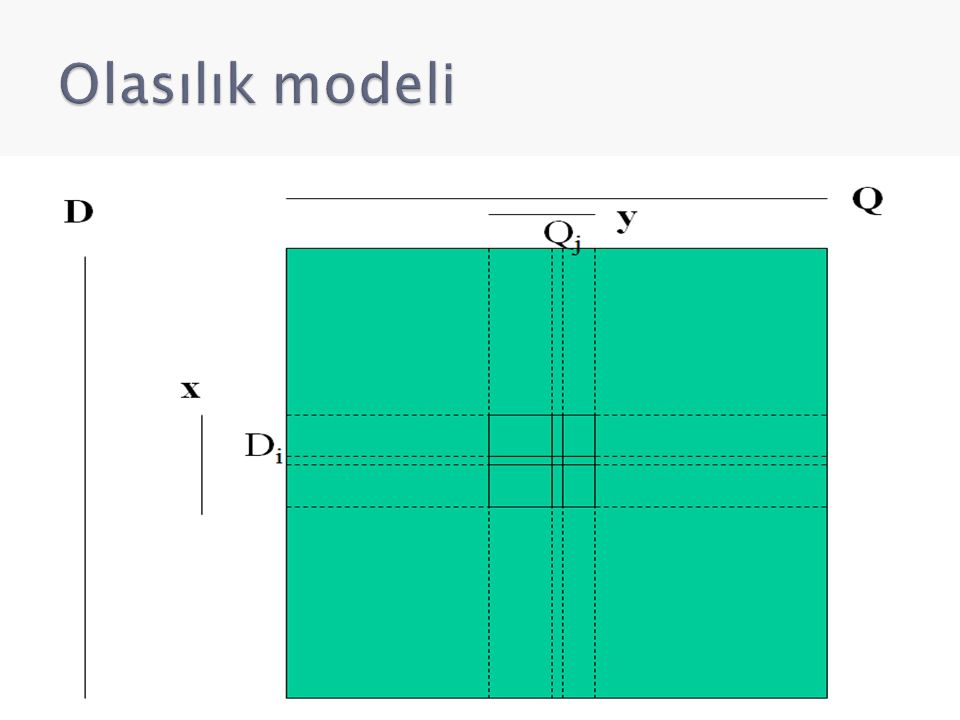
Olasılıklar öncelikli kullanım ya da ilgililik tahmini temel alınarak tahmin edilebilir ◦ D = Sistemde var olan ve gelecekte var olacak olan tüm belgeler ◦ Q = Halihazırda sisteme yöneltilmiş ve gelecekte yöneltilecek olan sorgular ◦ x = benzer belgeler sınıfı ◦ y = benzer sorgular sınıfı ◦ (Di,Qj) = Bir belge-sorgu çifti ◦ İlgililik (R) şöyle bir matematiksel ilişki ile temsil edilebilir: Buna göre Di i belgesi Q j sorgusunu yönelten kullanıcı tarafından ilgili olarak değerlendirilir.
 = Bir belge-sorgu çifti ◦ İlgililik (R) şöyle bir matematiksel ilişki ile temsil edilebilir: Buna göre Di i belgesi Q j sorgusunu yönelten kullanıcı tarafından ilgili olarak değerlendirilir.")
11
Avantaj ◦ Güçlü teorik temellere dayanır. ◦ Prensipte, var olan bilgi ile ilgili en iyi ilgililik tahminlerini sunacağı var sayılır. ◦ Tıpkı vektör uzayı modeli gibi uygulanabilir. Dezavantaj ◦ İlgili bilgilerin ne olduğunun bilinmesi gerekir – ya da net olarak tahmin edilmeli. ◦ İlgililiğin en temel göstergeleri terimler olmayabilir. Yine de çoğu zaman ilgililiğe yalnızca terimlere bakılarak karar verilebilir. ◦ Eklenen yeni belgelerin ilgililik değerlendirmesinin de sürekli olarak yapılmasını gerektirir.

12
Doğal dille yapılan sorguları destekler Belgelere ve sorgulara aynı şekilde davranır İlgililik geri bildirimi ile arama yapmayı destekler Sıralanmış sorgu sonuçları getirir Teorik temelleri ile sıralamanın nasıl hesaplanacağı konusunda birbirinden farklılık gösterir. Vektör modeli ilgililiği “varsayar” Olasılık modeli ilgililik değerlendirmeleri ya da tahminlerine dayanır.

13
(Relevance feedback)
")
16
“Users often input queries containing terms that do not match the terms used to index the majority of the relevant documents (either controlled or full text indexing) and almost always some of the unretrieved relevant documents are indexed by a different set of terms than those in the query or in most of the other relevant documents. This problem has long been recognized as a major difficulty in information retrieval systems (Lancaster 1969). More recently, van Rijsbergen (1986) spoke of the limits of providing increasingly better ranked results based solely on the initial query, and indicated a need to modify that query to further increase performance.”
. More recently, van Rijsbergen (1986) spoke of the limits of providing increasingly better ranked results based solely on the initial query, and indicated a need to modify that query to further increase performance. .")
17
Neden sorgu modifikasyonu? ◦ Kullanıcılar genellikle sorguları sonucunda bazı ilgili bilgilere ulaşırlar ama neredeyse asla sistemdeki “tüm” ilgili belgelere ulaşamazlar. ◦ Çoğu durumda bu kullanıcı için önemli değildir ancak sistemdeki tüm ilgili belgelere erişmenin kritik önem taşıdığı durumlarda kullanıcılar için nadiren daha fazla ilgili belgeye erişme yolu vardır.

18
◦ İlk seçenek olarak aramalarını “genişletirler” (expanding the search). ◦ Bu iş için genelde ya aradıkları terimin kavramsal olarak daha geniş olanını (broader term) kullanarak yeniden bir Boole sorgusu oluştururlar ya da ilk sorguları sonucunda elde ettikleri sıralanmış sonuç listesinde daha aşağılara bakarlar. Bu çoğu zaman boşuna bir çabadır. Çünkü genişletilmiş terimleri kullanarak yapılan Boole sorgusu çok fazla ilgisiz sonucu da beraberinde getirecektir. ◦ Kullanıcılar için ikinci seçenek orijinal sorgularını modifiye etmektir. Bu da genellikle rastgele bir işlemdir çünkü kullanıcı zaten muhtemelen bilgi ihtiyaçları ile ilgili orijinal sorguyu ilk tasarlarken zaten en iyi performanslarını sergilemişlerdir ve dolayısı ile hangi modifikasyonu yapsalar daha iyi sonuç elde edecekleri belirsizdir.
 kullanarak yeniden bir Boole sorgusu oluştururlar ya da ilk sorguları sonucunda elde ettikleri sıralanmış sonuç listesinde daha aşağılara bakarlar. Bu çoğu zaman boşuna bir çabadır. Çünkü genişletilmiş terimleri kullanarak yapılan Boole sorgusu çok fazla ilgisiz sonucu da beraberinde getirecektir. ◦ Kullanıcılar için ikinci seçenek orijinal sorgularını modifiye etmektir. Bu da genellikle rastgele bir işlemdir çünkü kullanıcı zaten muhtemelen bilgi ihtiyaçları ile ilgili orijinal sorguyu ilk tasarlarken zaten en iyi performanslarını sergilemişlerdir ve dolayısı ile hangi modifikasyonu yapsalar daha iyi sonuç elde edecekleri belirsizdir..")
19
Sorgu modifikasyon türleri ◦ Thesaurus açılımı: Sorgu terimlerine benzer terimler önerilir. ◦ İlgililik geri bildirimi: Sorgu sonucunda elde edilen ve ilgili olarak değerlendirilen belgelere benzer terim (ve belgeler) önerilir.
 önerilir..")
20
Temel amaç: ◦ Var olan sorguyu ilgililik değerlendirmelerine göre yeniden düzenlemek: ilgili belgelerdeki terimleri çıkar ve sorguya ekle, ve/veya sorguda olan terimleri yeniden ağırlıklandır. İki temel yaklaşım: ◦ Otomatik (“uydurma” (psuedo) ilgililik geribildirimi) ◦ Kullanıcıların seçtiği ilgili belgeler
 ilgililik geribildirimi) ◦ Kullanıcıların seçtiği ilgili belgeler.")
21
Genelde şu ikisi yapılır: ◦ Sorguyu yeni terimlerle genişlet ◦ Sorgudaki terimleri yeniden ağırlıklandır Farklı çeşitleri de var: ◦ İlgili belgeler için genelde pozitif ağırlık verilir ◦ İlgisiz belgeler için bazen negatif ağırlık verilir ◦ Yalnızca ilgisiz bulunan belgeler için dizin terimleri çıkarılır.

22
Alternatif kullanımları: ◦ Kullanıcılar arasında tercihleri sizinkine benzer olanları bulma. “Onların beğendiğini siz de beğenecek misiniz?” ◦ Sistemin arka planında kullanıcı hareketlerini izleme. “Bu, kullanıcıların gelecekte ne talep edeceklerini tahmin etmek için kullanılabilir mi?” ◦ Bir çok insanın ne yapmakta olduğunu. “Bu, tam anlamıyla insanlara göre neyin iyi neyin kötü olduğunu gösterir mi?”

23
Alternatif kullanım alanlarında çok fazla dikkate alınması gereken nokta var: ◦ Örtük / açık (implicit / explicit) değerlendirmeler. ◦ Bireysel / grup değerlendirmeleri ◦ Durağan /dinamik konu başlıkları ◦ Değerlendirilen belgelerin benzerliği / değerlendirenlerin benzerliği

24
“Ahmet bu makaleyi beğendiyse ben de beğenirim” “Eğer Yıldız Savaşları’nı sevdiysen, Kurtuluş Günü’nü de seversin” Bu örneklerde derecelendirme (rating) bezer insanlar tarafından yapılan sıralamalara dayanmaktadır. ◦ Sistemi halihazırda kullanan kullanıcılar gelecekteki kullanıcıların görüşlerini etkileyebilir.

25
Bu yapı içeriği bir tarafa bırakıp yalnızca değerlendiricilerin benzer düşüncelerine bakar. Beğenilere dayalı veriler söz konusu olduğunda sosyal filtreleme daha çok işe yarar.

26
Users rate musical artists from like to dislike ◦ 1 = detest 7 = can’t live without 4 = ambivalent ◦ There is a normal distribution around 4 However, what matters are the extremes Nearest Neighbors Strategy: Find similar users and predicted (weighted) average of user ratings ◦ Pearson r algorithm: weight by degree of correlation between user U and user J ◦ 1 means very similar, 0 means no correlation, -1 dissimilar ◦ Works better to compare against the ambivalent rating (4), rather than the individual’s average score
 average of user ratings ◦ Pearson r algorithm: weight by degree of correlation between user U and user J ◦ 1 means very similar, 0 means no correlation, -1 dissimilar ◦ Works better to compare against the ambivalent rating (4), rather than the individual’s average score")
27
Kullanıcı arayüzüne eklenen bazı uygulamalara (agents), bazı görevler atanır. Makine öğrenme (machine learning) teknikleri kullanılarak bilgi erişim performansının artırılması amaçlanır ◦ Kullanıcı davranışları ve tercihleri takip edilir. Öneri sistemleri (recommendation systems) geliştirilir. Şu durumlarda işe yarar: 1) Geçmiş davranışlar gelecekteki davranışların tahmin edilmesine yarar. 2) Çok farklı kullanıcı davranışı biçimlerini ortaya koyar. Örnekler: ◦ Posta düzenleyici: gelen postaları doğru klasörlere ya da posta kutularına gönderir ◦ Takvim yöneticisi: toplantı zamanlarını otomatik olarak ayarlar
 teknikleri kullanılarak bilgi erişim performansının artırılması amaçlanır ◦ Kullanıcı davranışları ve tercihleri takip edilir. Öneri sistemleri (recommendation systems) geliştirilir. Şu durumlarda işe yarar: 1) Geçmiş davranışlar gelecekteki davranışların tahmin edilmesine yarar. 2) Çok farklı kullanıcı davranışı biçimlerini ortaya koyar. Örnekler: ◦ Posta düzenleyici: gelen postaları doğru klasörlere ya da posta kutularına gönderir ◦ Takvim yöneticisi: toplantı zamanlarını otomatik olarak ayarlar.")
28
İlgililik geribildirimi kullanıcı-güdümlü (user- directed) sorgu modifikasyonlarında etkilidir. Modifikasyon doğrudan ya da dolaylı kullanıcı girdisi ile yapılabilir. Modifikasyon birey ya da grupların geçmiş girdileri temel alınarak yapılabilir.

29
Tonta, Y. (1995). Bilgi erişim sistemleri. (http://yunus.hacettepe.edu.tr/~soydal/bby156_2013/3/BilgiErisimSistemleri_tonta1995.pdf)http://yunus.hacettepe.edu.tr/~soydal/bby156_2013/3/BilgiErisimSistemleri_tonta1995.pdf Buckland, M. (1991). Information as thing. (http://people.ischool.berkeley.edu/~buckland/thing.html)http://people.ischool.berkeley.edu/~buckland/thing.html Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s.31-35. (Tam metin)Tam metin Diğer yardımcı kaynaklar: Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval. (Tam metin)Tam metin Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval. (Tam metin)Tam metin Bu derste kullanılan slaytların çoğunluğu Information organization and retrieval (R. Larson & W. Sack, 2001) Bilgi erişim ilkeleri (Y. Tonta, 2002) Bilgi erişim (G. Köse, 2012) derslerine ait slaytlardan derlenmiştir.
. Information as thing. ( Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s (Tam metin)Tam metin Diğer yardımcı kaynaklar: Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval. (Tam metin)Tam metin Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval. (Tam metin)Tam metin Bu derste kullanılan slaytların çoğunluğu Information organization and retrieval (R. Larson & W. Sack, 2001) Bilgi erişim ilkeleri (Y. Tonta, 2002) Bilgi erişim (G. Köse, 2012) derslerine ait slaytlardan derlenmiştir..")
Benzer bir sunumlar







 Kullanıcı Kılavuzu.>")













