Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
BBY 156 Bilgi Erişim 2014-2015 http://bby156. blogspot
BBY 156 Bilgi Erişim Belge işleme Bilgi erişim modelleri

2
Temel işlev (hatırlatma)
Bir bilgi erişim sisteminin temel işlevi, kullanıcıların bilgi ihtiyaçlarını karşılaması muhtemel, derlemdeki ilgili belgelerin tümüne erişmek, ilgili olmayanları da ayıklamaktır. İlgili: “Relevant” İlgililik: “Relevancy” Bir bilgi erişim sisteminin temel işlevi, kullanıcıların bilgi ihtiyaçlarını karşılaması muhtemel, derlemdeki ilgili belgelerin tümüne erişmek, ilgili olmayanları da ayıklamaktır. İlgili: “Relevant” İlgililik: “Relevancy”

3
İdeal bilgi erişim sistemi (hatırlatma)
İlgili belgelerin tümüne ve salt ilgili belgelere erişim sağlamak ! Birbirine benzeyen bilgileri bir araya getirmek, benzemeyenleri ayırmak İdeal bir bilgi erişim sistemi yaratmak neredeyse imkansız Milyonlarca kayıt / belge “ilgililik” kavramının öznelliği - İdeal bir bilgi erişim sistemi yaratmak neredeyse imkansız * Milyonlarca kayıt / belge - “ilgililik” kavramının öznelliği

4
Koşullar (hatırlatma)
Bir bilgi erişim sisteminde ihtiyaç duyulan belgelere erişmek için sistemin iki koşulu yerine getirmesi gerekir: 1) Derleme eklenen her belgenin temel özellikleri geleneksel veya otomatik olarak gerçekleştirilen dizinleme işlemleri sırasında belirlenmeli ve her belge için ilgili dizin terimleri oluşturulmalıdır. Bir belge için oluşturulan söz konusu dizin terimleri bilgi erişim sırasında belgenin tamamını temsil etmek üzere kullanılır. 2) Kullanıcılar belgelere verilen bu dizin terimlerini doğru olarak tahmin edip sorgu cümlelerini ona göre oluşturmalıdırlar. Bir başka deyişle, kullanıcının bilgi ihtiyacını ifade etmek için kullandığı terimlerle belgeyi temsil eden dizin terimleri birbiriyle karşılaştırılır ve çakışan belgelere erişilir. * Bir belge için oluşturulan söz konusu dizin terimleri bilgi erişim sırasında belgenin tamamını temsil etmek üzere kullanılır. * Bir başka deyişle, kullanıcının bilgi ihtiyacını ifade etmek için kullandığı terimlerle belgeyi temsil eden dizin terimleri birbiriyle karşılaştırılır ve çakışan belgelere erişilir.
 Derleme eklenen her belgenin temel özellikleri geleneksel veya otomatik olarak gerçekleştirilen dizinleme işlemleri sırasında belirlenmeli ve her belge için ilgili dizin terimleri oluşturulmalıdır. Bir belge için oluşturulan söz konusu dizin terimleri bilgi erişim sırasında belgenin tamamını temsil etmek üzere kullanılır. 2) Kullanıcılar belgelere verilen bu dizin terimlerini doğru olarak tahmin edip sorgu cümlelerini ona göre oluşturmalıdırlar. Bir başka deyişle, kullanıcının bilgi ihtiyacını ifade etmek için kullandığı terimlerle belgeyi temsil eden dizin terimleri birbiriyle karşılaştırılır ve çakışan belgelere erişilir. * Bir belge için oluşturulan söz konusu dizin terimleri bilgi erişim sırasında belgenin tamamını temsil etmek üzere kullanılır. * Bir başka deyişle, kullanıcının bilgi ihtiyacını ifade etmek için kullandığı terimlerle belgeyi temsil eden dizin terimleri birbiriyle karşılaştırılır ve çakışan belgelere erişilir.")
5
Temel bileşenler (hatırlatma)
Bir bilgi erişim sistemi: (1) bir belge derlemi ya da bu belgeleri temsil eden dizin terimlerini içeren kayıtlar, (2) kullanıcıların sorgu cümleleri, ve (3) kullanıcıların sorgu cümlelerinde yer alan terimlerle derlemdeki belgelere verilen terimleri karşılaştırarak ilgili belgeleri belirlemek için kullanılan bir erişim kuralından oluşur. Bir bilgi erişim sistemi: (1) bir belge derlemi ya da bu belgeleri temsil eden dizin terimlerini içeren kayıtlar, (2) kullanıcıların sorgu cümleleri, ve (3) kullanıcıların sorgu cümlelerinde yer alan terimlerle derlemdeki belgelere verilen terimleri karşılaştırarak ilgili belgeleri belirlemek için kullanılan bir erişim kuralından oluşur.
 bir belge derlemi ya da bu belgeleri temsil eden dizin terimlerini içeren kayıtlar, (2) kullanıcıların sorgu cümleleri, ve. (3) kullanıcıların sorgu cümlelerinde yer alan terimlerle derlemdeki belgelere verilen terimleri karşılaştırarak ilgili belgeleri belirlemek için kullanılan bir erişim kuralından. oluşur. Bir bilgi erişim sistemi: (1) bir belge derlemi ya da bu belgeleri temsil eden dizin terimlerini içeren kayıtlar, (2) kullanıcıların sorgu cümleleri, ve. (3) kullanıcıların sorgu cümlelerinde yer alan terimlerle derlemdeki belgelere verilen terimleri karşılaştırarak ilgili belgeleri belirlemek için kullanılan bir erişim kuralından. oluşur.")
6
Belge işleme: Belgelerden dizin terimi yaratma süreci ..
Tipik bir bilgi erişim sisteminde belgeler “terim”ler (dizin terimleri) ile gösterilir. Bu terimler her zaman sadece dizinleme yapan uzmanın seçtiği dizin terimleri/kontrollü anahtar sözcüklerden oluşmaz. Doğal dille dizinleme yapan bilgi erişim sistemleri de vardır. Özellikle derlemdeki belgelerin tam metinlerinin dizinlenmesi, otomatik olarak gerçekleştirilmesi gereken bir süreçtir. Bir derlemdeki belgelerden “terim” elde etmek için genelde şu aşamalar gerçekleştirilir: Harf olmayan karakterler boşluklarla yer değiştirilir Tek harfli sözcükler silinir Bütün karakterler küçük harfli yapılır “Durma listesi”nde (stop words/list) geçen sözcükler silinir Sözcükler gövdelenir (stemming) Tek karakterli gövdeler atılır Kaynak: Tonta, Bitirim & Sever (2002), s.16
 ile gösterilir. Bu terimler her zaman sadece dizinleme yapan uzmanın seçtiği dizin terimleri/kontrollü anahtar sözcüklerden oluşmaz. Doğal dille dizinleme yapan bilgi erişim sistemleri de vardır. Özellikle derlemdeki belgelerin tam metinlerinin dizinlenmesi, otomatik olarak gerçekleştirilmesi gereken bir süreçtir. Bir derlemdeki belgelerden terim elde etmek için genelde şu aşamalar gerçekleştirilir: Harf olmayan karakterler boşluklarla yer değiştirilir. Tek harfli sözcükler silinir. Bütün karakterler küçük harfli yapılır. Durma listesi nde (stop words/list) geçen sözcükler silinir. Sözcükler gövdelenir (stemming) Tek karakterli gövdeler atılır. Kaynak: Tonta, Bitirim & Sever (2002), s.16.")
7
.. Belge işleme: Belgelerden dizin terimi yaratma süreci ..
Son adımdan sonra elde edilen listedeki yüksek sıklıklı sözcükler terim sözlüğünden çıkarılır ve böylece derleme duyarlı ikinci bir durma listesi oluşturulur. Bu isteğe bağlı gerçekleştirilen bir adımdır. Derlemde geçen tamlamaların (phrase) dizin terimlerine eklenebilmesi için sistemde sık olarak beraber geçen kelimeler belirlenir. Bu da isteğe bağlı bir adımdır. Tamlama oluşturma/belirleme işleminde kelime çiftleri teker teker ayıklanarak sıklıkları bulunur ve en en sık kullanılan N tane phrase (ya da oluşan tamlamaların tamamı) dizin terimleri (terim sözlüğü) arasına eklenir. Tamlamalar, yüksek ve orta sıklıklı sözcükler ayrı ayrı olarak terim sözlüğüne otomatik olarak eklenir. Tüm bu işlemler sırasında eşanlamlı sözcükler de terim listesi içinde tanımlanır. Bu süreç, belge işleme (document processing) ya da ön işleme (pre- processing) olarak tanımlanır. Kaynak: Tonta, Bitirim & Sever (2002), s.16
 dizin terimlerine eklenebilmesi için sistemde sık olarak beraber geçen kelimeler belirlenir. Bu da isteğe bağlı bir adımdır. Tamlama oluşturma/belirleme işleminde kelime çiftleri teker teker ayıklanarak sıklıkları bulunur ve en en sık kullanılan N tane phrase (ya da oluşan tamlamaların tamamı) dizin terimleri (terim sözlüğü) arasına eklenir. Tamlamalar, yüksek ve orta sıklıklı sözcükler ayrı ayrı olarak terim sözlüğüne otomatik olarak eklenir. Tüm bu işlemler sırasında eşanlamlı sözcükler de terim listesi içinde tanımlanır. Bu süreç, belge işleme (document processing) ya da ön işleme (pre- processing) olarak tanımlanır. Kaynak: Tonta, Bitirim & Sever (2002), s.16.")
8
Belge işleme adımları (document processing steps)
Kaynak: Hearst, M & Larson, R. (2001), Lecture-4_202
, Lecture-4_202.")
9
Belgelerden durma listesi (stop words) çıkarma
Kaynak: Hearst, M & Larson, R. (2001)
")
10
Belgeler için gövdeleme (stemming) ve morfolojik analiz
Hedef: benzer sözcükleri “normalize” etmek Morphology (sözcüklerin “biçim”i) Çekim ekleri (inflectional morphology) Çekim ekleri atılırken sözcüklerin dilbilgisel (grammatical) sınıfı asla bozulmaz dog, dogs ben, benim, bende, benden, .. Yapım ekleri (derivational morphology) Bir sözcükten başka bir sözcük türetme Genelde sözcüklerin dilbilgisel sınıfı değişir build, building; health, healthy; kütüphane, kütüphaneci, kütüphanecilik Özellikle İngilizce için morfolojik analiz ve gövdelemeyi otomatik olarak gerçekleştiren başarılı sayılabilecek yazılımlar var (örn. Lucene). Türkçe gibi sondan eklemeli dillerde gövdeleme önemli ve otomatik gövdeleme yazılımlarının geliştirilmesine ihtiyaç var. Dil yapılarındaki farklılıklar nedeniyle her dil için farklı bir algoritma geliştirilmesi gerekiyor. Örneğin “Zemberek” adlı yazılım Türkçe için kullanılan gövdeleme araçlarından biri. - Çekim ekleri (inflectional morphology) * Çekim ekleri atılırken sözcüklerin dilbilgisel (grammatical) sınıfı asla bozulmaz * dog, dogs * ben, benim, bende, benden, .. - Yapım ekleri (derivational morphology) * Bir sözcükten başka bir sözcük türetme * Genelde dilbilgisel sınıfı değişir * build, building; health, healthy; kütüphane, kütüphaneci, kütüphanecilik -- Özellikle Türkçe gibi sondan eklemeli dillerde gövdeleme önemli ve otomatik gövdeleme yazılımlarının geliştirilmesine ihtiyaç var. - Dil yapılarındaki farklılıklar nedeniyle her dil için farklı bir algoritma geliştirilmesi gerekiyor. Örneğin “Zemberek” adlı yazılım Türkçe için kullanılan gövdeleme araçlarından biri. Kaynak: Hearst, M & Larson, R. (2001), Lecture-4_202
 Çekim ekleri (inflectional morphology) Çekim ekleri atılırken sözcüklerin dilbilgisel (grammatical) sınıfı asla bozulmaz. dog, dogs. ben, benim, bende, benden, .. Yapım ekleri (derivational morphology) Bir sözcükten başka bir sözcük türetme. Genelde sözcüklerin dilbilgisel sınıfı değişir. build, building; health, healthy; kütüphane, kütüphaneci, kütüphanecilik. Özellikle İngilizce için morfolojik analiz ve gövdelemeyi otomatik olarak gerçekleştiren başarılı sayılabilecek yazılımlar var (örn. Lucene). Türkçe gibi sondan eklemeli dillerde gövdeleme önemli ve otomatik gövdeleme yazılımlarının geliştirilmesine ihtiyaç var. Dil yapılarındaki farklılıklar nedeniyle her dil için farklı bir algoritma geliştirilmesi gerekiyor. Örneğin Zemberek adlı yazılım Türkçe için kullanılan gövdeleme araçlarından biri. - Çekim ekleri (inflectional morphology) * Çekim ekleri atılırken sözcüklerin dilbilgisel (grammatical) sınıfı asla bozulmaz. * dog, dogs. * ben, benim, bende, benden, .. - Yapım ekleri (derivational morphology) * Bir sözcükten başka bir sözcük türetme. * Genelde dilbilgisel sınıfı değişir. * build, building; health, healthy; kütüphane, kütüphaneci, kütüphanecilik. -- Özellikle Türkçe gibi sondan eklemeli dillerde gövdeleme önemli ve otomatik gövdeleme yazılımlarının geliştirilmesine ihtiyaç var. - Dil yapılarındaki farklılıklar nedeniyle her dil için farklı bir algoritma geliştirilmesi gerekiyor. Örneğin Zemberek adlı yazılım Türkçe için kullanılan gövdeleme araçlarından biri. Kaynak: Hearst, M & Larson, R. (2001), Lecture-4_202.")
11
İngilizce için otomatik gövdeleme hatalarına örnek
Kaynak: Hearst, M & Larson, R. (2001), Lecture-4_202 * Her ne kadar milyonlarca belgenin otomatik olarak gövdelenebilmesi bilgi erişim açısından vaz geçilmez bir öneme sahip olsa da, otomatik gövdeleme sistemlerinin sürekli iyileştirilmeye ihtiyacı var. * Otomatik gövdeleme yazılımları kimi zaman İngilizce metinler için bile mükemmel performans sergileyemiyor. * Bunun için gövdeleme (stemming) yerine «lemmatization» (kök çözümleme) yapan yazılımlar üretilmeye başlandı. * Kök çözümleme sayesinde kelimeler bağlam içerisinde kullanımlarına göre birleştirilebiliyor: Örn: good - best good / best => ? «Lemmatisation»
, Lecture-4_202. * Her ne kadar milyonlarca belgenin otomatik olarak gövdelenebilmesi bilgi erişim açısından vaz geçilmez bir öneme sahip olsa da, otomatik gövdeleme sistemlerinin sürekli iyileştirilmeye ihtiyacı var. * Otomatik gövdeleme yazılımları kimi zaman İngilizce metinler için bile mükemmel performans sergileyemiyor. * Bunun için gövdeleme (stemming) yerine «lemmatization» (kök çözümleme) yapan yazılımlar üretilmeye başlandı. * Kök çözümleme sayesinde kelimeler bağlam içerisinde kullanımlarına göre birleştirilebiliyor: Örn: good - best. good / best => «Lemmatisation»")
12
Türkçe için otomatik gövdeleme hatalarına örnek
Metnin orijinal hali: Üründen çok memnun olmadım. Durma sözcükleri atıldıktan ve “Zemberek” ile gövdeleme yapıldıktan sonraki hali: ürün memnun ol “Türkçe’nin dil yapısında olan olumsuzluk ekleri dolayısıyla stemming uygulamalarında hatalarla karşılaşılmıştır. Kök bulma algoritmaları –me , –ma olumsuzluk eklerini kök dışına attığında cümlenin olumluluk durumunu kıyaslamakta zorlanıyoruz. Gövdeleme sonucunda cümle yüklemi kök halinde bırakılır. Normalde olumsuz olan cümlemiz bu haliyle olumlu görünmektedir. Olumsuzluğu sağlayan “-ma” eki atılmıştır. Bu nedenle Türkçede bu aşamada karmaşıklık yaşanabilir. İngilizce de olumsuzluk “not” eki ile sağlandığı için böyle bir durumla karşılaşılmamaktadır.” «ürün memnun ol» “Türkçe’nin dil yapısında olan olumsuzluk ekleri dolayısıyla stemming uygulamalarında hatalarla karşılaşılmıştır. Kök bulma algoritmaları –me , –ma olumsuzluk eklerini kök dışına attığında cümlenin olumluluk durumunu kıyaslamakta zorlanıyoruz. Gövdeleme sonucunda cümle yüklemi kök halinde bırakılır. Normalde olumsuz olan cümlemiz bu haliyle olumlu görünmektedir. Olumsuzluğu sağlayan “-ma” eki atılmıştır. Bu nedenle Türkçede bu aşamada karmaşıklık yaşanabilir. İngilizce de olumsuzluk “not” eki ile sağlandığı için böyle bir durumla karşılaşılmamaktadır.” Kaynak: Eren, Utku, Çavuşlar (2013), s ( *** Yaşanan bu sorun örneğin “bir ürün hakkında yapılan olumsuz yorumların analizi” gibi bir işlemde hatalı veriler elde edilmesine neden olacaktır. Yaşanan bu sorun, örneğin, “bir ürün hakkında yapılan olumsuz yorumların analizi” gibi bir işlemde hatalı veriler elde edilmesine neden olacaktır. Kaynak: Eren, Utku, Çavuşlar (2013), s.20-21
, s ( *** Yaşanan bu sorun örneğin bir ürün hakkında yapılan olumsuz yorumların analizi gibi bir işlemde hatalı veriler elde edilmesine neden olacaktır. Yaşanan bu sorun, örneğin, bir ürün hakkında yapılan olumsuz yorumların analizi gibi bir işlemde hatalı veriler elde edilmesine neden olacaktır. Kaynak: Eren, Utku, Çavuşlar (2013), s")
13
Belge işleme süreci sonunda elde edilen terimler
Bütün bu aşamalardan geçip otomatik olarak oluşturulmuş sözcüklere “terim” (dizin terimi) denir. Terimler hem belgeleri göstermede (belge/dizin terimleri) hem de sorguları ifade etmede (sorgu terimleri) kullanılır.
 denir. Terimler hem belgeleri göstermede (belge/dizin terimleri) hem de sorguları ifade etmede (sorgu terimleri) kullanılır.")
14
Kümeleme yöntemi «Erişim kuralı»nın uygulanmasından önce tüm ilgili belgelere ulaşmak için sorgu cümlesinin sadece benzer kümelerle karşılaştırılması işlemi Bilgi erişim deneyleri göstermiştir ki erişimden önce belgelerin kümelenmesi/sınıflandırması daha isabetli/ilgili sonuçlara erişilebilmesi için daha etkili bir yöntemdir. Eğer birbirine konu yönünden benzer belgeler kümelenebilirse, dermedeki tüm ilgili belgelere erişebilmek için sorgu cümlesinin gösterimiyle sadece benzer kümelerin gösterimlerini karşılaştırmak yeterlidir.. Dolayısıyla sorgu cümlesinin gösterimi ile dermedeki her bir belgeyi karşılaştırmak gerekmeyecektir. Kümeleme= Daha az işlem daha hızlı sonuç Küme sayısı= kümeleme formülü Bir dermede bulunan küme sayısı kullanılan kümeleme formülüne bağlıdır. Kümeleme nesneleri: Konu başlıkları, Kitap adları, Tam metin … vb. * Erişim kuralının uygulanmasından önce gelen yöntem “kümeleme yöntemi” * Bilgi erişim deneyleri göstermiştir ki erişimden önce belgelerin kümelenmesi/sınıflandırması daha isabetli/ilgili sonuçlara erişilebilmesi için daha etkili bir yöntemdir. * Eğer birbirine konu yönünden benzer belgeler kümelenebilirse, dermedeki tüm ilgili belgelere erişebilmek için sorgu cümlesinin gösterimiyle sadece benzer kümelerin gösterimlerini karşılaştırmak yeterlidir. * Dolayısıyla sorgu cümlesinin gösterimi ile dermedeki her bir belgeyi karşılaştırmak gerekmeyecek * Yani: Daha az işlem, daha hızlı sonuç. * Belli bir dermede bulunan küme sayısı kullanılan kümeleme formülüne bağlıdır. * Belge kümeleme, kümelenecek belgeler arasındaki benzerliğin ölçülmesine dayanır. * Başlıklardaki terimler, konu başlıkları, vb. alanlar belgelerin tam metinleri kümeleme için sık kullanılan “nesneler”.

15
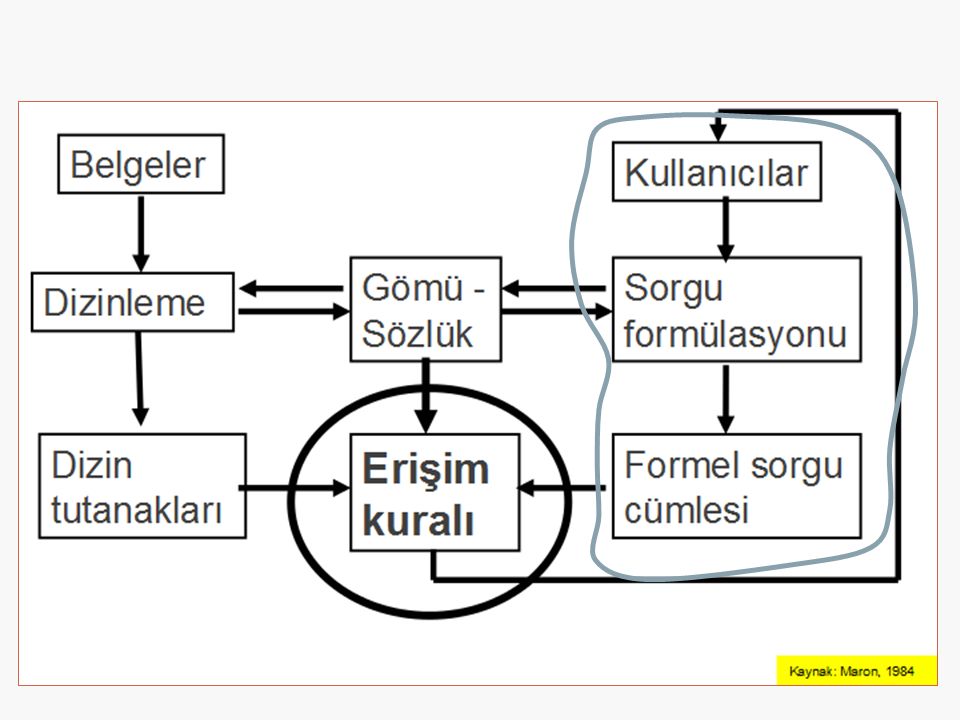
Belge erişim sisteminin mantıksal düzenlemesi
Belge işleme (document processing)
")
16
Erişim kuralı Bir bilgi erişim sisteminde temel nokta:
Kullanıcının girdiği sorgulama terimlerinin, erişim için sistem tarafından yorumlanması. Sorgu cümlelerindeki terimlerle belgelerin dizin kayıtlarındaki terimler karşılaştırılır. Arama sonucunun kalitesi büyük ölçüde çakışma işleminde kullanılan erişim kurallarına bağlıdır. Hangi kayıtlara erişilip/erişilmeyeceğini erişim kuralı belirler. ** Bir Bilgi Erişim Sisteminde belirleyici olan nokta kullanıcının girdiği sorgulama terimlerinin, erişim için sistem tarafından yorumlanmasıdır. ** Sorgu cümlelerindeki terimlerle belgelerin dizin kayıtlarındaki terimler karşılaştırılır. ** Arama sonucunun kalitesi büyük ölçüde bu çakışma işleminde kullanılan erişim kurallarına bağlıdır. Hangi kayıtlara erişilip hangilere erişilmeyeceğini kullanılan erişim kuralı belirler.

17
Temel erişim kuralları (modeller)
Sorgu cümlesindeki terimlerle dizin terimleri arasında kesin çakışma (exact match) gerektiren erişim kuralları ve Boole erişim kuralları Olasılık kuramına dayalı erişim kuralları Vektör uzayı modeli Sorgu cümlesi ile dizin terimi arasında çakışma olup olmadığını belirlemek için kullanılan birçok erişim kuralı vardır (Blair (1990) 12 değişik erişim kuralı/modeli listelemektedir, ayrıntılı bilgi için bkz. Tonta, 1995, p.309). - Bu 12 model 3 grupta toplanabilir. - İlki sorgu cümlesindeki terimlerle dizin terimleri arasında kesin çakışma (exact match) gerektiren erişim kuralları ve boole erişim kuralları, - ikincisi olasılık kuramına dayalı erişim kuralları, - üçüncüsü ise vektör uzayı modeli.
 gerektiren erişim kuralları ve Boole erişim kuralları. Olasılık kuramına dayalı erişim kuralları. Vektör uzayı modeli. Sorgu cümlesi ile dizin terimi arasında çakışma olup olmadığını belirlemek için kullanılan birçok erişim kuralı vardır (Blair (1990) 12 değişik erişim kuralı/modeli listelemektedir, ayrıntılı bilgi için bkz. Tonta, 1995, p.309). - Bu 12 model 3 grupta toplanabilir. - İlki sorgu cümlesindeki terimlerle dizin terimleri arasında kesin çakışma (exact match) gerektiren erişim kuralları ve boole erişim kuralları, - ikincisi olasılık kuramına dayalı erişim kuralları, - üçüncüsü ise vektör uzayı modeli.")
18
Kesin çakışma/Boole modeli ..
Sorgu cümlesindeki terimler ve dizin terimleri ikilidir. Bir terim sorgu cümlesinde ya da belgenin dizin kaydında ya vardır ya yoktur. Erişim için her terim eşit derecede önem taşır. Sorgu cümlesindeki terimler kavramsal dizinlerden (tezarus) alınan ilgili terimlerle genişletilebilir. * Sorgu cümlesindeki terimler ve dizin terimleri ikilidir. * Bir terim sorgu cümlesinde ya da belgenin dizin kaydında ya vardır ya yoktur. * Erişim için her terim eşit derecede önem taşır. * Sorgu cümlesindeki terimler kavramsal dizinlerden alınan ilgili terimlerle genişletilebilir.
 alınan ilgili terimlerle genişletilebilir. * Sorgu cümlesindeki terimler ve dizin terimleri ikilidir. * Bir terim sorgu cümlesinde ya da belgenin dizin kaydında ya vardır ya yoktur. * Erişim için her terim eşit derecede önem taşır. * Sorgu cümlesindeki terimler kavramsal dizinlerden alınan ilgili terimlerle genişletilebilir.")
19
.. Kesin çakışma/Boole modeli
Genellikle erişilen kayıtlar kabaca “erişildi” (1) / “erişilmedi” (0) mantığına göre sıralanabilir. Ya da erişilen kayıtlar sorgu cümlesinde ve dizin kaydında mevcut çakışan terim sayısına göre sıralanabilir. Boole modelinde erişim fonksiyonu ikili mantıkla çalıştığı için erişim çıktısındaki belgelerde mantıksal ilgililiği temel alan bir sıralama mantığı yoktur (Salton, 1989). Erişim çıktısının en başında yer alan belgeyle en sonunda yer alan belge aynı erişim değerine sahiptir. Boole sorgusundan tam olarak ne istenildiğini sistemin anlaması kolay olmayabilir. Çok fazla da sonuç gelebilir çok az da. Bu dezavantajlarına rağmen sorgular basittir ve bilgi erişim sisteminin mimarisi bu mantığa göre çok hızlı ve kolaylıkla inşa edilebilir. Erişilen kayıtlar kabaca erişildi erişilmedi şeklinde sıralanabilir. Ya da erişilen kayıtlar sorgu cümlesinde ve dizin kaydında mevcut çakışan terim sayısına göre sıralanabilir. Boole modelinde erişim fonksiyonu ikili mantıkla çalıştığı için erişim çıktısındaki belgelerde sıralama yoktur (Salton, 1989). Yani erişim çıktısının en başında yer alan belgeyle en sonunda yer alan belge aynı erişim değerine sahiptir. Fakat ayrıca kullanılacak bazı algoritmalar ile, ki pek çok arama motoru bunu yapmaktadır, Boole mantığı ile de sıralama yapmak mümkündür. Advantages simple queries relatively easy to implement Disadvantages difficult to specify what is wanted too much returned, or too little ordering not well determined Dominant language in commercial systems until the WWW
 / erişilmedi (0) mantığına göre sıralanabilir. Ya da erişilen kayıtlar sorgu cümlesinde ve dizin kaydında mevcut çakışan terim sayısına göre sıralanabilir. Boole modelinde erişim fonksiyonu ikili mantıkla çalıştığı için erişim çıktısındaki belgelerde mantıksal ilgililiği temel alan bir sıralama mantığı yoktur (Salton, 1989). Erişim çıktısının en başında yer alan belgeyle en sonunda yer alan belge aynı erişim değerine sahiptir. Boole sorgusundan tam olarak ne istenildiğini sistemin anlaması kolay olmayabilir. Çok fazla da sonuç gelebilir çok az da. Bu dezavantajlarına rağmen sorgular basittir ve bilgi erişim sisteminin mimarisi bu mantığa göre çok hızlı ve kolaylıkla inşa edilebilir. Erişilen kayıtlar kabaca erişildi erişilmedi şeklinde sıralanabilir. Ya da erişilen kayıtlar sorgu cümlesinde ve dizin kaydında mevcut çakışan terim sayısına göre sıralanabilir. Boole modelinde erişim fonksiyonu ikili mantıkla çalıştığı için erişim çıktısındaki belgelerde sıralama yoktur (Salton, 1989). Yani erişim çıktısının en başında yer alan belgeyle en sonunda yer alan belge aynı erişim değerine sahiptir. Fakat ayrıca kullanılacak bazı algoritmalar ile, ki pek çok arama motoru bunu yapmaktadır, Boole mantığı ile de sıralama yapmak mümkündür. Advantages. simple queries. relatively easy to implement. Disadvantages. difficult to specify what is wanted. too much returned, or too little. ordering not well determined. Dominant language in commercial systems until the WWW.")
20
Boole Modeli Özellikler ve kullanılan işleçler (haftaya)
")
22
Kullanıcı bakış açısından BES kullanımı
Bilgi erişim sistemlerinde arama stratejisi nasıl planlanır: Arama terimleri belirlenir. Arama sınırlandırılır (kaynak türü, yıl, vb.). Kesme/joker (truncation/wildcards) kullanımı, tamlamalar, vb. alternatifler belirlenir ve arama yapılacak bilgi erişim sisteminin özelliklerine göre ilgili karakterler kullanılır. Terimler uygun şekilde birbirine bağlanır (Boole mantığı). Terimler diğer bilgi erişim sisteminin sunduğu diğer bağlayıcılar (connectors) ile birbirine bağlanır. Ayrıntılar için bkz. Rumsey, S. (2008). How to Find Information: A guide for researchers (Chpt.6, p.49-79). (kaynağı benden alabilirsiniz)
. Kesme/joker (truncation/wildcards) kullanımı, tamlamalar, vb. alternatifler belirlenir ve arama yapılacak bilgi erişim sisteminin özelliklerine göre ilgili karakterler kullanılır. Terimler uygun şekilde birbirine bağlanır (Boole mantığı). Terimler diğer bilgi erişim sisteminin sunduğu diğer bağlayıcılar (connectors) ile birbirine bağlanır. Ayrıntılar için bkz. Rumsey, S. (2008). How to Find Information: A guide for researchers (Chpt.6, p.49-79). (kaynağı benden alabilirsiniz)")
23
Online arama yapma süreci
Ayrıntılar için bkz. Rumsey, S. (2008). How to Find Information: A guide for researchers (Chpt.6, p.49-79). (kaynağı benden alabilirsiniz) (Rumsey, 2008, p.53)
. How to Find Information: A guide for researchers (Chpt.6, p.49-79). (kaynağı benden alabilirsiniz) (Rumsey, 2008, p.53)")
24
Geniş (broader) ve dar (narrower) terimlere karar verme
Ayrıntılar için bkz. Rumsey, S. (2008). How to Find Information: A guide for researchers (Chpt.6, p.49-79). (kaynağı benden alabilirsiniz)
. How to Find Information: A guide for researchers (Chpt.6, p.49-79). (kaynağı benden alabilirsiniz)")
25
Ödev ! H.Ü. Kütüphanelerinin abone olduğu
Academic Search Complete – EBSCOHost GALE Virtual Reference Library ScienceDirect adlı veri tabanlarının «help» kısımlarına girin ve bu veri tabanlarının arama özelliklerini inceleyin: Veri tabanlarının arama özelliklerinde ne gibi farklılıklar var? «Wildcard», «truncation», «joker», «nesting», «phrase», vb. arama özellikleri ne işe yarıyor? Bunlar için kullanılan operatörler veri tabanları arasında değişiklik gösteriyor mu? Özellikle ScienceDirect veri tabanının farklı arama operatörleri neler, ne amaçla kullanılıyor?

26
Okuma listesi Rumsey, S. (2008). How to Find Information: A guide for researchers (Chpt.6, p.49-79). (kaynağı benden alabilirsiniz) Tonta, Y. (1995). Bilgi erişim sistemleri. ( Sistemleri_tonta1995.pdf) Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s (Tam metin) Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval, s (Tam metin) Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval, s.3-10 & (Tam metin)
. Bilgi erişim sistemleri. ( Sistemleri_tonta1995.pdf) Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s (Tam metin) Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval, s (Tam metin) Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval, s.3-10 & (Tam metin)")
Benzer bir sunumlar










 NASIL OLMALIDIR?>")





 Kullanıcı Kılavuzu.>")


