Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
Bağımlı Kukla Değişkenler
Bağımlı değişken özünde iki değer alabiliyorsa yani bir özelliğin varlığı ya da yokluğu söz konusu ise bu durumda bağımlı kukla değişkenler söz konusudur. Bu durumdaki modelleri tahmin etmek için dört yaklaşım vardır: -Doğrusal Olasılık Modeli -Logit Modeli -Probit Modeli -Tobit Modeli

2
Doğrusal Olasılık Modeli
Yi = b1 + b2Xi +ui Yi= 1 Eğer i. Birey istenen özelliğe sahipse 0 Diğer Durumlarda Xi= Bağımsız değişken Bu modele olasılıklı model denmesinin nedeni, Y’nin X için şartlı beklenen değerinin, Y’nin X için şartlı olasılığına eşit olmasıdır. E(Yi|Xi)=Pr(Yi=1| Xi)
=Pr(Yi=1| Xi)")
3
Doğrusal Olasılık Modeli
E(Yi |Xi)= b1 + b2Xi E(ui) = 0 Yi değişkeninin olasılık dağılımı: Yi Olasılık 0 1-Pi 1 Pi Toplam 1 E(Yi |Xi) = SYiPi=0.(1-Pi) + 1.(Pi) = Pi E(Yi |Xi)= b1 + b2Xi 0 E(Yi |Xi) 1
= b1 + b2Xi. E(ui) = 0. Yi değişkeninin olasılık dağılımı: Yi Olasılık. 0 1-Pi. 1 Pi. Toplam 1. E(Yi |Xi) = SYiPi=0.(1-Pi) + 1.(Pi) = Pi. E(Yi |Xi)= b1 + b2Xi. 0 E(Yi |Xi) 1.")
4
DOM Tahminindeki Sorunlar
ui hata teriminin normal dağılmayışı: Normallik varsayımının sağlanmaması durumunda tahmin ediciler sapmasızlıklarını korurlar. Nokta tahminde normallik varsayımı gözardı edilir. Örnek hacmi sonsuza giderken EKK tahmincileri çoğunlukla normal dağılıma uyarlar. DOM ile yapılan istatistiksel çıkarsamalar normallik varsayımı altındaki EKK sürecine uyarlar.

5
u’ların Binom Dağılımlı Olması
EKKY varsayımlarından biri u değerlerinin dağılımının normal olmasıdır. Bu varsayım sayesinde katsayı tahminlerinin güven aralıkları hesaplanıp, test yapılabilmektedir. DOM’de u’lar normal dağılmaz, binom dağılımı gösterir: Y ve 0 değerini aldığında Yi =1 için Yi =0 için u lar normal değildir. İki değerli binom dağılımlıdır. Ancak büyük örneklerde DOM güven aralıkları ve hipotez testleri geçerlidir ve EKKY normal dağılım varsayımının sağlandığı kabul edilmektedir.

6
ui hata teriminin değişen varyanslı olması:
DOM’de u lar eşit varyanslı değillerdir. Bunun için kesikli bir Y değişkeni varyansından hareketle Y yerine u alınarak Yi ui İhtimal=P(ui) -b1-b2X (1-Pi) 1 1-b1-b2X Pi
 -b1-b2X. (1-Pi) 1. 1-b1-b2X. Pi.")
7
ui hata teriminin değişen varyanslı olması:
u’nun varyansı farklıdır. u’nun varyansı Y’nin X için şartlı beklenen değerine bağlıdır ve sonuçta u’nun varyansı X’in değerine bağlı olacak ve eşit olmayacaktır. ui hata teriminin değişen varyanslı olması: Var(ui) = Pi(1-Pi) DOM’nin EKKY ile tahmininde ortaya çıkan farklı varyans problemine aşağıdaki dönüşümlü modeli tahmin ederek çözüm getirmek mümkündür:
 = Pi(1-Pi) DOM’nin EKKY ile tahmininde ortaya çıkan farklı varyans problemine aşağıdaki dönüşümlü modeli tahmin ederek çözüm getirmek mümkündür:")
8
DOM’de Farklı Varyansı Önleme
ler bilinmediğinden bunun yerine örnek tahmini değerleri hesaplanarak ifadesinde yerine konarak ler kullanılır. 0 E(Yi |Xi) 1 varsayımının yerine gelmeyişi DOM’de Y’nin şartlı olasılığını gösteren E(Y|X) nın 0 ila 1 arasında bulunması şarttır. Y; 0 ve 1 değerini almaktadır.Bu şart anakütle için geçerlidir. Anakütlenin tahmincisi için geçerli olmayabilir. Tahmini şartlı olasılıklar 0 ile 1 olmayabilir: 8
 1 varsayımının yerine gelmeyişi. DOM’de Y’nin şartlı olasılığını gösteren E(Y|X) nın 0 ila 1 arasında bulunması şarttır. Y; 0 ve 1 değerini almaktadır.Bu şart anakütle için geçerlidir. Anakütlenin tahmincisi için geçerli olmayabilir. Tahmini şartlı olasılıklar 0 ile 1 olmayabilir: 8.")
9
0 E(Yi |Xi) 1 0 ile 1 arasında mıdır? DOM”, EKKY ile elde edildikten sonra Bunlardan bir kısmı 0 dan küçük, negatif değerli ise, bunlar için 0 değerini alır. 1’den büyük değerli ise bunlar için nin 1’e eşit olduğu kabul edilir. Dönüştürmeden sonra EKKY tekrar uygulanır ve farklı varyansın kalktığı görülebilir. eşit varyanslıdır. Bu yöntem TEKKY’dir.

10
Doğrusal Olasılık Modeli
Di = b1 + b2Mi +b3 Si +ui Di= 1 Eğer i. Kadının bir işi varsa ya da iş arıyorsa 0 Diğer Durumlarda Mi= 1 Eğer i. Kadın evliyse diğer durumlarda 0 Si = i.kadının yıl olarak aldığı eğitim Ai= i. Kadının Yaşı

11
Kadının İşgücüne Katılımı Modeli:
Di Mi Ai Si 1 31 16 35 10 34 14 40 41 43 67 9 37 12 25 27 13 58 28 45 48 55 66 7 44 11 8 21 15 62 23 51 39 Kadının İşgücüne Katılımı Modeli: Di= 1 i.Kadının bir işi varsa ya da iş arıyorsa 0 Diğer Durumlarda Mi= 1 i. Kadın evliyse 0 diğer durumlarda Si = i.kadının yıl olarak aldığı eğitim Ai= i. Kadının Yaşı

12
Kadının İşgücüne Katılımı Modeli
Mi= 1 Kadın evliyse ;0 diğer durumlarda ; Si = i.kadının yıl olarak aldığı eğitim A= Kadının Yaşı Di = b1 + b2Mi +b3 Si +ui Dependent Variable: DI Included observations: 30 Variable Coefficient Std. Error t-Statistic Prob. C MI SI R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
")
13
White Heteroskedasticity Test:
F-statistic Probability Obs*R-squared Probability Dependent Variable: RESID^2 Included observations: 30 Variable Coefficient Std. Error t- Statistic Prob. C MI MI*SI SI SI^ R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
")
14
DOM’de Farklı Varyansı Önleme
Dependent Variable: Included observations: 30 Variable Coefficient Std. Error t-Statistic Prob. R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
")
15
UYGULAMA:Cep telefonunun kullanılıp kullanılmamasını ifade eden bağımlı kukla değişken 50 kişiye yapılan anket sonuncunda yaş ve aylık ortalama gelir ile açıklanmıştır.(Y=1, cep telefonuna sahip ise, Y=0 cep telefonuna sahip değilse) Kişi Y X(Gelir) Z(Yaş) 1 250 23 26 185 21 2 350 27 3 150 28 500 4 600 22 29 790 5 200 30 6 20 31 675 7 390 32 490 8 18 33 9 900 25 34 760 10 35 550 11 255 36 400 24 12 300 37 13 640 38 220 14 39 175 15 40 840 16 19 41 17 800 42 875 43 44 485 45 46 47 470 48 750 49 225 50 130
 Z(Yaş)")
16
Included observations: 50
Y=1, cep telefonuna sahip ise, Y=0 cep telefonuna sahip değilse; X(Gelir); Z(Yaş) Dependent Variable: Y Method: Least Squares Included observations: 50 Variable Coefficient Std. Error t-Statistic Prob. C X Z R-squared Mean dependent var 0.700 Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
; Z(Yaş) Dependent Variable: Y. Method: Least Squares. Included observations: 50. Variable Coefficient Std. Error t-Statistic Prob. C X Z R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)")
17
White Heteroskedasticity Test:
F-statistic Probability Obs*R-squared Probability Dependent Variable: RESID^2 Included observations: 50 Variable Coefficient Std. Error t-Statistic Prob. C X X^ E E X*Z E Z Z^ R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
")
18
Kişi 1 0.7308 16 0.5338 31 0.8536 46 0.4970 2 0.6077 17 0.5705 32 0.7627 47 0.4944 3 0.6817 18 0.8658 33 0.6815 48 1.0012 4 0.8167 19 0.3861 34 0.8093 49 0.5586 5 0.6201 20 0.5953 35 1.1367 50 0.6718 6 0.4233 21 0.5092 36 0.8907 7 1.1442 22 37 0.5340 8 0.2756 23 0.7922 38 0.5438 9 1.2226 24 0.8044 39 0.6939 10 0.2510 25 0.7185 40 0.8486 11 0.3026 26 0.5266 41 12 27 42 0.7062 13 1.0948 28 43 14 1.1982 29 0.9963 44 0.8463 15 0.6693 30 0.7676 45

19
Dependent Variable: Method: Least Squares Sample: 1 50 Included observations: 44 Excluded observations: 6 Variable Coefficient Std. Error t-Statistic Prob. R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
")
20
DOM’e Alternatif Model Arama
DOM ile ilgili sayılan sorunlar aşılabilir: DOM EKKY nin iki varsayımını yerine getirmez. Hatalar normal dağılımlı değildir ve farklı varyans söz konusu olabilir. En önemli problem DOM’nin Pi=E(Y=1|X) nin Xi ile doğrusal doğrusal olarak arttığını varsaymasıdır. Yani X’deki marjinal veya küçük bir artış hep sabittir. Gerçek hayatta ise bu, beklenen bir durum değildir.
 nin Xi ile doğrusal doğrusal olarak arttığını varsaymasıdır. Yani X’deki marjinal veya küçük bir artış hep sabittir. Gerçek hayatta ise bu, beklenen bir durum değildir.")
21
DOM’e Alternatif Model Arama
0-1 aralığı dışına çıkmamak koşuluyla, öyle bir model bulunmalı ki Pi ile Xi arasındaki ilişki eğrisel olsun:Xi deki artışlar Pi yi de arttırsın. Yukarıdaki iki özelliği taşıyan modelin şekli aşağıda verilmiştir: 1 P KDF X + - Yukarıdaki eğri kümülatif dağılım fonksiyonuna benzemektedir. Bu fonksiyon kukla bağımlı değişkenli regresyon modellerinde kullanılabilir.

22
Logit Model Logistik Dağılım Fonksiyonu
kümülatif lojistik dağılım fonksiyonudur. Bahis yada olabilirlik oranı Bu orana örneğin, ev sahibi olma lehine fark oranı denir. Lojistik modelin her iki tarafının doğal log. alındığında Li fark oranı logaritması olup hem X, hem parametrelere göre doğrusaldır.Z değişkeni dan a değişirken, P 0 ile 1 arasında değişir.

23
Logit Model Logit modelde olasılık iken. DOM’de şeklindedir.

24
Logit Model Zi, - ile + arasında değerler alırken Pi’nin aldığı değerler ise 0 ile 1 arasında değişmektedir. Zi ile Pi arasındaki ilişki doğrusal değildir.

25
Logit Modelin Özellikleri
1. Pi, 0’dan 1’e kadar değer aldığında, Logitte -ile + arasında değer alır. Pi=1 = + Pi=0 = - 2. Logit, X’e göre doğrusal iken olasılıklara göre değildir. 3. Logit modelin b2 katsayısı; bağımsız değişkendeki bir birimlik değişme karşısında logitteki değişmeyi gösterir. 4. Logit model tahmin edildikten sonra, X bağımsız değişkeninin belirli bir değeri için logitin gerçekleşme olasılığı hesaplanabilir.

26
Logit Model Bir olayın gerçekleşme olasılığının birden büyük olması durumundan kaçınmak için olasılığın Z’nin S şeklinde bir fonksiyonu olduğunu varsaymaktır. Z, açıklayıcı değişkenlerin fonksiyonu olarak ifade edilebilir. 2

27
Logit Model Birçok fonksiyon S şeklinde fonksiyon özelliklere sahiptir ve yukarıda gösterildiği gibi bunlardan biri de lojistik fonksiyondur. Z + sonsuza gideren, e-Z sıfıra gitmekte, ve p 1’e gitmektedir. (fakat 1’i geçmemektedir.). Z – sonsuza giderken, e-Z de sonsuza gitmekte ve p de sıfıra gitmektedir (fakat sıfırın altına inmemektedir.). 3
. Z – sonsuza giderken, e-Z de sonsuza gitmekte ve p de sıfıra gitmektedir (fakat sıfırın altına inmemektedir.). 3.")
28
Logit Modelin EKKY İle Tahmini
1.Adım: olasılıkları hesaplanır. 2.Adım: fark oranı logaritmaları hesaplanır. 3.Adım: orijinal lojistik modeli tahminlenir. Farklı varyans durumu söz konusu ise; orijinal lojistik modelin her iki tarafı da ile çarpılarak dönüşümlü lojistik model elde edilir.

29
Logit Modelin EKKY İle Tahmini
Farklı varyans durumu söz konusu ise; orijinal lojistik modelin her iki tarafı da ile çarpılarak dönüşümlü lojistik model elde edilir. Dönüşümlü veya Tartılı EKK Lojistik Modeli

30
Logistik Model Uygulaması
300 aileden oluşan küçük bir kasabada ailelerin, yıllık gelirleri (Xi) ve ev sahibi olanların sayısı (ni) aşağıdaki tabloda gösterilmiştir. X Milyon TL) Aile Sayısı= Ni Ev Sahibi Olan Aile Sayısı=ni Nispi Frekanslar Pi=ni/Ni 12 20 5 0.25 16 25 6 0.24 35 10 0.28 26 45 15 0.33 30 50 0.50 40 34 18 0.53 0.66 60 0.61 70 0.75 80 0.67 Ni = 300 ni = 140
 ve ev sahibi olanların sayısı (ni) aşağıdaki tabloda gösterilmiştir. X. Milyon TL) Aile Sayısı= Ni. Ev Sahibi Olan Aile Sayısı=ni. Nispi Frekanslar. Pi=ni/Ni Ni = 300. ni = 140.")
31
Logistik Model Uygulaması
Xi 1 12 16 20 26 30 40 50 60 70 80 Ni 2 20 25 35 45 50 34 30 26 15 ni 3 5 6 10 15 25 18 20 16 Pi 4=3/2 0.25 0.24 0.28 0.33 0.50 0.53 0.66 0.61 0.75 0.67 1-Pi 5=1-4 0.75 0.76 0.72 0.67 0.50 0.47 0.34 0.39 0.25 0.33 Pi /1- Pi 6=4/5 0.33 0.31 0.39 0.49 1.00 1.13 1.94 1.56 3.00 2.03 Li 7=ln(6) 0.0000 0.1222 0.6626 0.4446 1.0986 0.7080
")
32
Logistik Model Uygulaması
Dependent Variable: L Method: Least Squares Included observations: 10 Variable Coefficient Std. Error t-Statistic Prob. C X R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
")
33
Logistik Model Uygulaması
v=N.P.(1-P) 8=2.4.5 3.75 4.56 7.05 9.95 12.50 8.47 6.73 6.18 3.31 vi 9= 8 1.9365 2.1354 2.6552 3.1543 3.5355 2.9103 2.5942 2.4859 1.8193 L* 10=7.9 0.0000 0.3556 1.7189 1.1052 2.1274 1.2880 X* 11=1.9
 8= vi. 9= L* 10= X* 11=")
34
Logistik Model Uygulaması
Li*= vi Xi*, s= s(bi): (0.2315) ( ) , R2= 0.80 t= ( ) (6.0424) , d= 1.649, F= 36.95 Gelir bir birim arttığında, ev sahibi olma lehine fark oranının logaritması artmaktadır. Bu fark oranına göre belli bir gelir seviyesinde ev sahibi olma olasılığı hesaplanabilir: X=40 iken değerleri yukarıdaki denklemde yerine konduğunda L*= bulunur. olabilirlik oranı
: (0.2315) ( ) , R2= t= ( ) (6.0424) , d= 1.649, F= Gelir bir birim arttığında, ev sahibi olma lehine fark oranının logaritması artmaktadır. Bu fark oranına göre belli bir gelir seviyesinde ev sahibi olma olasılığı hesaplanabilir: X=40 iken. değerleri yukarıdaki denklemde yerine konduğunda. L*= bulunur. olabilirlik oranı.")
35
40 birim gelirli bir ailenin ev sahibi olma olasılığı %47.43’dür.
Lojistik modelden, belli bir gelir seviyesinde gelirdeki bir birimlik artışın ev sahibi olma olasılığını ne ölçüde arttıracağı tahmin edilebilir: formülünden yararlanılır. X=40 iken gelir 1 birim arttığında ev sahibi olma olasılığı [ ( )0.4743]= (%0.8)
0.4743]= (%0.8)")
36
Bu verilerle ilgili Logit tahmin modeli aşağıdaki gibidir:
UYGULAMA: Kasımpatı yaprak bitkilerini öldüren bir ilaçtan 1 Lt suya konan dozlar (X, Miligram), yaklaşık 50cl.’lik bit grupları(Ni) üzerine sıkılmış ve ölen bit sayısı (ni) aşağıdaki gibi tesbit edilmiştir: Doz(Litre başına mg) X Gruplardaki yaprak biti sayısı (Ni) Ölen (ni) Li 2.6 50 6 -1.99 3.8 48 16 -0.69 5.1 46 24 0.09 7.7 49 42 1.79 10.2 44 1.99 Bu verilerle ilgili Logit tahmin modeli aşağıdaki gibidir: 36
, yaklaşık 50cl.’lik bit grupları(Ni) üzerine sıkılmış ve ölen bit sayısı (ni) aşağıdaki gibi tesbit edilmiştir: Doz(Litre başına mg) X. Gruplardaki yaprak. biti sayısı (Ni) Ölen (ni) Li Bu verilerle ilgili Logit tahmin modeli aşağıdaki gibidir: 36.")
37
Dependent Variable: LI Method: Least Squares Included observations: 5
Variable Coefficient Std. Error t-Statistic Prob. C X 37

38
Katsayı tahminlerini yorumlayınız
X=7.7 miligram doz seviyesinde ölüm ihtimali P’yi hesaplayınız. 38

39
Probit Model Bağımlı kukla değişkenli modellerden kümülatif lojistik fonksiyonundan farklı olarak, normal kümülatif dağılım fonksiyonunu kullanan PROBİT(NORMAL) model vardır. P R O B İ T (NORMAL) MODEL F(z)= Probit modeli şu şekilde tanımlayabiliriz: Herhangi bir i hanesinin ev sahibi olma veya olmama kararının gözlenemeyen bir fayda indeksi Ii’ye bağlı olduğunu varsayalım.
 model vardır. P R O B İ T (NORMAL) MODEL. F(z)= Probit modeli şu şekilde tanımlayabiliriz: Herhangi bir i hanesinin ev sahibi olma veya olmama kararının gözlenemeyen bir fayda indeksi Ii’ye bağlı olduğunu varsayalım.")
40
Ii, bağımsız değişkenlere bağlıdır. Örneğin Xi (gelir)değişkeni.
Y=1 hane ev sahibi Y=0 hane ev sahibi değil. (1) Ii= b1 + b2 Xi Her hane için Ii’nın belli bir değerinden itibaren ev sahibi olma durumu söz konusudur.Ii değeri, Ii* değerini aştığı zaman hane, ev sahibi olacak aksi durumda olmayacaktır. Ii* Ii ifadesi, faydanın belli bir eşik değerinden sonra söz konusu olabileceğini gösterir. Ii* başlangıç değeri de Ii gibi gözlenemez. Ancak, aynı ortalama ve varyanslı normal dağıldığı varsayılarak Ii değerleri yukarıdaki regresyon denkleminden tahmin edilir. Tahminciler bulunur.
 Ii= b1 + b2 Xi. Her hane için Ii’nın belli bir değerinden itibaren ev sahibi olma durumu söz konusudur.Ii değeri, Ii* değerini aştığı zaman hane, ev sahibi olacak aksi durumda olmayacaktır. Ii* Ii ifadesi, faydanın belli bir eşik değerinden sonra söz konusu olabileceğini gösterir. Ii* başlangıç değeri de Ii gibi gözlenemez. Ancak, aynı ortalama ve varyanslı normal dağıldığı varsayılarak Ii değerleri yukarıdaki regresyon denkleminden tahmin edilir. Tahminciler bulunur.")
42
Normal dağılım varsayımıyla Ii
Normal dağılım varsayımıyla Ii* ın Ii den küçük veya eşit olma olasılığı aşağıdaki standartlaştırılmış normal KDF ile hesaplanabilir: Pi=Pr(Y=1)=Pr(Ii* Ii)=F(Ii) (2) =Standartlaştırılmış Normal KDF =standartlaştırılmış normal değişken Pi=Bir ev sahibi olma olasılığı.
=Pr(Ii* Ii)=F(Ii) (2) =Standartlaştırılmış Normal KDF. =standartlaştırılmış normal değişken. Pi=Bir ev sahibi olma olasılığı.")
43
Probit Model Pi verilmişken, absiste Ii bulunur.
Pi=F(Ii) 1 Pi Ii* <=Ii verilmişken ev sahibi olma olasılığı Pi ordinatta bulunur Ii= b1 + b2 Xi - + Pi=F(Ii) 1 Pi Pi verilmişken, absiste Ii bulunur. - Ii=F-1(Pi ) +
 1. Pi. Ii* <=Ii verilmişken ev sahibi olma olasılığı Pi ordinatta bulunur. Ii= b1 + b2 Xi. - + Pi=F(Ii) 1. Pi. Pi verilmişken, absiste Ii bulunur. - Ii=F-1(Pi ) +")
44
Ii = F-1(Ii)= F-1 (Pi)=b1+b2Xi
Ii’yı bulabilmek için 2 no’lu ifadenin tersi alınmalıdır. Ii = F-1(Ii)= F-1 (Pi)=b1+b2Xi =Probit model F-1: normal kümülatif dağılım fonksiyonunun tersi.
= F-1 (Pi)=b1+b2Xi. =Probit model. F-1: normal kümülatif dağılım fonksiyonunun tersi.")
45
Probit Modelin Tahmin Aşamaları
Pi= ni/Ni hesaplanır. Ii = F-1 (Pi)= normal eşdeğer sapma bulunur. Ii = b1 + b2 Xi + ui EKK ile tahmin edilir. İstenirse, Ii yerine, (Ii + 5)=probit değerleri alınarak, EKKY ile (13.19) tahmin edilir. modelinin hata terimi ui farklı varyanslıdır. Bu sebepten dönüşümlü değerler alınarak TEKKY uygulanabilir:=
= normal eşdeğer sapma bulunur. Ii = b1 + b2 Xi + ui EKK ile tahmin edilir. İstenirse, Ii yerine, (Ii + 5)=probit değerleri alınarak, EKKY ile (13.19) tahmin edilir. modelinin hata terimi ui farklı varyanslıdır. Bu sebepten dönüşümlü değerler alınarak TEKKY uygulanabilir:=")
46
fi= F-1 (Pi) ifadesine eşit standart normal yoğunluk fonksiyonudur.
6. Büyük örnekler için bi'lerin güven aralıkları ve hipotez testleri uygulanarak, anakütlede durumun geçerliliği araştırılabilir. 7. Belirlilik katsayısı R2, modelin fonksiyonel biçiminin iyi seçilip seçilmediği konusunda bize fikir vermez.

47
Probit Model Uygulaması
Pi 0.25 0.24 0.28 0.33 0.50 0.53 0.66 0.61 0.75 0.67 Ii=F-1(Pi) 0.0000 0.0752 0.4124 0.2793 0.6745 0.4399 Probitler=Zi=(Ii+5) 4.3255 4.2937 4.4172 4.5601 5.0000 5.0752 5.4124 5.2793 5.6745 5.4399 Xi 12 16 20 26 30 40 50 60 70 80
 Probitler=Zi=(Ii+5) Xi")
48
Probit Model Uygulaması
Ii= Xi , r2= r= s(bi) (0.0028) s= 0.2 d= 1.59 t= (7.094) Zi= Xi , r2= r= s(bi) (0.0028) s= 0.2 d= t= (7.071)
 (0.0028) s= 0.2 d= t= (7.094) Zi= Xi , r2= r= s(bi) (0.0028) s= 0.2 d= t= (7.071)")
49
En Yüksek Olabilirlik Yöntemi
İstatistikte, tüm anakütleler kendilerine karşılık gelen bir olasılık dağılımı ile tanımlanırlar. Basit(sıradan) en küçük kareler yöntemi, özünde olasılık dağılımları ile ilgili herhangi bir varsayım içermez. Bu yüzden, çıkarsama yapmada BEK tek başına bir işe yaramaz. BEK, genel bir tahmin yaklaşımından çok regresyon doğrularını bulmada kullanılabilecek bir hesaplama yöntemi olarak görülmelidir.
 en küçük kareler yöntemi, özünde olasılık dağılımları ile ilgili herhangi bir varsayım içermez. Bu yüzden, çıkarsama yapmada BEK tek başına bir işe yaramaz. BEK, genel bir tahmin yaklaşımından çok regresyon doğrularını bulmada kullanılabilecek bir hesaplama yöntemi olarak görülmelidir.")
50
BEK yönteminden daha güçlü kuramsal özellikler gösteren
bir başka nokta tahmincisi EYO, yani “en yüksek olabilirlik” (maximum likelihood) yöntemidir. En yüksek olabilirlik yönteminin ardında yatan temel ilke şu beklentidir: “Rassal bir olayın gerçekleşmesi, o olayın, gerçekleşme olasılığının en yüksek olay olmasındandır.” Bu yöntem, 1920’li yıllarda˙Ingiliz istatistikçi Sir Ronald A. Fisher ( ) tarafından bulunmuştur. Ki-kare testi, bayesgil yöntemler ve çeşitli ölçüt modelleri gibi birçok istatistiksel çıkarım yöntemi, temelde EYO yaklaşımına dayanmaktadır.
 yöntemidir. En yüksek olabilirlik yönteminin ardında yatan temel ilke şu. beklentidir: Rassal bir olayın gerçekleşmesi, o olayın, gerçekleşme olasılığının en yüksek olay olmasındandır. Bu yöntem, 1920’li yıllarda˙Ingiliz istatistikçi Sir Ronald A. Fisher ( ) tarafından bulunmuştur. Ki-kare testi, bayesgil yöntemler ve çeşitli ölçüt modelleri gibi birçok istatistiksel çıkarım yöntemi, temelde EYO yaklaşımına dayanmaktadır.")
51
EYO yöntemini anlayabilmek için, elimizde dağılım katsayıları bilinen farklı anakütleler ve rassal olarak belirlenmiş bir örneklem olduğunu varsayalım: Bu örneklemin farklı anakütlelerden gelme olasılığı farklı ve bazı ana kütlelerden gelme olasılığı diğerlerine göre daha yüksektir. Elimizdeki örneklem, eğer bu anakütlelerden birinden alınmışsa, “alınma olasılığı en yüksek anakütleden alınmış olmalıdır” diye düşünülebilir.

52
Kısaca: 1. Anakütlenin olasılık dağılımı belirlenir veya bu yönde bir varsayımda bulunulur. 2. Eldeki örneklem verilerinin, hangi katsayılara sahip anakütleden gelmiş olma olasılığının en yüksek olduğu bulunur. YALTA (2007 – 2008 Ders Notları)
")
53
Regresyon Katsayılarının En Yüksek Olabilirlik Tahminleri
X Y Xi b1 b1 + b2Xi Y = b1 + b2X Y = b1 + b 2X + u modelinde katsayıların en çok olabilirlik tahminleri yapılmadan önce modelde hata terimi olmadığını ifade edelim. Nokta ile gösterilen yerde Y değerine karşılık gelen X değerinin Xi değerine eşit olduğunu görülmektedir. 1

54
X Y Xi b1 b1 + b2Xi Y = b1 + b2X Eğer modele hata terimini eklersek hataların belli bir ortalama ve varyansa bağlı olarak normal dağıldığını varsayabiliriz. 2

55
X Y Xi b1 b1 + b2Xi Y = b1 + b2X Şekilde gösterilen dağılış hata teriminin önceden tahmin edilen dağılışıdır. Gerçekte hata teriminin dağılışının belli bir değere bağlı olarak modelde normal dağıldığını varsayabiliriz. 3

56
X Y Xi b1 b1 + b2Xi Y = b1 + b2X Ayrıca yatay eksene göre bakıldığında; şekilde gösterilen dağılış X=Xi durumunda Y’nin tahmini dağılımını da ifade etmektedir. 4

57
X Y Xi b1 b1 + b2Xi Y = b1 + b2X Y değeri b1 + b2Xi e yaklaştıkça göreceli olarak daha yüksek yoğunluğa sahip olmaktadır. 6

58
Bununla birlikte b1 + b2Xi den uzaklaştıkça yoğunluk azalmaktadır.
Y = b1 + b2X Bununla birlikte b1 + b2Xi den uzaklaştıkça yoğunluk azalmaktadır. 7

59
Regresyon Katsayılarının En Yüksek Olabilirlik Tahminleri
X Y Xi b1 b1 + b2Xi Y = b1 + b2X Yi ‘nin ortalama değeri b1 + b2Xi ve hata terimlerinin standart sapması da s, olduğunu varsayarsak. 8

60
Regresyon Katsayılarının En Yüksek Olabilirlik Tahminleri
X Y Xi b1 b1 + b2Xi Y = b1 + b2X Yi ’lerin olasılık yoğunluk fonksiyonları f(Yi) fonksiyonu ile ifade edilebilir. 9
 fonksiyonu ile ifade edilebilir. 9.")
61
İki Değişkenli Basit Regresyon Modelinin En Yüksek Olabilirlik Yöntemi İle Tahmini
Tek denklemli ekonometrik modellerin tahmininde EKKY dışında kullanılan alternatif yöntem En Yüksek Olabilirlik Yöntemidir. Büyük örneklerde her iki yöntemde yakın sonuçlar vermektedir. Küçük örneklerde ise EYOBY’de olup sapmalıdır. EKKY’de ise sapmasızdır.

62
EYOBY’’nin regresyon modeline uygulanışı şöyledir:
Y bağımlı değişkeninin ortalamalı varyanslı normal ve Yi değerlerinin bağımsız dağıldığı varsayılmaktadır. Yani (1)
")
63
Bu ortalama ve varyansla Yi nin Y1, Y2,…,Yn değerlerinin
bileşik olasılık yoğunluk fonksiyonu şöyledir: Y’ler birbirinden bağımsız olduğundan, bu bileşik olasılık yoğunluk fonksiyonu, n tane bireysel yoğunluk fonksiyonunun çarpımı olarak yazılabilecektir. (2) (2) deki f(Yi), (1) deki ortalama ve varyanslı normal dağılımlı yoğunluk fonksiyonu olup şöyle ifade edilir:
 (2) deki f(Yi), (1) deki ortalama ve varyanslı normal dağılımlı yoğunluk fonksiyonu olup şöyle ifade edilir:")
64
(3) (3)’ü (1) deki her Yi yerine koyarak aşağıdaki ifadeyi elde ederiz: (4) Ortak yoğunluk fonksiyonları her bir yoğunluk fonksiyonunun çarpımına eşittir. (4) de Yi ler bilindiğinde ve b1,b2 ve s2 ler bilinmediğinde (4) ifadesine en yüksek olabilirlik fonksiyonu adı verilir ve L(b1,b2,s2) şeklinde gösterilir.
 de Yi ler bilindiğinde ve b1,b2 ve s2 ler bilinmediğinde (4) ifadesine en yüksek olabilirlik fonksiyonu adı verilir ve L(b1,b2,s2) şeklinde gösterilir.")
65
(5) En yüksek olabilirlik yöntemi bilinmeyen bi parametrelerinin, verilen Y’nin gözlenme olasılığının ençok(maksimum) olacak tarzda tahmini esasına dayanır. Bu sebepten b’lerin EYOBY’ ile tahmin için (5) fonksiyonunun maksimumunun araştırılması gerekir. Bu türevdir, türev için en kısa yol (5) in log. nın alınmasıdır.
 olacak tarzda tahmini esasına dayanır. Bu sebepten b’lerin EYOBY’ ile tahmin için (5) fonksiyonunun maksimumunun araştırılması gerekir. Bu türevdir, türev için en kısa yol (5) in log. nın alınmasıdır.")
68
Wooldridge Example 17.1 inlf kidslt6 kidsge6 age educ exper nwifeinc expersq Obs: 753 1. inlf =1 işgücüne katılıyorsa 2. kidslt < yaşında küçük çocuk sayısı 3. kidsge yaşları arasındaki çocuk sayısı 4. age kadının yaşı 5. educ eğitim yılı 6. exper deneyim 7. nwifeinc (ailegeliri – ücret*saat)/1000 8. expersq deneyimkare
/ expersq deneyimkare.")
69
Wooldridge Example 17.1-DİM
Dependent Variable: INLF Method: Least Squares Included observations: 753 Variable Coefficient Std. Error t-Statistic Prob. NWIFEINC EDUC EXPER EXPERSQ AGE KIDSLT KIDSGE C R-squared Mean dependent var Adjusted R-squared S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood F-statistic Durbin-Watson stat Prob(F-statistic)
")
70
Wooldridge Example 17.1-LOGİT
Dependent Variable: INLF Method: ML - Binary Logit Included observations: 753 Variable Coefficient Std. Error z-Statistic Prob. NWIFEINC EDUC EXPER EXPERSQ AGE KIDSLT KIDSGE C Mean dependent var S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood Hannan-Quinn criter Restr. log likelihood Avg. log likelihood LR statistic (7 df) McFadden R-squared Probability(LR stat) Obs with Dep= Total obs 753 Obs with Dep=1 428
 McFadden R-squared Probability(LR stat) Obs with Dep=0 325 Total obs 753. Obs with Dep=")
71
Wooldridge Example 17.1-PROBİT
Dependent Variable: INLF Method: ML - Binary Probit Included observations: 753 Variable Coefficient Std. Error z-Statistic Prob. NWIFEINC EDUC EXPER EXPERSQ AGE KIDSLT KIDSGE C Mean dependent var S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood Hannan-Quinn criter Restr. log likelihood Avg. log likelihood LR statistic (7 df) McFadden R-squared Probability(LR stat) Obs with Dep= Total obs 753 Obs with Dep=1 428
 McFadden R-squared Probability(LR stat) Obs with Dep=0 325 Total obs 753. Obs with Dep=")
72
UYGULAMA: Aşağıda bir okulun eğitimi ile ilgili verileri kullanarak Probit denklemini çıkartınız.
GRADE: Yeni bir tekniğin uygulanması sonucu öğrencilerin başarısı PSI: Yeni Bir Ekonomi Öğretme Yöntemi GPA: Ortalama Derece TUCE: Sınav Öncesi Konu ile ilgili Bilgi SKoru

73
Dependent Variable: GRADE
Method: ML - Binary Probit Included observations: 32 Convergence achieved after 5 iterations Variable Coefficient Std. Error z-Statistic Prob. C GPA PSI TUCE

74
Dependent Variable: GRADE
Method: ML - Binary Logit Sample: 1 32 Variable Coefficient Std. Error z-Statistic Prob. C GPA PSI TUCE

75
Kadının İşgücüne Katılımı Modeli:
Di Mi Ai Si 1 31 16 35 10 34 14 40 41 43 67 9 37 12 25 27 13 58 28 45 48 55 66 7 44 11 8 21 15 62 23 51 39 Kadının İşgücüne Katılımı Modeli: Di= 1 i.Kadının bir işi varsa ya da iş arıyorsa 0 Diğer Durumlarda Mi= 1 i. Kadın evliyse 0 diğer durumlarda Si = i.kadının yıl olarak aldığı eğitim Ai= i. Kadının Yaşı 75

76
Logit Model Tahminleri
Dependent Variable: DI Method: ML - Binary Logit Included observations: 30 Convergence achieved after 5 iterations Covariance matrix computed using second derivatives Variable Coefficient Std. Error z-Statistic Prob. C MI SI Mean dependent var S.D. dependent var S.E. of regression Akaike info criterion Sum squared resid Schwarz criterion Log likelihood Hannan-Quinn criter Restr. log likelihood Avg. log likelihood LR statistic (2 df) McFadden R-squared Probability(LR stat) Obs with Dep= Total obs 30 Obs with Dep=1 18
 McFadden R-squared Probability(LR stat) Obs with Dep=0 12 Total obs 30. Obs with Dep=1 18.")
Benzer bir sunumlar

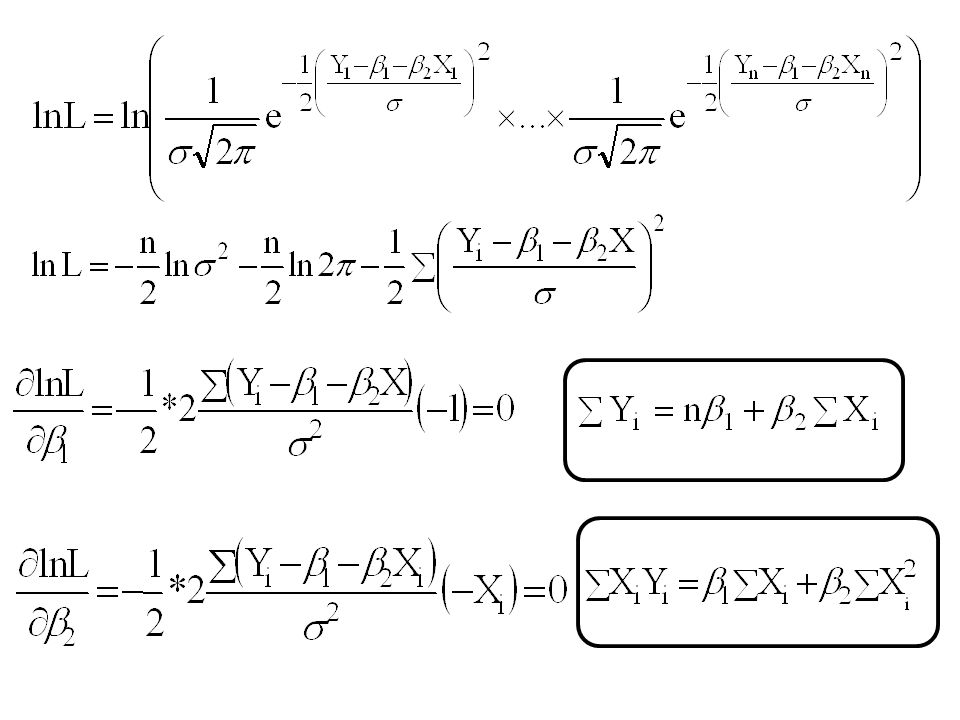
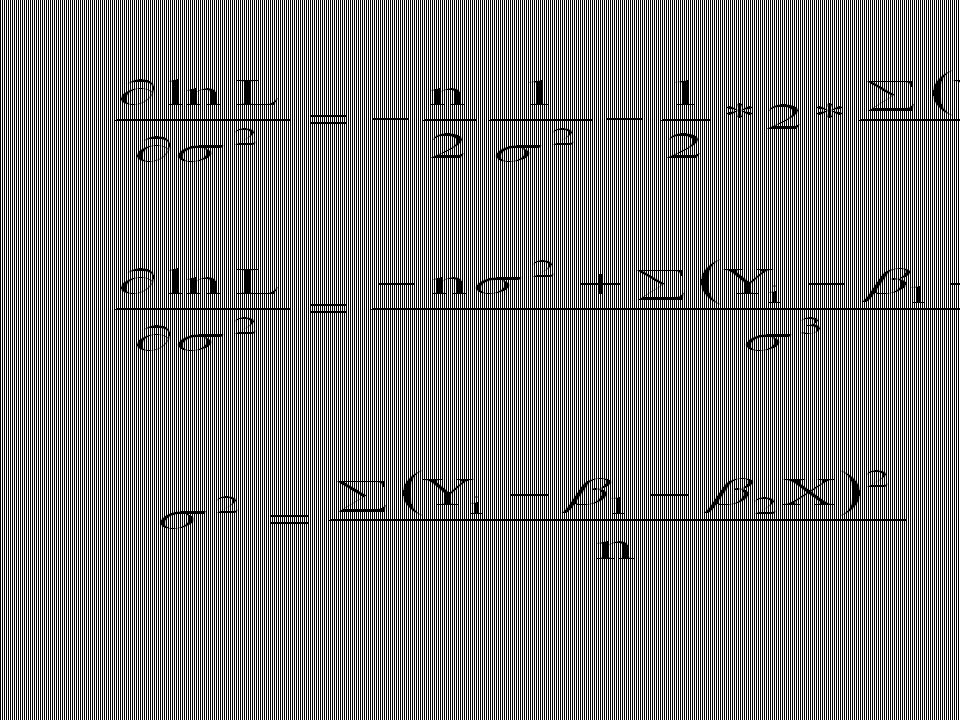



 ve farklı populasyonlar için ’nın örnekleme dağılışı.>")

Fonksiyonu>")






 = Var(u i ) = E(u i 2 ) = 2 Eşit Varyans Y X.>")






