Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
BİL YAPAY ZEKA Hafta 10

2
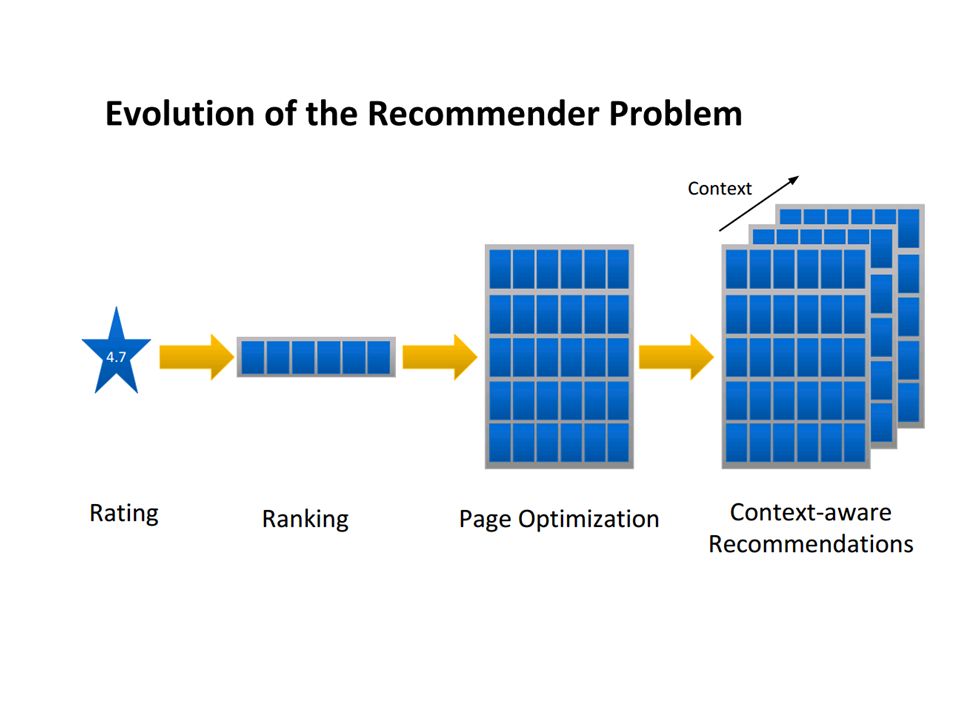
Öneri Sistemleri (Recommender Systems)
")
4
Öneriler Neler önerilir?: Film, şarkı, laptop, kitap, restoran, otel, reklam, …. Akademik ve endüstriyel anlamda çok sıcak bir konu Fikir: Kullanıcıların bir ürün, servis hakkındaki beğenilerini tahmin etmek

5
Recommender Systems Application areas

6
In the Social Web

7
Even more … Personalized search "Computational advertising"

8
Olası Yararları Kullanıcı açısından Servis Sağlayıcı açısından
Kişiselleşmiş servis alma Hızlı ürün arama İlgisini çekebilecek ürünlerin daha kolay farkına varma Servis Sağlayıcı açısından Satış artışı Sitelerde daha fazla zaman geçirme Asıl karlı ürünlerin satışı (non-best-selling (long tail) products) İtibar artışı ve firmaya bağımlılık
 products) İtibar artışı ve firmaya bağımlılık.")
9
Kişilere önerilerde bulunmak
Kişiye özel reklam ? / genel reklam ? Nasıl? Kişi benzerlikleri (Collaborative filtering) Ürün benzerlikleri (Content based) Hibrit
 Ürün benzerlikleri (Content based) Hibrit.")
10
Netflix örneği “For only $7.99 a month, instantly watch unlimited movies & TV episodes streaming over the Internet to your TV via an Xbox 360, PS3, Wii or any other device that streams from Netflix.” Türkiye örneği “Tivibu”

11
The “NetFlix” challenge:
Improve the prediction of the system by 10% Prize: 1M dollars!

12
Netflix challenge – Improve RMSE by 10%
u: user i:item r(u,i)=user’ın item’a verdiği not
=user’ın item’a verdiği not.")
15
Netflix Real-Life Data
~20000 Movies 2M Users Over 100M Ratings Large-scale…

16
Her kullanıcı için bir sevme/sevmeme modeli üretildikten sonra
Yeni gelen bir filmi bu modele verip kullanıcının onu sevip sevmeyeceğini tahmin et, sever diyorsan öner Her kullanıcı için ayrı bir model yerine kullanıcıları kümeleyip o kümenin modeli de üretilebilir.

17
Original Session/user data
Kullanıcı Kümeleme Original Session/user data Result of Clustering Html leri filmler/ ürünler olarak düşünebiliriz.

18
Öneri Sistemleri Tipleri
İşbirlikçi Filtreleme (Collaborative filtering) İçerik bazlı Filtreleme (Content-based filtering) Hibrit Önerici Sistemler (İşbirlikçi ve İçerik bazlı hibrit şekilde birlikte kullanımı)
 İçerik bazlı Filtreleme (Content-based filtering) Hibrit Önerici Sistemler (İşbirlikçi ve İçerik bazlı hibrit şekilde birlikte kullanımı)")
19
İçerik bazlı Filtreleme
İşbirlikçi Filtreleme

20
Öneri Sistemleri Tipleri
İşbirlikçi ve içerik-bazlı filtreleme sistemleri arasındaki farklar, iki popüler müzik önerme sisteminin karşılaştırmasıyla gösterilebilir – Last.fm ve Pandora Radyo: Last.fm, kullanıcının düzenli olarak dinlediği parçaları gözlemler ve bunları diğer kullanıcıların dinleme alışkanlıklarıyla karşılaştırarak bir önerilen şarkılar radyosu oluşturur. Kullanıcıların davranışlarını kullanması sebebiyle bu yaklaşım bir işbirlikçi filtreleme örneğidir. Pandora bir şarkının ya da sanatçının özelliklerini (Music Genome Project tarafından sağlanan 400 özelliğin bir alt kümesi), benzer özelliklere sahip müziklerin çalındığı bir radyo başlatmak için kullanır. Kullanıcı geri bildirimi kullanılarak radyonun sonuçları iyileştirilir. Kullanıcının "beğenmediği" şarkıların özelliklerini zayıflatır ve "beğendiği" şarkıların özelliklerini güçlendirir. Bu bir içerik-bazlı filtreleme örneğidir.
, benzer özelliklere sahip müziklerin çalındığı bir radyo başlatmak için kullanır. Kullanıcı geri bildirimi kullanılarak radyonun sonuçları iyileştirilir. Kullanıcının beğenmediği şarkıların özelliklerini zayıflatır ve beğendiği şarkıların özelliklerini güçlendirir. Bu bir içerik-bazlı filtreleme örneğidir.")
21
Öneri Sistemleri Tipleri
İşbirlikçi ve içerik-bazlı filtreleme sistemlerinin her birinin kendi güçlü ve zayıf yanları vardır. Bir önceki yansıdaki örnekte, Last.fm isabetli tahminler yapabilmek için bir kullanıcıdan büyük miktarda veri toplamalıdır. Bu durum soğuk başlangıç problemi olarak bilinir ve işbirlikçi filtreleme sistemlerinde sıkça rastlanır. Pandora başlangıç için çok az bilgiye ihtiyaç duyar ama çok daha kısıtlı bir kapsama sahiptir (mesela, sadece başlangıç şarkısına benzer öneriler yapabilir). Bu da, içerik-bazlı filtreleme sistemlerinin dezavantajıdır.
. Bu da, içerik-bazlı filtreleme sistemlerinin dezavantajıdır.")
22
Öneri Sistemlerindeki Önemli Faktörler
Ayrışma – Kullanıcılar birbirine daha az benzeşen öğeleri tercih edebilir, örn. farklı sanatçılardan öğeler. Önerme sürekliliği – Bazen yeni öğeler önermektense daha önce önerilmiş öğelerin tekrar gösterilmesi daha işlevseldir. Gizlilik – Önerici sistemler sıklıkla kullanıcıların gizlilik kaygılarını dikkate almalıdır. Kullanıcı demografisi – Kullanıcıların kimlikleri öneri memnuniyetlerini etkileyebilir. Düzgünlük – Kullanıcı katılımı olan önerici sistemler sahtekârlığa karşı bağışıklı olmalıdır. Rastlantısallık – Rastlantısallık "önerilerin ne kadar şaşırtıcı olduğu"'dur. Güvenilirlik– Eğer güven vermiyorsa önerici sistemin kullanıcı nezdinde bir değeri olmaz. Kullanıcılara öneri yöntemlerinin nasıl çalıştığı açıklanarak güven kazanılabilir. Etiketleme – Kullanıcı tatmini önerilerin nasıl etiketlendiğine göre değişiklik gösterebilir.

23
Öneri Sistemlerindeki Performans (Başarım) Ölçütleri
Yaygın olarak kullanılan ölçütler, hatalar karesi ortalaması - mean squared error (MSE) ve kök hatalar karesi ortalaması - root mean squared error (RMSE)'dir. Ayrıca, bilgi edinimi bazlı sınıflandırmalarda da kullanılan Kesinlik (precision) ve Duyarlılık (recall / sensitivity) da bazen ölçüt olarak kullanılmaktadır. Duyarlılık (recall), Doğru pozitif oranı (TPrate) ile aynıdır. Kesinlik ise doğru pozitiflerin, doğru pozitif + yanlış pozitife bölünmesi ile bulunur.
 ve kök hatalar karesi ortalaması - root mean squared error (RMSE) dir. Ayrıca, bilgi edinimi bazlı sınıflandırmalarda da kullanılan Kesinlik (precision) ve Duyarlılık (recall / sensitivity) da bazen ölçüt olarak kullanılmaktadır. Duyarlılık (recall), Doğru pozitif oranı (TPrate) ile aynıdır. Kesinlik ise doğru pozitiflerin, doğru pozitif + yanlış pozitife bölünmesi ile bulunur.")
24
Kullanıcı Bazlı İşbirlikçi Filtreleme (User Based Collaborative Filtering)
Sana benzeyen kullanıcıların sevdiği filmleri seversin. Kullanıcı benzerlikleri seyredilen filmlerle belirlenir. Karşılıklı özyineleme (Mutual recursion)
")
25
CF

26
CF

27
CF

28
CF

29
CF

30
CF Algorithms

31
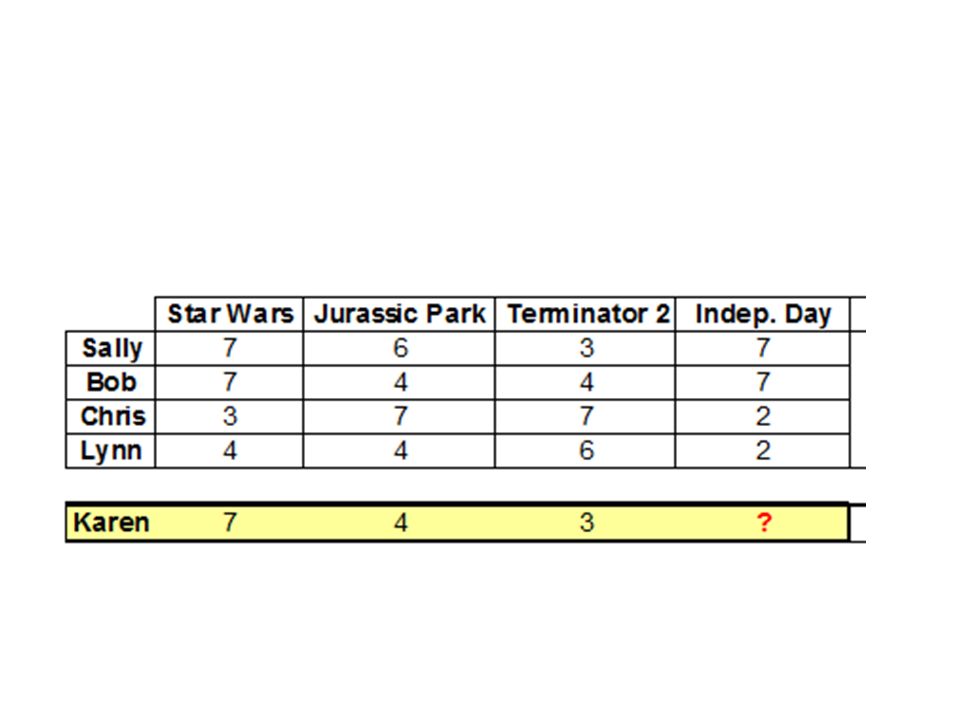
Örnek: MxN Matris M adet kullanıcı and N adet ürün (Boş hücreler puan verilmediğini gösterir)
Items / Users Data Mining Search Engines Data Bases XML Alex 1 5 4 George 2 3 Mark Peter

32
Gözlemler ve Ölçümler Her kullanıcı için vektörler oluşturulur (0 değerleri: puan verilmeyenler) Alex: <1,0,5,4> Peter <0,0,4,5> … Vektör benzerliği (Vector similarity) ya da Pearson korelasyon katsayısı ile en benzerler bulunur. Sonra da En Yakın Komşu (nearest neighbor), vb yöntemlerle seçim yapılır. Alex Peter’ a en yakın, ondan sonra da George.
 ya da Pearson korelasyon katsayısı ile en benzerler bulunur. Sonra da En Yakın Komşu (nearest neighbor), vb yöntemlerle seçim yapılır. Alex Peter’ a en yakın, ondan sonra da George.")
33
Örnek– Amazon.com Customers who bought this item also bought:
Item-to-item collaborative filtering Find similar items rather than similar customers. Record pairs of items bought by the same customer and their similarity. This computation is done offline for all items. Use this information to recommend similar or popular books bought by others. This computation is fast and done online.

34
Amazon Recommendations

35
Amazon Personal Recommendations

36
MovieLens Recommendations

37
Kullanıcı bazlı İşbirlikçi Filtreleme (User-based CF)
u kullanıcısının, i filmine vereceği oyu tahmin etmek için; i filmine verilen oylar, oy verenlerin u’ya benzerlikleriyle ağırlıklandırılır. N(u;i) – i filmine oy veren kullanıcılar R – rating, S- similarity
 – i filmine oy veren kullanıcılar. R – rating, S- similarity.")
38
s(u,v)’yi ölçmek - yöntemlerden birisi: Pearson correlation coefficient
I(u,v) – u ve v kullanıcıları tarafından oy verilmiş olan tüm filmler Pearson korelasyon katsayısı, -1 ile 1 arası değerler alır.
 – u ve v kullanıcıları tarafından oy verilmiş olan tüm filmler. Pearson korelasyon katsayısı, -1 ile 1 arası değerler alır.")
39
Kullanıcı bazlı İşbirlikçi Filtreleme (User-based CF)
The basic technique: Given an "active user" (Alice) and an item I not yet seen by Alice The goal is to estimate Alice's rating for this item, e.g., by find a set of users (peers) who liked the same items as Alice in the past and who have rated item I use, e.g. the average of their ratings to predict, if Alice will like item I do this for all items Alice has not seen and recommend the best-rated Item1 Item2 Item3 Item4 Item5 Alice 5 3 4 ? User1 1 2 User2 User3 User4
 and an item I not yet seen by Alice. The goal is to estimate Alice s rating for this item, e.g., by. find a set of users (peers) who liked the same items as Alice in the past and who have rated item I. use, e.g. the average of their ratings to predict, if Alice will like item I. do this for all items Alice has not seen and recommend the best-rated. Item1. Item2. Item3. Item4. Item5. Alice User User2. User3. User4.")
40
Kullanıcı bazlı İşbirlikçi Filtreleme (User-based CF)
Some first questions How do we measure similarity? How many neighbors should we consider? How do we generate a prediction from the neighbors' ratings? Item1 Item2 Item3 Item4 Item5 Alice 5 3 4 ? User1 1 2 User2 User3 User4

41
Kullanıcı bazlı İşbirlikçi Filtreleme (User-based CF)
A popular similarity measure in user-based CF: Pearson correlation a, b : users ra,p : rating of user a for item p P : set of items, rated both by a and b Possible similarity values between -1 and 1; = user's average ratings Item1 Item2 Item3 Item4 Item5 Alice 5 3 4 ? User1 1 2 User2 User3 User4 sim = 0,85 sim = 0,70 sim = -0,79

42
Kullanıcı bazlı İşbirlikçi Filtreleme (User-based CF)
Son aşamada, bu benzerlik değerlerine göre, uygun bir algoritma / yöntem ile en yakın kullanıcı / kayıtlar seçilir. Bu aşamada, en bilinen yöntem k-NN (k- en yakın komşu, k-Nearest Neighbor) algoritmasıdır. Bir önceki yansıdaki örnekte, k-NN yöntemi kullanılır ve k=1 seçilirse, 0.85 benzerlik Pearson değerine sahip en yakın komşu User1 seçilecek ve Alice’in Item5 değeri 3 olarak atanacaktır. Benzer şekilde eğer k=2 seçilirse, en yakın 2 komşu (en yüksek Pearson cc değerine sahip) User1 ve User 2 seçilecek ve Alice’in Item5 değeri bu iki komşunun ortalaması (3 + 5) / 2 = 4 olarak atanacaktır. DİKKAT: Kullanıcı bazlı işbirlikçi filtrelemede, eğer bir kullanıcın herhangi bir item / nesne için tahminlemesi gerekiyorsa, doğrudan Pearson ya da başka benzerlik değerlerini doğrudan almak yerine, tahminleme fonksiyonları ve ağırlıklar hesaplanarak ağırlıklı en yakın komşular ve tahminlenecek değer seçilecektir.
 algoritmasıdır. Bir önceki yansıdaki örnekte, k-NN yöntemi kullanılır ve k=1 seçilirse, 0.85 benzerlik Pearson değerine sahip en yakın komşu User1 seçilecek ve Alice’in Item5 değeri 3 olarak atanacaktır. Benzer şekilde eğer k=2 seçilirse, en yakın 2 komşu (en yüksek Pearson cc değerine sahip) User1 ve User 2 seçilecek ve Alice’in Item5 değeri bu iki komşunun ortalaması (3 + 5) / 2 = 4 olarak atanacaktır. DİKKAT: Kullanıcı bazlı işbirlikçi filtrelemede, eğer bir kullanıcın herhangi bir item / nesne için tahminlemesi gerekiyorsa, doğrudan Pearson ya da başka benzerlik değerlerini doğrudan almak yerine, tahminleme fonksiyonları ve ağırlıklar hesaplanarak ağırlıklı en yakın komşular ve tahminlenecek değer seçilecektir.")
43
Making predictions A common prediction function:
Calculate, whether the neighbors' ratings for the unseen item i are higher or lower than their average Combine the rating differences – use the similarity as a weight Add/subtract the neighbors' bias from the active user's average and use this as a prediction

44
s(u,v)’yi ölçmek – diğer bir yöntem: Cosine Similarity
Pearson’a alternatif birçok benzerlik formülü / hesabı vardır. Bunlardan bir tanesi de Kosinüs Benzerliği (Cosine similarity)’ dir. A ve B iki farklı kayıttır (kullanıcı, vb) Ai ve Bi her kayıttaki her bir i'nci attribute değeri (değişken, sütun elemanıdır) NOT: Kosinüs Benzerliği 0 ile 1 arası değerler alır.
’ dir. A ve B iki farklı kayıttır (kullanıcı, vb) Ai ve Bi her kayıttaki her bir i nci attribute değeri (değişken, sütun elemanıdır) NOT: Kosinüs Benzerliği 0 ile 1 arası değerler alır.")
45
Öğe Bazlı İşbirlikçi Filtreleme (Item-based collaborative filtering)
Kullanıcı bazlıdan farklı olarak, öğeler arası benzerliğe bakarak seçim önerir ya da bilinmeyen puanı tahmin eder. Örnek: Alice’in Item5’e kaç puan vereceğini tahmin etmek için, Item5’e en benzer / yakın item’lara bakılıyor. Item1 ve Item2. Sonra da, Alice’in bu iki öğeye verdiği puanlar üzerinden Item5 puanı tahmin ediliyor Item1 Item2 Item3 Item4 Item5 Alice 5 3 4 ? User1 1 2 User2 User3 User4

46
Öğe Bazlı İşbirlikçi Filtreleme (Item-based collaborative filtering)
En yakın, benzer öğeleri seçmede genelde k-NN en yakın komşu kullanılır. Yakınlık / benzerlik hesabında ise, öncelikle Kosinüs benzerliği (Cosine similarity) tercih edilir. Yapılan çalışmalarda, öğe bazlı işbirlikçi filtrelemede Cosine similarity’nin çoğunlukla Pearson cc’a göre daha tutarlı / başarılı sonuç verdiği görülmüştür. Öte yandan, kullanıcı bazlı işbirlikçi filtrelemede ise, Pearson cc’ nın Cosine similarity’den çoğunlukla daha tutarlı / başarılı sonuç verdiği görülmüştür. Ama kesin olarak hangi benzerlik değeri hesabı hangi modelde daha iyi denemez, ayrıca bu iki hesaplamadan başka benzerlik hesapları da vardır ve bazen onlar daha iyi sonuç alabilirler.
 tercih edilir. Yapılan çalışmalarda, öğe bazlı işbirlikçi filtrelemede Cosine similarity’nin çoğunlukla Pearson cc’a göre daha tutarlı / başarılı sonuç verdiği görülmüştür. Öte yandan, kullanıcı bazlı işbirlikçi filtrelemede ise, Pearson cc’ nın Cosine similarity’den çoğunlukla daha tutarlı / başarılı sonuç verdiği görülmüştür. Ama kesin olarak hangi benzerlik değeri hesabı hangi modelde daha iyi denemez, ayrıca bu iki hesaplamadan başka benzerlik hesapları da vardır ve bazen onlar daha iyi sonuç alabilirler.")
47
Problemler Sparsity level of the data set:
Matrislerde veya vektörlerde çok fazla 0 değeri olması. Bazen bir vektör / matrisin % 90 ve üzeri elemanı 0 değeri alabilir ! Similarity computation time complexity - N*N*M , highly time consuming with millions of users and items in the database. N user, M item Cold start (yeni kullanıcı, yeni ürün) durumları
 durumları.")
48
Daha iyisi için? Kullanıcıların sistem dışı bilgilerini kullanmak
Sosyal medya hesapları Hibrit modeller Başka fikri olan?

50
İnandırıcılık

51
Başarı ölçümü Bir firma için müzik öneri sistemi geliştirdiniz. Sistemi kullanıma açmadan performansı nasıl ölçersiniz? Sistemdeki yeni X günlük kullanıcı-şarkı ikililerini kaydet. (Test kümesi) Geliştirilen sistemin bu ikililer için verdiği puanlara bak. Sistemin kişilere önerdikleri ile kişilerin gerçekte dinlediklerinin kesişim kümesine bak.
 Geliştirilen sistemin bu ikililer için verdiği puanlara bak. Sistemin kişilere önerdikleri ile kişilerin gerçekte dinlediklerinin kesişim kümesine bak.")
52
Bir soru Kullanıcılara ait playlistler var.
Bir bilgileri kullanarak öneri sistemi tasarlayın. Varsayım: Playlist’lerde birlikte geçen şarkılar birbirine benzerdir. Örneğin, 87 listede birlikte geçen 2 şarkı, 5 listede birlikte geçen 2 şarkıya göre birbirine daha benzerdir.

53
Diğer konular Geri bildirim nasıl alınır?
Aktif geri bildirim (şun(lar)a puan ver) Pasif geri bildirim (sayfadaki tıklanmalar, ne süre ile dinlediği / izlediği vb.) Öneri sisteminin varlığı kullanıcı davranışlarını değiştirir mi? Kişisel deneyimleriniz?
a puan ver) Pasif geri bildirim (sayfadaki tıklanmalar, ne süre ile dinlediği / izlediği vb.) Öneri sisteminin varlığı kullanıcı davranışlarını değiştirir mi Kişisel deneyimleriniz")
Benzer bir sunumlar















 problemleri (Matching and Assignment problems)>")
 DİPLOMA EKİ EĞİTİM SEMİNERİ 2011-2013 Dönemi Bologna Sürecinin Türkiye’de.>")
>")




