Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
Ümran Onay

2
İÇERİK Paralel programlama nedir? Paralel programlama modelleri
Paralel hesaplama nedir? Algoritmalar -Uygunluk ve verimlilik -Amdahl kuralı ve ardışık bir programda hızlanma -Pratikte amdahl kuralı nasıl işler? OpenMP - Thread’lerin Hesaplanması -Openmp yürütme modeli -Paralel bölgeler -Uygulama(pi sayısının hesabı) -Avantaj ve dezavantajlar -Programın derlenmesi Son
 -Avantaj ve dezavantajlar. -Programın derlenmesi. Son.")
3
PARALEL PROGRAMLAMA Paralel programlama, işlemler arasında iyi
tanımlanmış iletişim yapıları kullanan ve verimi artırmaya yönelik işlemlerinin paralel işlenmesini sağlayan bir yapıdır.

4
Paralel Programlama Modelleri
Ortak Hafıza Modelleri Dağıtık Ortak Bellek Posix Threads OpenMP Java Threads (HKU JESSICA, IBM cJVM) Mesaj Tabanlı Modeller PVM MPI Hibrid Modeller Ortak ve dağıtık hafızayı birlikte kullananlar OpenMP ve MPI birlikte kullananlar Nesne ve Servis Tabanlı Modeller Geniş alanda dağıtık hesaplama teknolojileri Nesne: CORBA, DCOM Servis: Web servisleri tabanlı Bilimsel araştırma projelerinde sıklıkla Derleyici tarafından paralelleştirilen ortak bellek tabanlı programlar MPI gibi mesaj paylaşımı tabanlı programlar kullanılmaktadır.
 Mesaj Tabanlı Modeller. PVM. MPI. Hibrid Modeller. Ortak ve dağıtık hafızayı birlikte kullananlar. OpenMP ve MPI birlikte kullananlar. Nesne ve Servis Tabanlı Modeller. Geniş alanda dağıtık hesaplama teknolojileri. Nesne: CORBA, DCOM. Servis: Web servisleri tabanlı. Bilimsel araştırma projelerinde sıklıkla. Derleyici tarafından paralelleştirilen ortak bellek tabanlı programlar. MPI gibi mesaj paylaşımı tabanlı programlar kullanılmaktadır.")
5
PARALEL HESAPLAMA Paralel hesaplama, bir uygulamanın
parçalara ayrılarak her bir parçanın birden fazla işlemcide çalıştırılmasıyla daha hızlı sonuç alma işlemidir.

6
ALGORİTMALAR

7
AMDAHL KURALI Sistemin bir parçası hızlandırılır.
Bu sistem bir bütün olarak ela alınır. Ve toplam hızlanmanın ne olacağı hesap edilir.

8
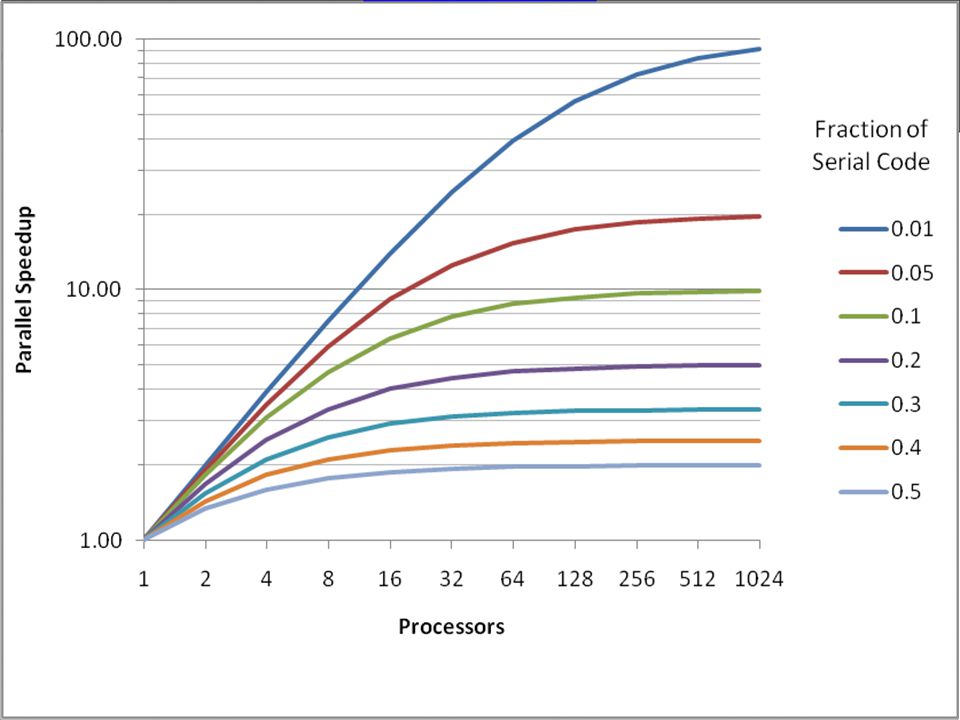
AMDAHL KURALI Azami Hızlanma Şeklindedir.
p = 5, tn (kırmızı) = 3 saniye, ti (mavi) = 1 saniye ve f = tn / (tn + ti) = 0.75 Azami hızlanma p = 2, tn (mavi) = 1 saniye, ti (kırmızı) = 3 saniye ve f = tn / (tn + ti) = 0.25 Azami hızlanma SONUÇ:A bölümünü 2 kat hızlandırmak, B bölümünü 5 kat hızlandırmaktan çok daha az bir çabayla gerçekleştirilebilir.
 = 3 saniye, ti (mavi) = 1 saniye ve. f = tn / (tn + ti) = Azami hızlanma p = 2, tn (mavi) = 1 saniye, ti (kırmızı) = 3 saniye ve. f = tn / (tn + ti) = Azami hızlanma SONUÇ:A bölümünü 2 kat hızlandırmak, B bölümünü 5 kat hızlandırmaktan çok daha az bir çabayla gerçekleştirilebilir.")
10
Pratikte Pratikte programları paralelleştirmek Amdahl yasasında görüldüğü kadar zor değildir. Ancak programın çok büyük bir kısmını paralel işlem için harcaması gereklidir. 8.0 7.0 6.0 5.0 4.0 3.0 2.0 1.0 Hızlanma P=8 P=4 P=2 0% 20% 40% 100% 60% 80% Kodda Paralel Kısım

11
OPENMP Paralel hesaplamada işlemleri kolaylaştırmada kullanılan bir API’dir. Openmp, paylaşılmış hafıza sistemleri için tasarlanmıştır ve genellikle openmp ile daha az çaba harcayarak paralelliği uygulamak için mevcut seri programlar kullanılır. Openmp kullanımı ile: Derleyici komutları ile paralellik sağlamak, Veya zaman zaman işlev çağrısında bulunmak kolaydır. Ve openmp, paralel programlamanın hızlı ve !.... yoludur. (OpenMP is a “quick and dirty” way of parallelizing a program.)
")
12
Thread’lerin Hesaplanması
-Her thraad bir işlemciye atanır. -Her thread programınızın bir kopyasında çalışır. Thread 0 Thread 1 Thread 2 Thread n

13
OpenMP Yürütme Modeli MPI’da, bütün thread’ler her zaman etkindir.
Openmp’de ise yürütme yalnızca master thread üzerindedir. Yavru thread’ler işlemlerin okunması sırasında ve kendilerine ihtiyaç duyulduğu yerde çalışmaya başlarlar. Thread’ler, program paralel alana girdiğinde ortaya çıkarlar ve işlemler yapılır. Paralel bölgeden çıkıldığında ise thread’ler bırakılırlar.

14
Ana thread hem paralel hem seri alanda
OpenMP Yürütme Modeli Thread’lerin sayısı paralel bölgede artarken paralel alan dışında serbest bırakılırlar. Ana thread hem paralel hem seri alanda görev almaktadır.

15
omp_set_num_threads(4); kısmında paralel bölgede çalışacak threadler
oluşturulur ve her thraad aynı kodu çalıştırır. double A[1000]; omp_set_num_threads(4); #pragma omp parallel { int ID = omp_thread_num(); pooh(ID, A); } printf(“all done\n”); double A[1000]; omp_set_num_threads(4); A’nın bir kopyası bütün thread’ler arasında paylaşılır. pooh(0, A); pooh(1, A); pooh(2, A); pooh(3, A); İşlem devam etmeden önce bütün thread’lerin bitmesi bekler. printf(“all done\n”);
; #pragma omp parallel. { int ID = omp_thread_num(); pooh(ID, A); } printf( all done\n ); double A[1000]; omp_set_num_threads(4); A’nın bir kopyası bütün thread’ler. arasında paylaşılır. pooh(0, A); pooh(1, A); pooh(2, A); pooh(3, A); İşlem devam etmeden önce bütün. thread’lerin bitmesi bekler. printf( all done\n );")
16
Pi sayısının OPENMP ile hesaplanması
p = = S 1 4 (1+x2) dx 0<i<N N(1+((i+0.5)/N)2) Pi sayısının OPENMP ile hesaplanması Paralel program Sıralı program #define n main() { double pi, l, ls = 0.0, w = 1.0/n; int i; #pragma omp parallel private(i,l) reduction(+:ls) { #pragma omp for for(i=0; i<n; i++) { l = (i+0.5)*w; ls += 4.0/(1.0+l*l); } #pragma omp master printf(“pi is %f\n”,ls*w); #pragma omp end master #define n main() { double pi, l, ls = 0.0, w = 1.0/n; int i; for(i=0; i<n; i++) { l = (i+0.5)*w; ls += 4.0/(1.0+l*l); } printf(“pi is %f\n”,ls*w); Seri programlama şeklinde yazılıyor Otomatik yük dağılımı yapılıyor. Bütün değişkenler paylaşılıyor.
 dx. 0<i<N. N(1+((i+0.5)/N)2) Pi sayısının OPENMP ile hesaplanması. Paralel program. Sıralı program. #define n main() { double pi, l, ls = 0.0, w = 1.0/n; int i; #pragma omp parallel private(i,l) reduction(+:ls) { #pragma omp for. for(i=0; i<n; i++) { l = (i+0.5)*w; ls += 4.0/(1.0+l*l); } #pragma omp master. printf( pi is %f\n ,ls*w); #pragma omp end master. #define n main() { double pi, l, ls = 0.0, w = 1.0/n; int i; for(i=0; i<n; i++) { l = (i+0.5)*w; ls += 4.0/(1.0+l*l); } printf( pi is %f\n ,ls*w); Seri programlama şeklinde yazılıyor. Otomatik yük dağılımı yapılıyor. Bütün değişkenler paylaşılıyor.")
17
Avantajlar Programcının veri yerleştirme hususunda endişelenmesini gerektirecek bir durum yoktur çünkü openmp paylaşılmış hafızadan yararlanır. Programlama modeli seri benzeridir böylece kavramsal mesaj göndermeden daha kolaydır. Komutların kullanımı daha kolay ve basittir. Eski seri kodun yeniden yazılması gerekmez. Üzerinde yapılacak değişikliklerle paralel hale getirilebilir.

18
Dezavantajlar Programlar yalnızca paylaşılmış hafıza sistemlerinde çalıştırılabilir. Kullanılan derleyicinin openmp desteğinin olması gerekmektedir. -Oysa MPI heryerde kurulabilir. Genel olarak yalnızca orta hızlanma elde edilir. Openmp kodları olduğunca az seri koda sahip olmak isterler.

20
Asal sayı uygulaması

21
SON Teşekkürler

Benzer bir sunumlar





>")





>")
>")


.>")




