Sunuyu indir
1
"Askeri bir helikopter firtina da kaybolur, rotasini sasirir. Hava duzelince nerde olduklarini tayin edemezler. Derken uzakta cok yuksek bi bina gorurler.Yuzbasi pilot dogru oraya dogru surer helikopteri. Binanin etrafinda birkac tur atarlar, tabi binanin icindekiler telas icinde pencerelerden bakmaktadir o onda. Yuzbasi askere emir verir, "buyuk bi kagida Where are we diye yazin hemen!". Yazarlar ve binadakilere gosterriler. Onlarda panik icinde bi kagit bulup hemen cevabi yazarlar: "You are in a helicopter!“ Yuzbasi gulumser ve haritayi getirin der, yerini ve rotasini hemen tayin edip 1 saat sonra uslerine emin olarak inerler. Askerler meraktan catlamak uzeredir tabi, nasil oldu da bu is oldu diye. Ezile buzule sorarlar komutana. Komutan aciklar: "Biz bi soru sorduk, onlar da cevap yazdi,! cevap dogru ama ise yaramaz, derde deva olmaz bi cevapti. Anladim ki o yuksek bina Seattle daki Microsoft binasidir, cunku Microsoftun Help menuleri de aynen dogru fakat ise yaramaz cevap verir!!!!!!" yuksek bina Seattle daki Microsoft binasidir, cunku Microsoftun Help menuleri de aynen dogru fakat ise yaramaz cevap verir!!!!!!"

2
Bölüm 5: İki Degişkenli Regresyon: Aralık Tahmini ve Önsav Sınaması Önceki bölümde nokta tahmini konuşuldu bu bölümdede aralık tahmini ve önsav(hipotezler) tartışılacak. Önceki bölümde nokta tahmini konuşuldu bu bölümdede aralık tahmini ve önsav(hipotezler) tartışılacak. 3.Bölümde kullanılan örnekte tüketim- gelir ilişkisi tahmin edilmiş, yani nokta tahmini yapılmıştı. β 2 (^)=0.5091 3.Bölümde kullanılan örnekte tüketim- gelir ilişkisi tahmin edilmiş, yani nokta tahmini yapılmıştı. β 2 (^)=0.5091 Bu deger bilinmeyen anakütle degeri MtüE, β 2,için bir nokta tahminidir. Bu deger bilinmeyen anakütle degeri MtüE, β 2,için bir nokta tahminidir. Bu tahmini deger β2(^) ne kadar güvene biliriz? Farklı örneklem farklı sonuç çıkartabilir. Bu tahmini deger β2(^) ne kadar güvene biliriz? Farklı örneklem farklı sonuç çıkartabilir.
 tartışılacak. 3.Bölümde kullanılan örnekte tüketim- gelir ilişkisi tahmin edilmiş, yani nokta tahmini yapılmıştı. β 2 (^)= Bölümde kullanılan örnekte tüketim- gelir ilişkisi tahmin edilmiş, yani nokta tahmini yapılmıştı. β 2 (^)= Bu deger bilinmeyen anakütle degeri MtüE, β 2,için bir nokta tahminidir. Bu deger bilinmeyen anakütle degeri MtüE, β 2,için bir nokta tahminidir. Bu tahmini deger β2(^) ne kadar güvene biliriz. Farklı örneklem farklı sonuç çıkartabilir. Bu tahmini deger β2(^) ne kadar güvene biliriz. Farklı örneklem farklı sonuç çıkartabilir..")
3
Yalnızca nokta tahminine güvenmek yerine onun bir,iki ya da üç standart hata uzaklığa kadar uzanan öyle bir aralık oluşturabiliriz ki bu aralık, diyelim yüzde 95 olasılıkla anakütlenin gerçek katsayısını içersin, bu tesbit edilen aralık aralık tahmini olarak bilinir. Yalnızca nokta tahminine güvenmek yerine onun bir,iki ya da üç standart hata uzaklığa kadar uzanan öyle bir aralık oluşturabiliriz ki bu aralık, diyelim yüzde 95 olasılıkla anakütlenin gerçek katsayısını içersin, bu tesbit edilen aralık aralık tahmini olarak bilinir. Soru: β 2 ^ ana kütle degerine ne kadar yakın? Pr ( β 2 (^) − δ≤β 2 ≤ β 2 (^) + δ ) = 1 − α 1 − α = Güven katsayısı 1 − α = Güven katsayısı α ( 0< α < 1) = Anlamlık düzeyi α ( 0< α < 1) = Anlamlık düzeyi β2(^) – δ = Alt güven sınırı β2(^) – δ = Alt güven sınırı β2(^) + δ = Üst güven sınırı β2(^) + δ = Üst güven sınırı
 − δ≤β 2 ≤ β 2 (^) + δ ) = 1 − α 1 − α = Güven katsayısı 1 − α = Güven katsayısı α ( 0< α < 1) = Anlamlık düzeyi α ( 0< α < 1) = Anlamlık düzeyi β2(^) – δ = Alt güven sınırı β2(^) – δ = Alt güven sınırı β2(^) + δ = Üst güven sınırı β2(^) + δ = Üst güven sınırı.")
4
Aralık tahmininin şu yönlerini bilmek çok önemlidir : Formülde β2’ nin verilen sınırlar arasında bulunma olasılığının 1 – α olduğunu söylemez.Sadece β2’ yi içerme olasılığınınFormülde β2’ nin verilen sınırlar arasında bulunma olasılığının 1 – α olduğunu söylemez.Sadece β2’ yi içerme olasılığının 1 – α olan bir aralık kurulabileceğidir 1 – α olan bir aralık kurulabileceğidir Bir örneklemden diğerine geçildikçe aralık değişebilecektir.Bir örneklemden diğerine geçildikçe aralık değişebilecektir. Eğer yinelenen örneklemlerde güven aralıkları 1 – α olasılığı temelinde pek çok kez belirlenirse, uzun dönemde ortalama olarak bu aralıkların yüzde 1 – α kadarı anakütle katsayısının gerçek değerini içinde barındırır.Eğer yinelenen örneklemlerde güven aralıkları 1 – α olasılığı temelinde pek çok kez belirlenirse, uzun dönemde ortalama olarak bu aralıkların yüzde 1 – α kadarı anakütle katsayısının gerçek değerini içinde barındırır.

5
Regresyon Katsayıları β1 ve β2 için Güven Aralıgı Regresyon Katsayıları β1 ve β2 için Güven Aralıgı β 2 (^) – β 2 β 2 (^) – β 2 Z = ————— Z = ————— sh(β 2 (^)) sh(β 2 (^)) (β 2 (^) – β 2 ) √ ∑ xi 2 (β 2 (^) – β 2 ) √ ∑ xi 2 Z = ———————— Z = ———————— σ σ σ2 anakütlenin varyansı veya (σ anakütle standart hatası) biliniyorsa σ2 anakütlenin varyansı veya (σ anakütle standart hatası) biliniyorsa normal eğrinin altındaki alanın normal eğrinin altındaki alanın μ ± σ aralığında yaklaşık yüzde 68, μ ± σ aralığında yaklaşık yüzde 68, μ ± 2σ aralığında yaklaşık yüzde 95, μ ± 2σ aralığında yaklaşık yüzde 95, μ ± 3σ aralığında yaklaşık yüzde 99.7 olduğudur. μ ± 3σ aralığında yaklaşık yüzde 99.7 olduğudur.

6
Şayet σ 2 bilinmiyorsa onun yerine tahmin edilen Şayet σ 2 bilinmiyorsa onun yerine tahmin edilen σ(^) 2 varyans kullanılır ve önceki denklemde şu şekilde yazılır. σ(^) 2 varyans kullanılır ve önceki denklemde şu şekilde yazılır. β2(^) – β2 tahmin edici – anakütle katsayısı β2(^) – β2 tahmin edici – anakütle katsayısı t = ————— = —————————————— t = ————— = —————————————— sh( β2(^)) tahmin edicinin tahmin edilmiş standart hatası sh( β2(^)) tahmin edicinin tahmin edilmiş standart hatası (β 2 (^) – β 2 ) √ ∑xi 2 (β 2 (^) – β 2 ) √ ∑xi 2 t= ————————— t= ————————— σ(^) σ(^) Öyleyse β2 için bir güven aralığı kurmak istersek normal dağılım yerine t dağılımını şöyle kullanabiliriz : Öyleyse β2 için bir güven aralığı kurmak istersek normal dağılım yerine t dağılımını şöyle kullanabiliriz : Pr(-tα / 2 ≤ t ≤ tα / 2 ) = 1 – α Pr(-tα / 2 ≤ t ≤ tα / 2 ) = 1 – α
 2 varyans kullanılır ve önceki denklemde şu şekilde yazılır. β2(^) – β2 tahmin edici – anakütle katsayısı β2(^) – β2 tahmin edici – anakütle katsayısı t = ————— = —————————————— t = ————— = —————————————— sh( β2(^)) tahmin edicinin tahmin edilmiş standart hatası sh( β2(^)) tahmin edicinin tahmin edilmiş standart hatası (β 2 (^) – β 2 ) √ ∑xi 2 (β 2 (^) – β 2 ) √ ∑xi 2 t= ————————— t= ————————— σ(^) σ(^) Öyleyse β2 için bir güven aralığı kurmak istersek normal dağılım yerine t dağılımını şöyle kullanabiliriz : Öyleyse β2 için bir güven aralığı kurmak istersek normal dağılım yerine t dağılımını şöyle kullanabiliriz : Pr(-tα / 2 ≤ t ≤ tα / 2 ) = 1 – α Pr(-tα / 2 ≤ t ≤ tα / 2 ) = 1 – α.")
7
Sayfa 118

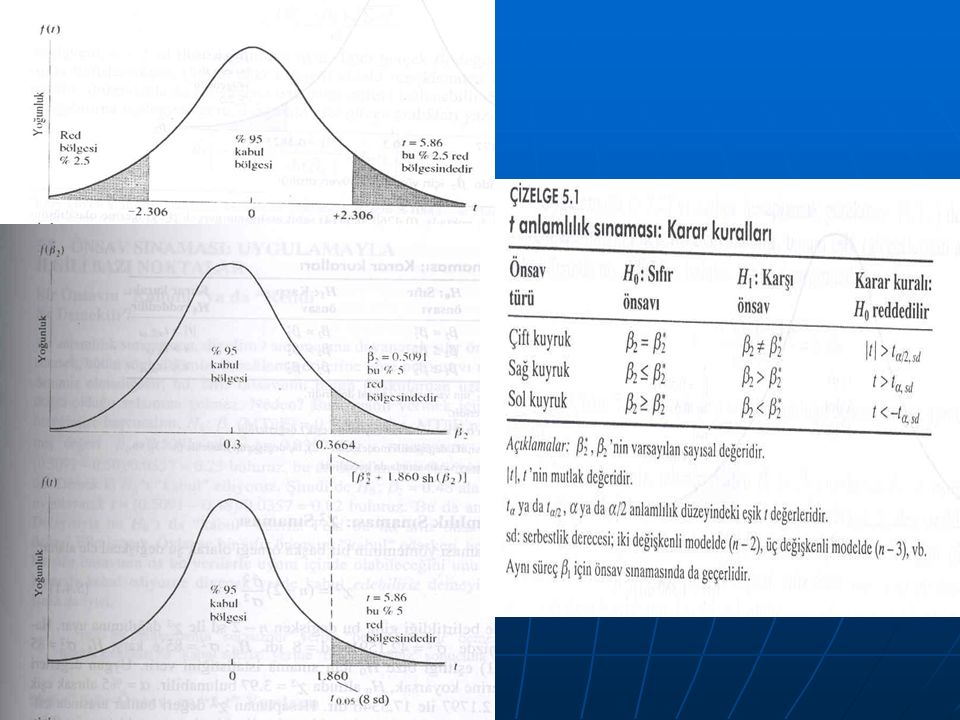
8
Standart hata ne kadar büyükse güven aralığıda o kadar geniş olur. Örneğin tüketim gelir örneğinde β 2 (^) = 0.5091, sh(β 2 (^)= 0.0357, sd = 8 bulmuştuk. α = %5, güven katsayısı %95 alırsak t çizelgesinden 8 sd için eşik değerinin t α /2 = t 0.025 =2.306 olduğunu görürüz.O zaman β 2 için %95 güven aralığını şöyle bulunur : güven katsayısı %95 alırsak t çizelgesinden 8 sd için eşik değerinin t α /2 = t 0.025 =2.306 olduğunu görürüz.O zaman β 2 için %95 güven aralığını şöyle bulunur : 0.4268 ≤ β 2 ≤ 0.5914 0.4268 ≤ β 2 ≤ 0.5914 ya da ya da 0.5091 ± 2.306(0.0357) buda eşittir 0.5091 ± 0.0823 0.5091 ± 2.306(0.0357) buda eşittir 0.5091 ± 0.0823Yorumu Bu aralık orneklem degıstıkçe birçok benzer aralık yazılabılır ve bu aralıklardan 100 tanesinin 95 inde gerçek β 2 degeri bulunur. Bu aralık orneklem degıstıkçe birçok benzer aralık yazılabılır ve bu aralıklardan 100 tanesinin 95 inde gerçek β 2 degeri bulunur.
 = , sh(β 2 (^)= , sd = 8 bulmuştuk. α = %5, güven katsayısı %95 alırsak t çizelgesinden 8 sd için eşik değerinin t α /2 = t =2.306 olduğunu görürüz.O zaman β 2 için %95 güven aralığını şöyle bulunur : güven katsayısı %95 alırsak t çizelgesinden 8 sd için eşik değerinin t α /2 = t =2.306 olduğunu görürüz.O zaman β 2 için %95 güven aralığını şöyle bulunur : ≤ β 2 ≤ ≤ β 2 ≤ ya da ya da ± 2.306(0.0357) buda eşittir ± ± 2.306(0.0357) buda eşittir ± Yorumu Bu aralık orneklem degıstıkçe birçok benzer aralık yazılabılır ve bu aralıklardan 100 tanesinin 95 inde gerçek β 2 degeri bulunur. Bu aralık orneklem degıstıkçe birçok benzer aralık yazılabılır ve bu aralıklardan 100 tanesinin 95 inde gerçek β 2 degeri bulunur..")
10
Many Samples Have Same Interval x_ XXXX

11
x_ XXXX X = ± Z x

12
Many Samples Have Same Interval 90% Samples x_ XXXX X = ± Z x +1.65 x -1.65 x

13
Many Samples Have Same Interval 90% Samples 95% Samples +1.65 x x_ XXXX +1.96 x -1.65 x -1.96 x X = ± Z x

14
Many Samples Have Same Interval 90% Samples 95% Samples 99% Samples +1.65 x +2.58 x x_ XXXX +1.96 x -2.58 x -1.65 x -1.96 x X = ± Z x Standard Sapma nın küçük olması ile gözlem sayısı arasındaki ilişki?

15
Z t Student’s t Distribution 0 t (df = 5) Standard Normal t (df = 13) Bell-ShapedSymmetric ‘Fatter’ Tails
 Standard Normal t (df = 13) Bell-ShapedSymmetric ‘Fatter’ Tails")
16
t Tablosunda istenen deger nasıl okunur yani kritik deger nasıl bulunur:

17
Student’s t Table

18
t values

19
Student’s t Table t values / 2

20
Student’s t Table t values / 2 Assume: n = 3 df= n - 1 = 2 =.10 /2 =.05

21
Student’s t Table t values / 2 Assume: n = 3 df= n - 1 = 2 =.10 /2 =.05

22
Student’s t Table t critik degeri / 2 Assume: n = 3 df= n - 1 = 2 =.10 /2 =.05.05 S.Derecesi

23
Student’s t Table Assume: n = 3 df= n - 1 = 2 =.10 /2 =.05 2.920 t values / 2.05

24
Şayet sorulan β 2 aralıgı degılde ortalama degerin aralıgı sorulursa : Mean ( Unknown) A random sample of n = 25 hasx = 50 & s = 8. Set up a 95% confidence interval estimate for . A random sample of n = 25 hasx = 50 & s = 8. Set up a 95% confidence interval estimate for .

25
Ortalama degerinin güven aralıgı Mean ( Unknown) A random sample of n = 25 hasx = 50 & s = 8. Set up a 95% confidence interval estimate for . A random sample of n = 25 hasx = 50 & s = 8. Set up a 95% confidence interval estimate for .

26
Thinking Challenge Bir ürünün test edilme süresi ölçülmüş ve şu degerler alınmiş (min.): 3.6, 4.2, 4.0, 3.5, 3.8, 3.1. Bir ürünün test edilme süresi ölçülmüş ve şu degerler alınmiş (min.): 3.6, 4.2, 4.0, 3.5, 3.8, 3.1. 90% güven aralıgında bu ana kutle degerlerinin ortalama test etme yani ölçüm degeri bulunuz 90% güven aralıgında bu ana kutle degerlerinin ortalama test etme yani ölçüm degeri bulunuz
: 3.6, 4.2, 4.0, 3.5, 3.8, % güven aralıgında bu ana kutle degerlerinin ortalama test etme yani ölçüm degeri bulunuz 90% güven aralıgında bu ana kutle degerlerinin ortalama test etme yani ölçüm degeri bulunuz.")
27
Confidence Interval Solution* X = 3.7 X = 3.7 S = 3.8987 S = 3.8987 n = 6, df = n - 1 = 6 - 1 = 5 n = 6, df = n - 1 = 6 - 1 = 5 S / n = 3.8987 / 6 = 1.592 S / n = 3.8987 / 6 = 1.592 t.05,5 = 2.0150 t.05,5 = 2.0150 3.7 - (2.015)(1.592) 3.7 + (2.015)(1.592) 3.7 - (2.015)(1.592) 3.7 + (2.015)(1.592) 0.492 6.908 0.492 6.908 Data 3.6, 4.2, 4.0, 3.5, 3.8, 3.1.
(1.592) 3.7 + (2.015)(1.592) (2.015)(1.592) 3.7 + (2.015)(1.592) Data 3.6, 4.2, 4.0, 3.5, 3.8, 3.1.")
28
σ 2 için %95 güven aralığı şöyledir : σ 2 için %95 güven aralığı şöyledir : 19.2347 ≤ σ2 ≤ 154.7336 19.2347 ≤ σ2 ≤ 154.7336 Şayet sorulan β2 aralıgı veya ortalama deger degilde sadece ve sadece varyans degerinin güven aralıgı ise güven aralıgı ise

29
σ² İÇİN GÜVEN ARALIĞI σ² için %95 güven aralıgı hesaplanırsa bunun anlamı gercek σ²bu sınırlar içinde olma olasılıgı yuzde 95 dir σ² için %95 güven aralıgı hesaplanırsa bunun anlamı gercek σ²bu sınırlar içinde olma olasılıgı yuzde 95 dir

30
Onsav Sınamaları Hipotez Testleri

31
5.6. ÖNSAV SINAMASI:GÜVEN ARALIĞI YAKLAŞIMI 5.6. ÖNSAV SINAMASI:GÜVEN ARALIĞI YAKLAŞIMI Verili bir gözlem ya da bulgu, belli bir önsav ile uyuşuyor mu, uyuşmuyor mu? Buradaki “uyuşmak” sözcüğü, önsavdaki değere, bu önsavı reddetmememizi sağlamaya “yetecek derecede” yakın anlamındadır. Verili bir gözlem ya da bulgu, belli bir önsav ile uyuşuyor mu, uyuşmuyor mu? Buradaki “uyuşmak” sözcüğü, önsavdaki değere, bu önsavı reddetmememizi sağlamaya “yetecek derecede” yakın anlamındadır. H 0 sıfır önsavı: İleri sürülen önsava istatistik dilinde denir H 0 sıfır önsavı: İleri sürülen önsava istatistik dilinde denir Sıfır önsavı, genellikle, H1 ile gösterilen bir karşı önsava karşı sınanır Sıfır önsavı, genellikle, H1 ile gösterilen bir karşı önsava karşı sınanır Tüketim gelir örneğini düşünürsek tahmin edilen marjinal tüketim eğilimi (MTÜE) β2(^), 0.5091 dir.Şunu ileri sürdüğümüzü düşünelim : Tüketim gelir örneğini düşünürsek tahmin edilen marjinal tüketim eğilimi (MTÜE) β2(^), 0.5091 dir.Şunu ileri sürdüğümüzü düşünelim : H0 = β2 = 0.3 H0 = β2 = 0.3 H1 = β2 ≠ 0.3 H1 = β2 ≠ 0.3 Yani, sıfır önsavına göre MTÜE 0.3, karşı önsava göre 0.3 ten küçük ya da büyüktür. Yani, sıfır önsavına göre MTÜE 0.3, karşı önsava göre 0.3 ten küçük ya da büyüktür.
 β2(^), dir.Şunu ileri sürdüğümüzü düşünelim : Tüketim gelir örneğini düşünürsek tahmin edilen marjinal tüketim eğilimi (MTÜE) β2(^), dir.Şunu ileri sürdüğümüzü düşünelim : H0 = β2 = 0.3 H0 = β2 = 0.3 H1 = β2 ≠ 0.3 H1 = β2 ≠ 0.3 Yani, sıfır önsavına göre MTÜE 0.3, karşı önsava göre 0.3 ten küçük ya da büyüktür. Yani, sıfır önsavına göre MTÜE 0.3, karşı önsava göre 0.3 ten küçük ya da büyüktür..")
32
Karar kuralı : β2 için 100(1 – α ) güven aralığını belirleyin. Eğer H0 altındaki β2 bu güven aralığının içindeyse H0’ ı reddetmeyin, ama bu aralığın dışına düşüyorsa H0’ ı reddedin. Karar kuralı : β2 için 100(1 – α ) güven aralığını belirleyin. Eğer H0 altındaki β2 bu güven aralığının içindeyse H0’ ı reddetmeyin, ama bu aralığın dışına düşüyorsa H0’ ı reddedin. marjinal tüketim eğilimi (MTÜE) β2(^), 0.5091 marjinal tüketim eğilimi (MTÜE) β2(^), 0.5091
 güven aralığını belirleyin. Eğer H0 altındaki β2 bu güven aralığının içindeyse H0’ ı reddetmeyin, ama bu aralığın dışına düşüyorsa H0’ ı reddedin. marjinal tüketim eğilimi (MTÜE) β2(^), marjinal tüketim eğilimi (MTÜE) β2(^),")
33
Sıfır önsavını reddedince, bulgumuzun istatistik bakımından anlamlı olduğunu söyleriz. Öte yandan sıfır önsavını reddetmediğimizde bulgumuz istatistik bakımından anlamlı değıldir deriz. Sıfır önsavını reddedince, bulgumuzun istatistik bakımından anlamlı olduğunu söyleriz. Öte yandan sıfır önsavını reddetmediğimizde bulgumuz istatistik bakımından anlamlı değıldir deriz. Bazen karşı önsavımız iki yanlı değil tek yanlı da olabilir.Örneğin : Bazen karşı önsavımız iki yanlı değil tek yanlı da olabilir.Örneğin : H0 : β2 ≤ 0.3 ve H1 : β2 > 0.3 H0 : β2 ≤ 0.3 ve H1 : β2 > 0.3

34
ÖNSAV SINAMASI:ANLAMLILIK SINAMASI YAKLAŞIMI Anlamlılık sınaması, örneklem sonuçlarının, bir sıfır önsavının doğrulandığını mı yoksa yanlışlandığını mı görmek için kullandığı bir süreçtir. Anlamlılık sınaması, örneklem sonuçlarının, bir sıfır önsavının doğrulandığını mı yoksa yanlışlandığını mı görmek için kullandığı bir süreçtir. Normallik varsayımı altında, Normallik varsayımı altında, β2(^) – β2 β2(^) – β2 t = ————— t = ————— sh( β2(^)) sh( β2(^)) ( β2(^) – β2) √ ∑ xi2 ( β2(^) – β2) √ ∑ xi2 t= ——————------—— t= ——————------—— σ(^) σ(^)
 – β2 β2(^) – β2 t = ————— t = ————— sh( β2(^)) sh( β2(^)) ( β2(^) – β2) √ ∑ xi2 ( β2(^) – β2) √ ∑ xi2 t= ——————------—— t= ——————------—— σ(^) σ(^).")
36
Pr [β2*-t α/2 sh(β2(^)) ≤ β2(^) ≤ [ β2*+t α/2 sh(β2(^))] = 1 – α buradaki %100(1 – α) güven arlığına kabul bölgesi denir; güven aralığının dışındaki bölgeler de red bölgesi ya da eşik dışı bölge diye anılır. güven aralığının dışındaki bölgeler de red bölgesi ya da eşik dışı bölge diye anılır. Tüketim gelir örneğimiz de β2 (^) = 0.05091, sh( β2(^)) = 0.0357, sd = 8 olduğunu biliyoruz. α= %5 alırsak, t α/2=2.306 olur. Tüketim gelir örneğimiz de β2 (^) = 0.05091, sh( β2(^)) = 0.0357, sd = 8 olduğunu biliyoruz. α= %5 alırsak, t α/2=2.306 olur. H0 : β2 = β2* = 0.3, H1 : β2 ≠ 0.3 alırsak şöyle olur : H0 : β2 = β2* = 0.3, H1 : β2 ≠ 0.3 alırsak şöyle olur : Pr( 0.2177 ≤ β2(^) ≤ 0.3823 ) = 0.95 β2(^) eşik dışı bölgede yer aldığından, gerçek β2 = 0.3 sıfır önsavını redderiz. Pr( 0.2177 ≤ β2(^) ≤ 0.3823 ) = 0.95 β2(^) eşik dışı bölgede yer aldığından, gerçek β2 = 0.3 sıfır önsavını redderiz. 0.5091 – 0.3 0.5091 – 0.3 t = —————— = 5.86 sonuç aynıdır, H0 reddedilir. t = —————— = 5.86 sonuç aynıdır, H0 reddedilir. 0.0357 0.0357 t dağılımını kullandığımıza göre, bu sınama sürecine pekala t dağılımını kullandığımıza göre, bu sınama sürecine pekala t sınaması diyebiliriz. Anlamlılık sınamalarının diliyle, bir sınama istatistiği eşik dışı bölgedeyse, o istatistiğe istatistik bakımından anlamlıdır denir. Bu durumda sıfır önsavı reddedilir. Aynı biçimde, bir sınama istatistiği kabul bölgesindeyse, o sınama istatistik bakımından anlamlı değildir denir. t sınaması diyebiliriz. Anlamlılık sınamalarının diliyle, bir sınama istatistiği eşik dışı bölgedeyse, o istatistiğe istatistik bakımından anlamlıdır denir. Bu durumda sıfır önsavı reddedilir. Aynı biçimde, bir sınama istatistiği kabul bölgesindeyse, o sınama istatistik bakımından anlamlı değildir denir.
![Pr [β2*-t α/2 sh(β2(^)) ≤ β2(^) ≤ [ β2*+t α/2 sh(β2(^))] = 1 – α buradaki %100(1 – α) güven arlığına kabul bölgesi denir; güven aralığının dışındaki bölgeler de red bölgesi ya da eşik dışı bölge diye anılır.](http://images.slideplayer.biz.tr/32/9882381/slides/slide_36.jpg "güven aralığının dışındaki bölgeler de red bölgesi ya da eşik dışı bölge diye anılır. Tüketim gelir örneğimiz de β2 (^) = , sh( β2(^)) = , sd = 8 olduğunu biliyoruz. α= %5 alırsak, t α/2=2.306 olur. Tüketim gelir örneğimiz de β2 (^) = , sh( β2(^)) = , sd = 8 olduğunu biliyoruz. α= %5 alırsak, t α/2=2.306 olur. H0 : β2 = β2* = 0.3, H1 : β2 ≠ 0.3 alırsak şöyle olur : H0 : β2 = β2* = 0.3, H1 : β2 ≠ 0.3 alırsak şöyle olur : Pr( ≤ β2(^) ≤ ) = 0.95 β2(^) eşik dışı bölgede yer aldığından, gerçek β2 = 0.3 sıfır önsavını redderiz. Pr( ≤ β2(^) ≤ ) = 0.95 β2(^) eşik dışı bölgede yer aldığından, gerçek β2 = 0.3 sıfır önsavını redderiz – – 0.3 t = —————— = 5.86 sonuç aynıdır, H0 reddedilir. t = —————— = 5.86 sonuç aynıdır, H0 reddedilir t dağılımını kullandığımıza göre, bu sınama sürecine pekala t dağılımını kullandığımıza göre, bu sınama sürecine pekala t sınaması diyebiliriz. Anlamlılık sınamalarının diliyle, bir sınama istatistiği eşik dışı bölgedeyse, o istatistiğe istatistik bakımından anlamlıdır denir. Bu durumda sıfır önsavı reddedilir. Aynı biçimde, bir sınama istatistiği kabul bölgesindeyse, o sınama istatistik bakımından anlamlı değildir denir. t sınaması diyebiliriz. Anlamlılık sınamalarının diliyle, bir sınama istatistiği eşik dışı bölgedeyse, o istatistiğe istatistik bakımından anlamlıdır denir. Bu durumda sıfır önsavı reddedilir. Aynı biçimde, bir sınama istatistiği kabul bölgesindeyse, o sınama istatistik bakımından anlamlı değildir denir..")
37
Inferences about the Slope: t Test t Test for a Population Slope Is a Linear Relationship Between X & Y ? Test Statistic: and df = n - 2 Null and Alternative Hypotheses H 0 : 1 = 0(No Linear Relationship) H 1 : 1 0(Linear Relationship) Where
 H 1 : 1 0(Linear Relationship) Where.")
38
Example: Produce Stores Data for 7 Stores: Regression Model Obtained: The slope of this model is 1.487. Is there a linear relationship between the square footage of a store and its annual sales? Annual Store Square Sales Feet($000) 1 1,726 3,681 2 1,542 3,395 3 2,816 6,653 4 5,555 9,543 5 1,292 3,318 6 2,208 5,563 7 1,313 3,760 Y i = 1636.415 +1.487X i
 1 1,726 3, ,542 3, ,816 6, ,555 9, ,292 3, ,208 5, ,313 3,760 Y i = X i.")
39
H 0 : 1 = 0 H 0 : 1 = 0 H 1 : 1 0 H 1 : 1 0 .05 .05 df 7 - 2 = 7 df 7 - 2 = 7 Critical Value(s): Critical Value(s): Test Statistic: Karar: Yorum: Katsayının sıfırdan farklı olması demek fonksiyonun linear (dogrusal fonk) oldugunu ıfade eder t 02.5706-2.5706.025 Reject.025 From Excel Printout Red : H 0 Inferences about the Slope: t Test Example P-test?
: Critical Value(s): Test Statistic: Karar: Yorum: Katsayının sıfırdan farklı olması demek fonksiyonun linear (dogrusal fonk) oldugunu ıfade eder t Reject.025 From Excel Printout Red : H 0 Inferences about the Slope: t Test Example P-test")
40
Inferences about the Slope: Güven Aralıgı Örnegi Katsayi için güven aralıgı b 1 t n-2 Excel Printout for Produce Stores At 95% level of Confidence The confidence Interval for the slope is (1.062, 1.911). Does not include 0. Yorum: Yıllık Satış ile İş yerinin büyüklügü arasında dogrusal bir ilişkinin varlıgı t-test ile ispat edilmiştir.

41
σ² için Anlamlılık Sınaması σ² için Anlamlılık Sınaması σ 2 (^) σ 2 (^) X2 = ( n – 2 ) ——— X2 = ( n – 2 ) ——— σ 2 σ 2
 σ 2 (^) X2 = ( n – 2 ) ——— X2 = ( n – 2 ) ——— σ 2 σ 2")
42
The p-Value of a Hypothesis Test The p-value of a test is calculated by finding the probability that the t- distribution can take a value greater than or equal to the absolute value of the sample value of the test statistic. The p-value of a test is calculated by finding the probability that the t- distribution can take a value greater than or equal to the absolute value of the sample value of the test statistic. Rejection rule for a two-tailed test: When the p-value of a hypothesis test is smaller than the chosen value of , then the test procedure leads to rejection of the null hypothesis. Rejection rule for a two-tailed test: When the p-value of a hypothesis test is smaller than the chosen value of , then the test procedure leads to rejection of the null hypothesis. If the p-value is greater than we do not reject the null hypothesis. If the p-value is greater than we do not reject the null hypothesis. In the food expenditure example the p- value for the test of H0: 2 =.10 against H1: 2 .10 is In the food expenditure example the p- value for the test of H0: 2 =.10 against H1: 2 .10 is p=.3601, which is the area in the tails of the t(38) distribution where |t|.9263 p=.3601, which is the area in the tails of the t(38) distribution where |t|.9263
 distribution where |t|.9263 p=.3601, which is the area in the tails of the t(38) distribution where |t|")
43
F-Test ∑ yi 2 = ∑ ŷi 2 + ∑ ûi 2 = β2 2 (^) ∑ xi 2 + ∑ ûi 2 BKT = AKT + KKT BKT = AKT + KKT BKT = Bütün kareler toplamı BKT = Bütün kareler toplamı AKT = Açıklanan kareler toplamı AKT = Açıklanan kareler toplamı KKT = Kalıntı kareleri toplamı, BKT nin bu parçalarının incelenmesi regresyon açısından varyans çözümlemesi (VARÇÖZ ) diye bilinir. KKT = Kalıntı kareleri toplamı, BKT nin bu parçalarının incelenmesi regresyon açısından varyans çözümlemesi (VARÇÖZ ) diye bilinir. AKT nin OKT si AKT nin OKT si F = ———————— F = ———————— KKT nin OKT si KKT nin OKT si β 2 2 (^) ∑ xi 2 β 2 2 (^) ∑ xi 2 β 2 2 (^) ∑ xi 2 β 2 2 (^) ∑ xi 2 F = ———————— F = ——————— F = ———————— F = ——————— ∑ ûi 2 / (n – 2) σ 2 (^) ∑ ûi 2 / (n – 2) σ 2 (^) F testi tek degişkenli modelde t-test ile aynı anlam ifade ederken çoklu degişkenlerde çok güçlü bir anlamı vardır F testi tek degişkenli modelde t-test ile aynı anlam ifade ederken çoklu degişkenlerde çok güçlü bir anlamı vardır
 diye bilinir. AKT nin OKT si AKT nin OKT si F = ———————— F = ———————— KKT nin OKT si KKT nin OKT si β 2 2 (^) ∑ xi 2 β 2 2 (^) ∑ xi 2 β 2 2 (^) ∑ xi 2 β 2 2 (^) ∑ xi 2 F = ———————— F = ——————— F = ———————— F = ——————— ∑ ûi 2 / (n – 2) σ 2 (^) ∑ ûi 2 / (n – 2) σ 2 (^) F testi tek degişkenli modelde t-test ile aynı anlam ifade ederken çoklu degişkenlerde çok güçlü bir anlamı vardır F testi tek degişkenli modelde t-test ile aynı anlam ifade ederken çoklu degişkenlerde çok güçlü bir anlamı vardır.")
44
REGRESYON ÇÖZÜMLEMESİ VE VARYANS ÇÖZÜMLEMESİ Bu oran F degerı

45
Syf:137 Regresyon Cözümlemesinin Uygulanması Ŷi = 24.4545 + 0.5091 Xi Ŷi = 24.4545 + 0.5091 Xi Seçilmiş bir X değerinin, diyelim X0 ın karşılığı olan Y koşullu olasılık değerinin kestirilmesi, ki bu regresyon doğrusunun üzerindeki noktanın ta kendisidir. Seçilmiş bir X değerinin, diyelim X0 ın karşılığı olan Y koşullu olasılık değerinin kestirilmesi, ki bu regresyon doğrusunun üzerindeki noktanın ta kendisidir. X = 100 iken E(Y | X0 = 100) kestirimini yapmak istiyoruz. Bu ortalama kestirimini şöyle bulabiliriz : X = 100 iken E(Y | X0 = 100) kestirimini yapmak istiyoruz. Bu ortalama kestirimini şöyle bulabiliriz : Ŷ0 = β1(^) + β2(^)X0 Ŷ0 = β1(^) + β2(^)X0 = 24.4545 + 0.5091(100) = 24.4545 + 0.5091(100) = 75.3645 = 75.3645 Burada Ŷ0 = E(Y | X0 ) ın tahmin edicisidir. Burada Ŷ0 = E(Y | X0 ) ın tahmin edicisidir. 1 (X0 – X( ¯ ) ) 1 (X0 – X( ¯ ) ) Var (Ŷ0 ) = σ2 [ —— + —————— ] Var (Ŷ0 ) = σ2 [ —— + —————— ] n ∑ xi2 n ∑ xi2 Bilinmeyen σ2 yerine sapmasız tahmin edicisi σ2(^) konursa, Bilinmeyen σ2 yerine sapmasız tahmin edicisi σ2(^) konursa, Ŷ0 – ( β1 + β2X0 ) Ŷ0 – ( β1 + β2X0 ) t = —-——————— t = —-——————— sh(Ŷ 0 ) sh(Ŷ 0 )
 kestirimini yapmak istiyoruz. Bu ortalama kestirimini şöyle bulabiliriz : X = 100 iken E(Y | X0 = 100) kestirimini yapmak istiyoruz. Bu ortalama kestirimini şöyle bulabiliriz : Ŷ0 = β1(^) + β2(^)X0 Ŷ0 = β1(^) + β2(^)X0 = (100) = (100) = = Burada Ŷ0 = E(Y | X0 ) ın tahmin edicisidir. Burada Ŷ0 = E(Y | X0 ) ın tahmin edicisidir. 1 (X0 – X( ¯ ) ) 1 (X0 – X( ¯ ) ) Var (Ŷ0 ) = σ2 [ —— + —————— ] Var (Ŷ0 ) = σ2 [ —— + —————— ] n ∑ xi2 n ∑ xi2 Bilinmeyen σ2 yerine sapmasız tahmin edicisi σ2(^) konursa, Bilinmeyen σ2 yerine sapmasız tahmin edicisi σ2(^) konursa, Ŷ0 – ( β1 + β2X0 ) Ŷ0 – ( β1 + β2X0 ) t = —-——————— t = —-——————— sh(Ŷ 0 ) sh(Ŷ 0 ).")
46
Biçimindeki t değişkeni, n- 2 sd ile t dağılımına uyar.Demek ki t dağılımı, gerçek E(Y0 | X0 ) değerinin güven aralığını bulmakta ve alıştığımız yolla bunun önsav sınamasını yapmakta kullanılabilir, yani, Biçimindeki t değişkeni, n- 2 sd ile t dağılımına uyar.Demek ki t dağılımı, gerçek E(Y0 | X0 ) değerinin güven aralığını bulmakta ve alıştığımız yolla bunun önsav sınamasını yapmakta kullanılabilir, yani, Pr[ β1(^) + β2(^)X0 – t α / 2 sh(Ŷ0) ≤ β1 + β2X0 ≤ β1(^) + β2(^)X0 + t α / 2 sh(Ŷ0) ] = 1 – α Pr[ β1(^) + β2(^)X0 – t α / 2 sh(Ŷ0) ≤ β1 + β2X0 ≤ β1(^) + β2(^)X0 + t α / 2 sh(Ŷ0) ] = 1 – α Verileri yerine koyarsak : Verileri yerine koyarsak : 1 (100 – 170)2 1 (100 – 170)2 Var ( Ŷ0 ) = 42.159 [ —— + ———-----——] Var ( Ŷ0 ) = 42.159 [ —— + ———-----——] 10 33,000 10 33,000 = 10.4759 = 10.4759 sh(Ŷ0) = 3.2366 sh(Ŷ0) = 3.2366 Dolayısıyla gerçek E(Y | X0 ) = β1 + β2X0 için %95 güven aralığı şöyle gösterilebilir : Dolayısıyla gerçek E(Y | X0 ) = β1 + β2X0 için %95 güven aralığı şöyle gösterilebilir : 75.3645 – 2.306(3.2366) ≤ E(Y | X0 = 100) ≤ 75.3645 + 2.306(3.2366) yani; 75.3645 – 2.306(3.2366) ≤ E(Y | X0 = 100) ≤ 75.3645 + 2.306(3.2366) yani; 67.9010 ≤ E(Y | X0 = 100) ≤ 82.8381 Öyleyse X0 = 100 veriyken, 67.9010 ≤ E(Y | X0 = 100) ≤ 82.8381 Öyleyse X0 = 100 veriyken, yinelenen örneklemlerin 100 ünden 95 inde bu aralıklar gerçek ortalama değeri içerirler. yinelenen örneklemlerin 100 ünden 95 inde bu aralıklar gerçek ortalama değeri içerirler.
![Biçimindeki t değişkeni, n- 2 sd ile t dağılımına uyar.Demek ki t dağılımı, gerçek E(Y0 | X0 ) değerinin güven aralığını bulmakta ve alıştığımız yolla bunun önsav sınamasını yapmakta kullanılabilir, yani, Biçimindeki t değişkeni, n- 2 sd ile t dağılımına uyar.Demek ki t dağılımı, gerçek E(Y0 | X0 ) değerinin güven aralığını bulmakta ve alıştığımız yolla bunun önsav sınamasını yapmakta kullanılabilir, yani, Pr[ β1(^) + β2(^)X0 – t α / 2 sh(Ŷ0) ≤ β1 + β2X0 ≤ β1(^) + β2(^)X0 + t α / 2 sh(Ŷ0) ] = 1 – α Pr[ β1(^) + β2(^)X0 – t α / 2 sh(Ŷ0) ≤ β1 + β2X0 ≤ β1(^) + β2(^)X0 + t α / 2 sh(Ŷ0) ] = 1 – α Verileri yerine koyarsak : Verileri yerine koyarsak : 1 (100 – 170)2 1 (100 – 170)2 Var ( Ŷ0 ) = [ —— + ———-----——] Var ( Ŷ0 ) = [ —— + ———-----——] 10 33, ,000 = = sh(Ŷ0) = sh(Ŷ0) = Dolayısıyla gerçek E(Y | X0 ) = β1 + β2X0 için %95 güven aralığı şöyle gösterilebilir : Dolayısıyla gerçek E(Y | X0 ) = β1 + β2X0 için %95 güven aralığı şöyle gösterilebilir : – 2.306(3.2366) ≤ E(Y | X0 = 100) ≤ (3.2366) yani; – 2.306(3.2366) ≤ E(Y | X0 = 100) ≤ (3.2366) yani; ≤ E(Y | X0 = 100) ≤ Öyleyse X0 = 100 veriyken, ≤ E(Y | X0 = 100) ≤ Öyleyse X0 = 100 veriyken, yinelenen örneklemlerin 100 ünden 95 inde bu aralıklar gerçek ortalama değeri içerirler.](http://images.slideplayer.biz.tr/32/9882381/slides/slide_46.jpg "yinelenen örneklemlerin 100 ünden 95 inde bu aralıklar gerçek ortalama değeri içerirler..")
47
Estimation of Predicted Values Confidence Interval Estimate for XY The Mean of Y given a particular X i t value from table with df=n-2 Standard error of the estimate Size of interval vary according to distance away from mean, X.

48
Estimation of Predicted Values Confidence Interval Estimate for Individual Response Y i at a Particular X i Addition of this 1 increased width of interval from that for the mean Y

49
Example: Produce Stores Y i = 1636.415 +1.487X i Data for 7 Stores: Regression Model Obtained: Predict the annual sales for a store with 2000 square feet. Annual Store Square Sales Feet($000) 1 1,726 3,681 2 1,542 3,395 3 2,816 6,653 4 5,555 9,543 5 1,292 3,318 6 2,208 5,563 7 1,313 3,760
 1 1,726 3, ,542 3, ,816 6, ,555 9, ,292 3, ,208 5, ,313 3,760.")
50
Estimation of Predicted Values: Example Confidence Interval Estimate for Individual Y Find the 95% confidence interval for the average annual sales for stores of 2,000 square feet Predicted Sales Y i = 1636.415 +1.487X i = 4610.45 ($000) X = 2350.29S YX = 611.75 t n-2 = t 5 = 2.5706 = 4610.45 980.97 Confidence interval for mean Y
 X = S YX = t n-2 = t 5 = = Confidence interval for mean Y")
51
Estimation of Predicted Values: Example Confidence Interval Estimate for XY Find the 95% confidence interval for annual sales of one particular stores of 2,000 square feet Predicted Sales Y i = 1636.415 +1.487X i = 4610.45 ($000) X = 2350.29S YX = 611.75 t n-2 = t 5 = 2.5706 = 4610.45 1853.45 Confidence interval for individual Y
 X = S YX = t n-2 = t 5 = = Confidence interval for individual Y")
52
Interval Estimates for Different Values of X X Y X Confidence Interval for a individual Y i A Given X Confidence Interval for the mean of Y Y i = b 0 + b 1 X i _

53
Tekil Kestirim

54
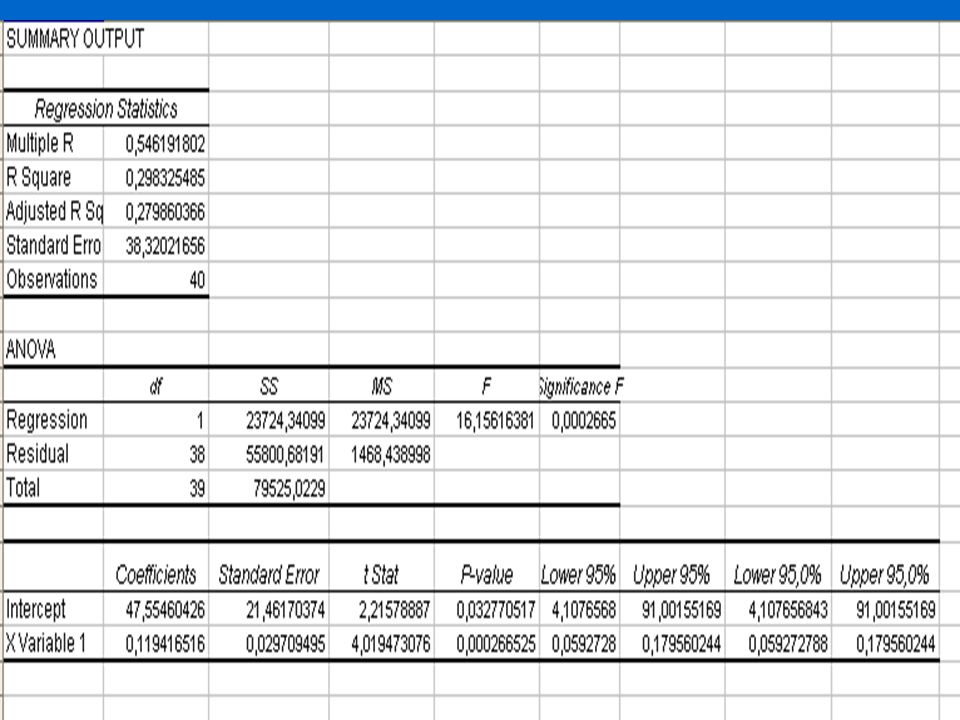
T=Coef/SE Coef F=23724/1468 P-test<0.05









>")












