Sunuyu indir
1
İrem Soydal ~ Yurdagül Ünal soydal@hacettepe.edu.trsoydal@hacettepe.edu.tr yurdagul@hacettepe.edu.tryurdagul@hacettepe.edu.tr

2
Bir bilgi erişim sisteminin temel işlevi, kullanıcıların bilgi ihtiyaçlarını karşılaması muhtemel, derlemdeki ilgili belgelerin tümüne erişmek, ilgili olmayanları da ayıklamaktır. ◦ İlgili: “Relevant” ◦ İlgililik: “Relevancy”

3
İlgili belgelerin tümüne ve salt ilgili belgelere erişim sağlamalı ! Birbirine benzeyen bilgileri bir araya getirmek, benzemeyenleri ayırmak İdeal bir bilgi erişim sistemi yaratmak neredeyse imkansız ◦ Milyonlarca kayıt / belge ◦ “ilgililik” kavramının öznelliği

4
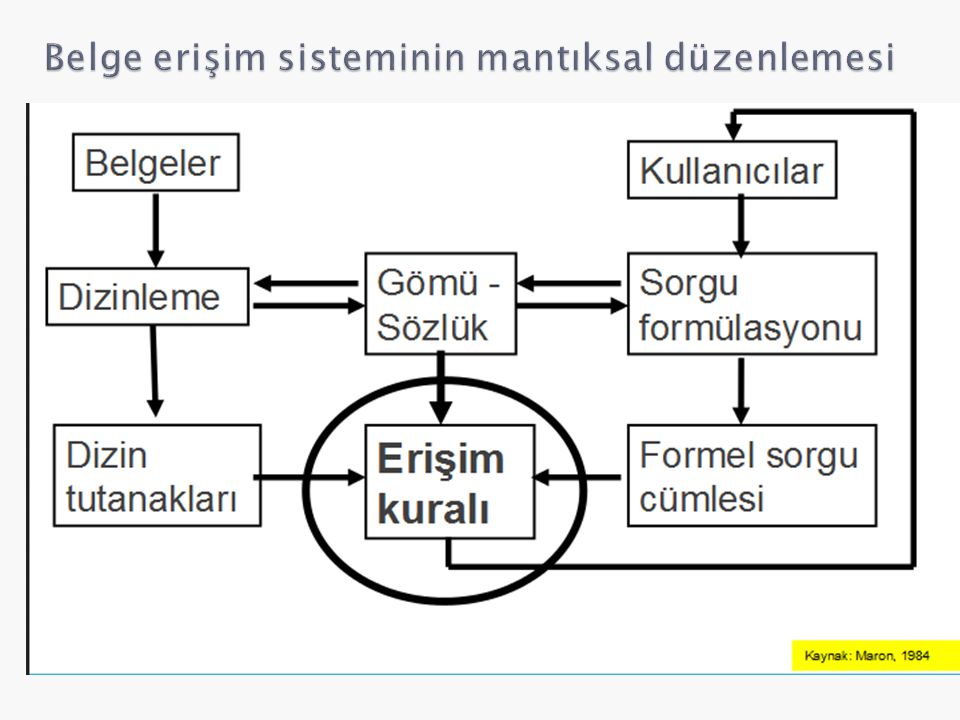
Bir bilgi erişim sisteminde ihtiyaç duyulan belgelere erişmek için sistemin iki koşulu yerine getirmesi gerekir: ◦ 1) Derleme eklenen her belgenin temel özellikleri geleneksel veya otomatik olarak gerçekleştirilen dizinleme işlemleri sırasında belirlenmeli ve her belge için ilgili dizin terimleri oluşturulmalıdır. Bir belge için oluşturulan söz konusu dizin terimleri bilgi erişim sırasında belgenin tamamını temsil etmek üzere kullanılır. ◦ 2) Kullanıcılar belgelere verilen bu dizin terimlerini doğru olarak tahmin edip sorgu cümlelerini ona göre oluşturmalıdırlar. Bir başka deyişle, kullanıcının bilgi ihtiyacını ifade etmek için kullandığı terimlerle belgeyi temsil eden dizin terimleri birbiriyle karşılaştırılır ve çakışan belgelere erişilir.
 Kullanıcılar belgelere verilen bu dizin terimlerini doğru olarak tahmin edip sorgu cümlelerini ona göre oluşturmalıdırlar. Bir başka deyişle, kullanıcının bilgi ihtiyacını ifade etmek için kullandığı terimlerle belgeyi temsil eden dizin terimleri birbiriyle karşılaştırılır ve çakışan belgelere erişilir..")
5
Bir bilgi erişim sistemi: ◦ (1) bir belge derlemi ya da bu belgeleri temsil eden dizin terimlerini içeren kayıtlar, ◦ (2) kullanıcıların sorgu cümleleri, ve ◦ (3) kullanıcıların sorgu cümlelerinde yer alan terimlerle derlemdeki belgelere verilen terimleri karşılaştırarak ilgili belgeleri belirlemek için kullanılan bir erişim kuralından oluşur.
 bir belge derlemi ya da bu belgeleri temsil eden dizin terimlerini içeren kayıtlar, ◦ (2) kullanıcıların sorgu cümleleri, ve ◦ (3) kullanıcıların sorgu cümlelerinde yer alan terimlerle derlemdeki belgelere verilen terimleri karşılaştırarak ilgili belgeleri belirlemek için kullanılan bir erişim kuralından oluşur.")
6
Tipik bir bilgi erişim sisteminde belgeler “terim”lerle gösterilir. Bir derlemden “terim” elde etmek için genelde şu aşamalar gerçekleştirilir: 1.Harf olmayan karakterler boşluklarla yer değiştirilir 2.Tek harfli sözcükler silinir 3.Bütün karakterler küçük harfli yapılır 4.“Durma listesi”nde (stop words/list) geçen sözcükler silinir 5.Sözcükler gövdelenir (stemming) 6.Tek karakterli gövdeler atılır Kaynak: Tonta, Bitirim & Sever (2002), s.16
 geçen sözcükler silinir 5.Sözcükler gövdelenir (stemming) 6.Tek karakterli gövdeler atılır Kaynak: Tonta, Bitirim & Sever (2002), s.16.")
7
Son adımdan sonra elde edilen listedeki yüksek sıklıklı sözcükler terim sözlüğünden çıkarılır ve böylece derleme duyarlı ikinci bir durma listesi oluşturulur. Bu isteğe bağlı gerçekleştirilen bir adımdır. Alternatif olarak yüksek sıklıklı sözcükler orta sıklıklı sözcüklerle birleştirilerek “tamlama” (phrase) oluştururlar. Tamlamalar, yüksek ve orta sıklıklı sözcükler ayrı ayrı terim sözlüğüne otomatik olarak eklenir. Tüm bu işlemler sırasında eşanlamlı sözcükler de terim listesi içinde tanımlanır. Kaynak: Tonta, Bitirim & Sever (2002), s.16
 oluştururlar. Tamlamalar, yüksek ve orta sıklıklı sözcükler ayrı ayrı terim sözlüğüne otomatik olarak eklenir. Tüm bu işlemler sırasında eşanlamlı sözcükler de terim listesi içinde tanımlanır. Kaynak: Tonta, Bitirim & Sever (2002), s.16.")
8
Kaynak: Hearst, M & Larson, R. (2001), Lecture-4_202
, Lecture-4_202")
9
Kaynak: Hearst, M & Larson, R. (2001),
,")
10
Hedef: benzer sözcükleri “normalize” etmek Morphology (sözcüklerin “biçim”i) ◦ Çekim ekleri (inflectional morphology) Çekim ekleri atılırken sözcüklerin dilbilgisel (grammatical) sınıfı asla bozulmaz dog, dogs ben, benim, bende, benden,.. ◦ Yapım ekleri (derivational morphology) Bir sözcükten başka bir sözcük türetme Genelde dilbilgisel sınıfı değişir build, building; health, healthy; kütüphane, kütüphaneci, kütüphanecilik Morfolojik analiz ve gövdelemeyi otomatik olarak gerçekleştiren sağlam yazılımlar var. Özellikle Türkçe gibi sondan eklemeli dillerde gövdeleme önemli ve otomatik gövdeleme yazılımlarının geliştirilmesine ihtiyaç var. Kaynak: Hearst, M & Larson, R. (2001), Lecture-4_202
 Bir sözcükten başka bir sözcük türetme Genelde dilbilgisel sınıfı değişir build, building; health, healthy; kütüphane, kütüphaneci, kütüphanecilik Morfolojik analiz ve gövdelemeyi otomatik olarak gerçekleştiren sağlam yazılımlar var. Özellikle Türkçe gibi sondan eklemeli dillerde gövdeleme önemli ve otomatik gövdeleme yazılımlarının geliştirilmesine ihtiyaç var. Kaynak: Hearst, M & Larson, R. (2001), Lecture-4_202.")
12
Bütün bu aşamalardan geçip otomatik olarak oluşturulmuş sözcüklere “terim” denir. Terimler hem belgeleri göstermede (belge terimleri) hem de sorguları ifade etmede (sorgu terimleri) kullanılır.
 hem de sorguları ifade etmede (sorgu terimleri) kullanılır..")
14
Tüm ilgili belgelere ulaşmak için sorgu cümlesinin sadece benzer kümelerle karşılaştırılması. Daha az işlem daha hızlı sonuç.. Küme sayısı – kümeleme formülü Kümeleme nesneleri: ◦ Konu başlıkları, ◦ Kitap adları, ◦ Tam metin ◦ … vb.

15
Bir bilgi erişim sisteminde temel nokta: ◦ Kullanıcının girdiği sorgulama terimlerinin, erişim için sistem tarafından yorumlanması. Sorgu cümlelerindeki terimlerle belgelerin dizin kayıtlarındaki terimler karşılaştırılır. Arama sonucunun kalitesi büyük ölçüde çakışma işleminde kullanılan erişim kurallarına bağlıdır. Hangi kayıtlara erişilip/erişilmeyeceğini erişim kuralı belirler.

16
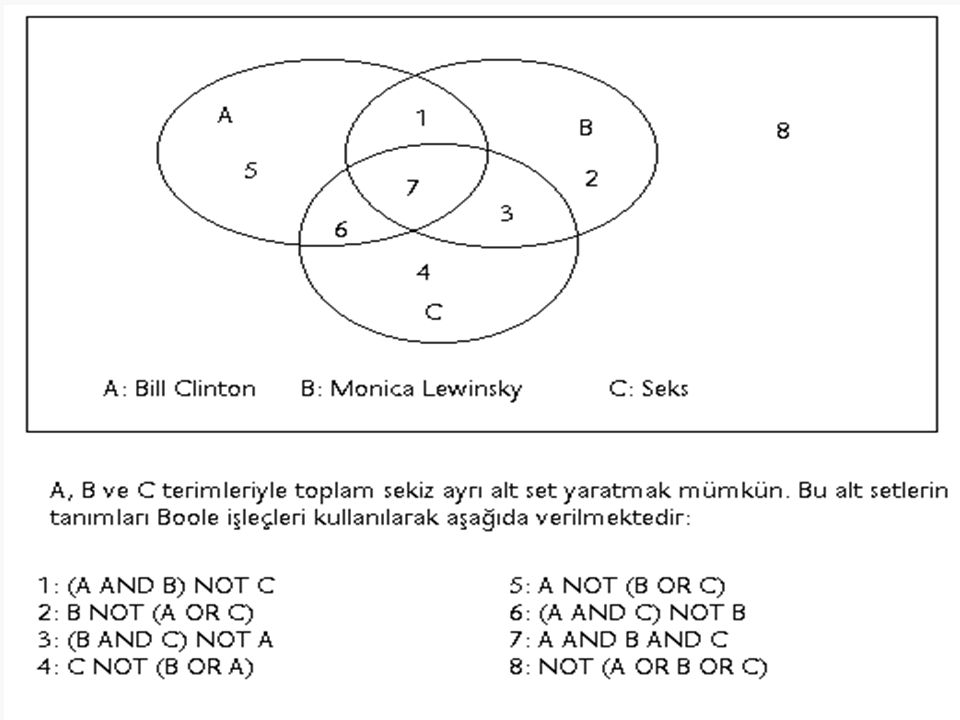
Sorgu cümlesindeki terimlerle dizin terimleri arasında kesin çakışma (exact match) gerektiren erişim kuralları ve boole erişim kuralları Olasılık kuramına dayalı erişim kuralları Vektör uzayı modeli (Boole, 1990).
 gerektiren erişim kuralları ve boole erişim kuralları Olasılık kuramına dayalı erişim kuralları Vektör uzayı modeli (Boole, 1990).")
17
Sorgu cümlesindeki terimler ve dizin terimleri ikilidir. Bir terim sorgu cümlesinde ya da belgenin dizin kaydında ya vardır ya yoktur. Erişim için her terim eşit derecede önem taşır. Birden çok terimden oluşan sorgu cümleleri için eşik değerleri oluşturulabilir. Sorgu cümlesindeki terimler kavramsal dizinlerden alınan ilgili terimlerle genişletilebilir. Erişilen kayıtlar kabaca erişildi erişilmedi şeklinde sıralanabilir. Ya da erişilen kayıtlar sorgu cümlesinde ve dizin kaydında mevcut çakışan terim sayısına göre sıralanabilir.

18
Boole modelinde erişim fonksiyonu ikili mantıkla çalıştığı için erişim çıktısındaki belgelerde sıralama yoktur (Salton, 1989). Erişim çıktısının en başında yer alan belgeyle en sonunda yer alan belge aynı erişim değerine sahiptir. (Fakat ufak bir trük ile Boole mantığı ile de sıralama yapmak mümkündür.) Çok fazla da sonuç gelebilir çok az da.
 Çok fazla da sonuç gelebilir çok az da..")
19
AND is the default connector. When you enter 2 or more search terms, AND is automatically inserted between any spaces or hyphens in the terms. ◦ heart attack or heart-attack would both be searched as heart AND attack Use AND when you want all of the terms in your search to appear in returned documents and when terms may be far apart from each other.

20
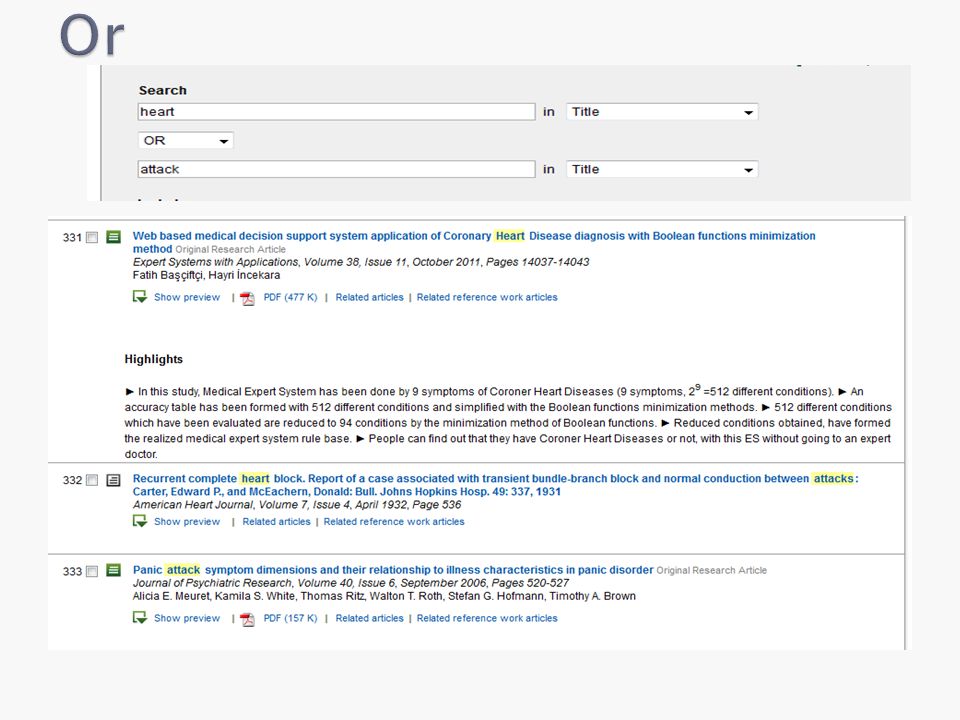
Use OR when at least one of your search terms must appear in returned documents. You can use OR to search for synonyms, alternate spellings, or abbreviations. ◦ heart OR attack

21
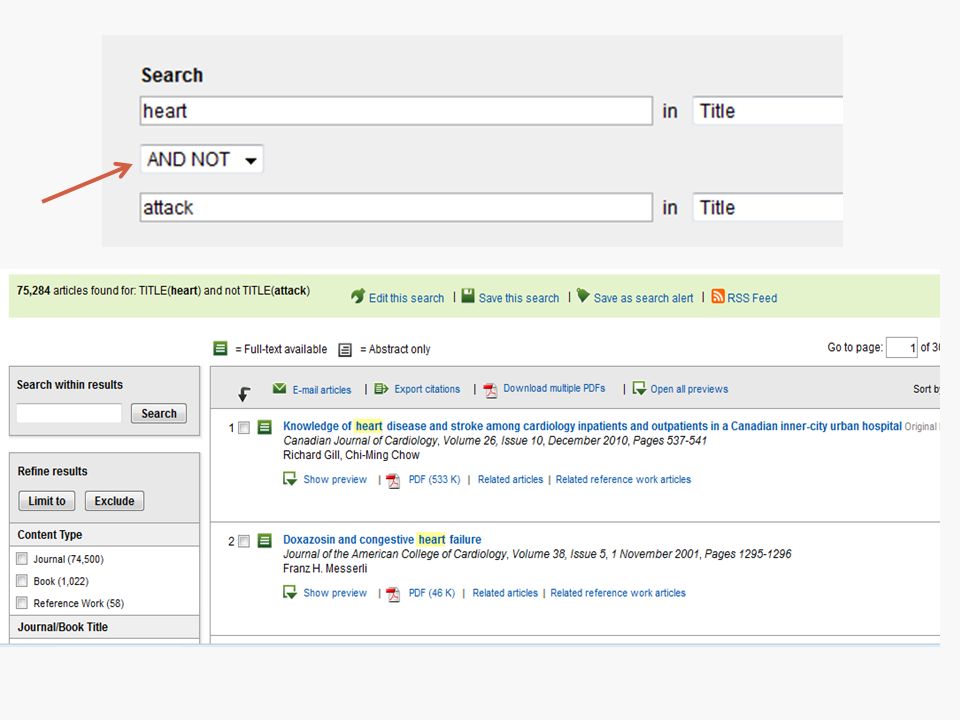
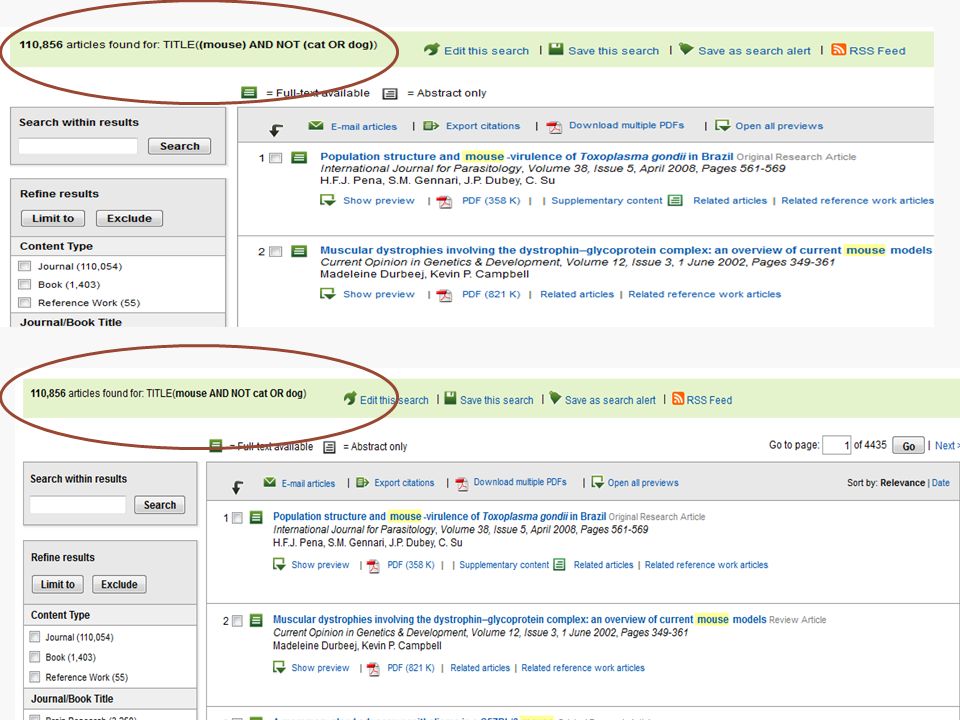
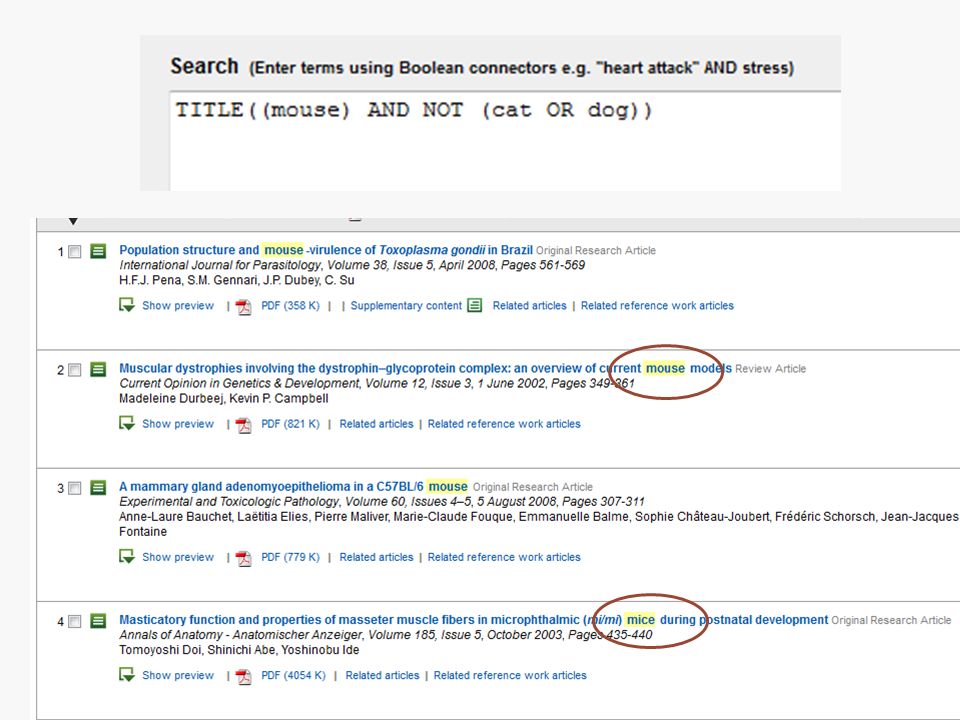
Use AND NOT to exclude specific terms from returned documents. Do not use AND NOT at the beginning of a search. ◦ ganglia OR tumor AND NOT malignant finds documents that contained the terms "ganglia" or "tumor", but not the term "malignant".

22
1- OR 2- AND 3- AND NOT KEY(mouse AND NOT cat OR dog) -- KEY((mouse) AND NOT (cat OR dog)) KEY(cat AND dog AND NOT rodent OR mouse) – KEY((cat AND dog) AND NOT (rodent OR mouse)) KEY(mouse OR rat AND rodent) KEY(rodent AND rat OR mouse) KEY(rat OR mouse AND rodent) = KEY((mouse OR rat) AND rodent)
 -- KEY((mouse) AND NOT (cat OR dog)) KEY(cat AND dog AND NOT rodent OR mouse) – KEY((cat AND dog) AND NOT (rodent OR mouse)) KEY(mouse OR rat AND rodent) KEY(rodent AND rat OR mouse) KEY(rat OR mouse AND rodent) = KEY((mouse OR rat) AND rodent)")
23
AND NOT can give unexpected results when you have multiple operators. Put it at the end of your searches. For example, the following search returns a large number of results: ◦ KEY(cold) AND NOT KEY(influenza) AND KEY(virus) To exclude influenza from your search and make it more targeted, use the following instead: ◦ KEY(cold) AND KEY(virus) AND NOT KEY(influenza)
 AND NOT KEY(influenza) AND KEY(virus) To exclude influenza from your search and make it more targeted, use the following instead: ◦ KEY(cold) AND KEY(virus) AND NOT KEY(influenza).")
24
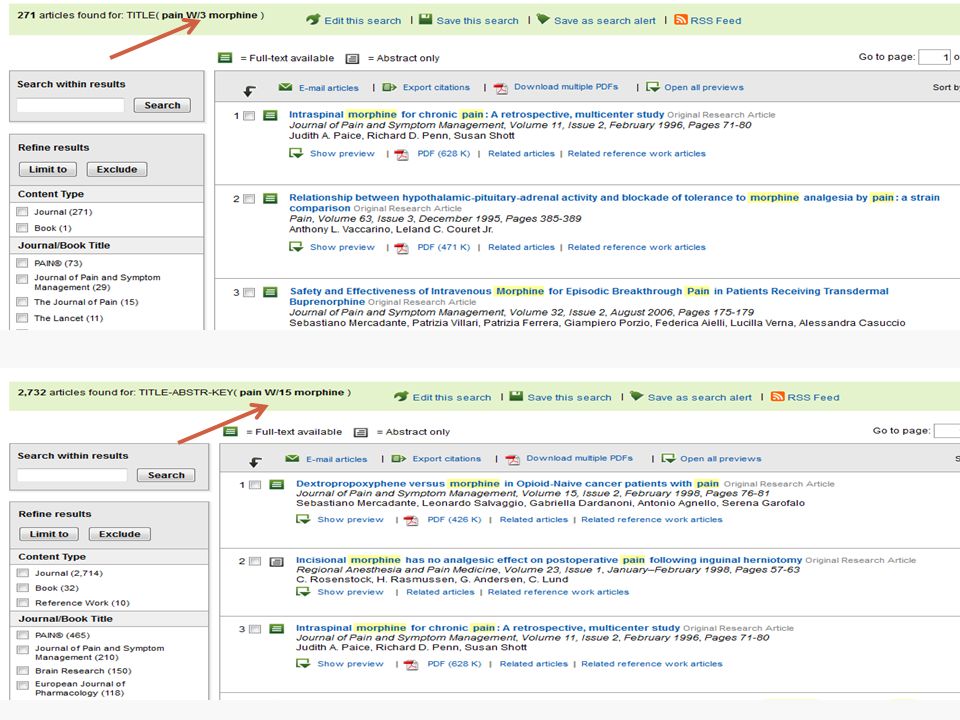
Use W/n to specify how far apart terms may appear in documents. W/n does not specify the word order. Either word may appear first. ◦ Example pain W/15 morphine would find documents that had the terms "pain" and "morphine" within 15 words of each other. To find terms in the same phrase, use W/3, W/4, or W/5 To find terms in the same sentence, use W/15 To find terms in the same paragraph, use W/50

25
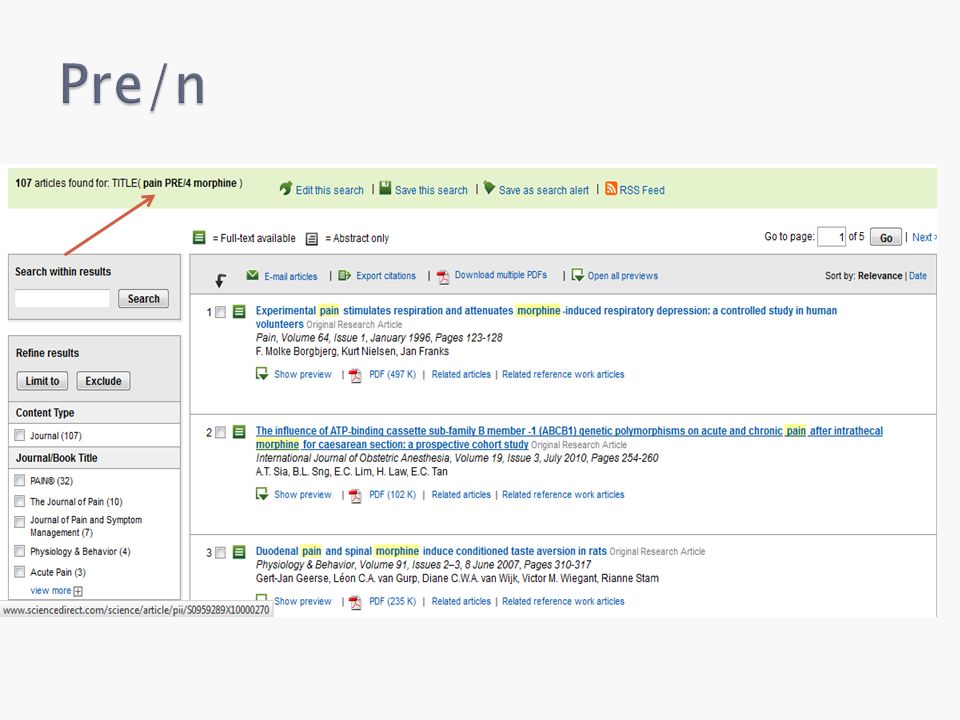
Use PRE/n to find documents in which the first term precedes the second term within a specified number (n) of words. ◦ pain PRE/3 morphine would find documents in which pain precedes morphine by three or fewer words.

26
9/6/2001 Information Organization and Retrieval Cat Cat OR Dog Cat AND Dog (Cat AND Dog) (Cat AND Dog) OR Collar (Cat AND Dog) OR (Collar AND Leash) (Cat OR Dog) AND (Collar OR Leash)
 (Cat AND Dog) OR Collar (Cat AND Dog) OR (Collar AND Leash) (Cat OR Dog) AND (Collar OR Leash)")
27
9/6/2001 Information Organization and Retrieval (Cat OR Dog) AND (Collar OR Leash)
 AND (Collar OR Leash)")
28
9/6/2001 Information Organization and Retrieval (Cat OR Dog) AND (Collar OR Leash)
 AND (Collar OR Leash)")
29
9/6/2001 Information Organization and Retrieval 3t33t3 1t11t1 2t22t2 1D11D1 2D22D2 3D33D3 4D44D4 5D55D5 6D66D6 8D88D8 7D77D7 9D99D9 10D1010D10 11D1111D11 m1m1 m2m2 m3m3 m5m5 m4m4 m7m7 m8m8 m6m6 m 2 = t 1 t 2 t 3 m 1 = t 1 t 2 t 3 m 4 = t 1 t 2 t 3 m 3 = t 1 t 2 t 3 m 6 = t 1 t 2 t 3 m 5 = t 1 t 2 t 3 m 8 = t 1 t 2 t 3 m 7 = t 1 t 2 t 3

30
9/6/2001 Information Organization and Retrieval “Measurement of the width of cracks in prestressed concrete beams” Formal Query: cracks AND beams AND Width_measurement AND Prestressed_concrete Cracks Beams Width measurement Prestressed concrete Relaxed Query: (C AND B AND P) OR (C AND B AND W) OR (C AND W AND P) OR (B AND W AND P)
 OR (C AND B AND W) OR (C AND W AND P) OR (B AND W AND P)")
31
Information need Index Pre-process Parse Collections Rank Query text input

32
Information need Index Pre-process Parse Collections Rank Query text input Reformulated Query Re-Rank

39
1- OR 2- AND 3- AND NOT KEY(mouse AND NOT cat OR dog) -- KEY((mouse) AND NOT (cat OR dog)) KEY(cat AND dog AND NOT rodent OR mouse) – KEY((cat AND dog) AND NOT (rodent OR mouse)) KEY(mouse OR rat AND rodent) KEY(rodent AND rat OR mouse) KEY(rat OR mouse AND rodent) = KEY((mouse OR rat) AND rodent)
 -- KEY((mouse) AND NOT (cat OR dog)) KEY(cat AND dog AND NOT rodent OR mouse) – KEY((cat AND dog) AND NOT (rodent OR mouse)) KEY(mouse OR rat AND rodent) KEY(rodent AND rat OR mouse) KEY(rat OR mouse AND rodent) = KEY((mouse OR rat) AND rodent)")
41
AND NOT can give unexpected results when you have multiple operators. Put it at the end of your searches. For example, the following search returns a large number of results: ◦ KEY(cold) AND NOT KEY(influenza) AND KEY(virus) To exclude influenza from your search and make it more targeted, use the following instead: ◦ KEY(cold) AND KEY(virus) AND NOT KEY(influenza)
 AND NOT KEY(influenza) AND KEY(virus) To exclude influenza from your search and make it more targeted, use the following instead: ◦ KEY(cold) AND KEY(virus) AND NOT KEY(influenza).")
43
Use W/n to specify how far apart terms may appear in documents. W/n does not specify the word order. Either word may appear first. ◦ Example pain W/15 morphine would find documents that had the terms "pain" and "morphine" within 15 words of each other. To find terms in the same phrase, use W/3, W/4, or W/5 To find terms in the same sentence, use W/15 To find terms in the same paragraph, use W/50

45
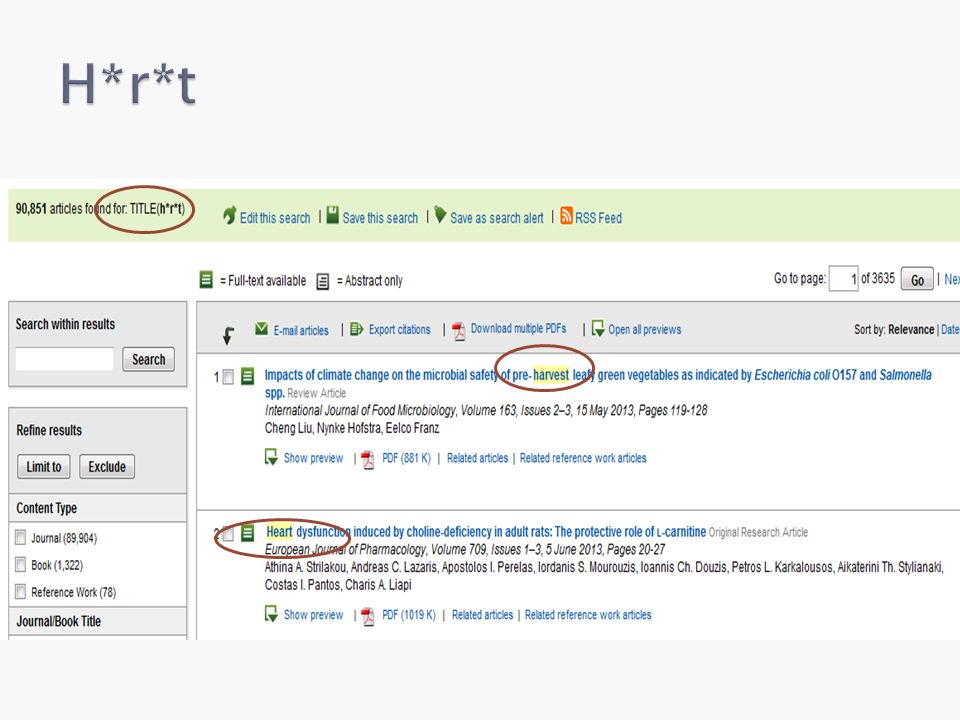
Asterisk (*) : Replace zero or more characters in a search word. ◦ h*r*t finds "heart", "harvest", "homograft", "hypervalent“ …. Question mark (?): Replace exactly one character in a search word. Use one question mark for each character. gro?t finds "grout" or "groat", but not "groundnut" or "grommet“ transplant?? finds "transplanted" and "transplanter
: Replace exactly one character in a search word. Use one question mark for each character. gro t finds grout or groat , but not groundnut or grommet transplant . finds transplanted and transplanter.")
48
Use a question mark to hold a space for certain variations in spelling at any point in a word. ◦ bernst??n finds both the "ei" and the "ie" spelling of the name. It is better to use the asterisk to account for spelling variations. ◦ behavi?r does not return results that include "behaviour"; however, searching for behavi*r returns results that include both "behavior" and "behaviour".

50
Use PRE/n to find documents in which the first term precedes the second term within a specified number (n) of words. ◦ pain PRE/3 morphine would find documents in which pain precedes morphine by three or fewer words.

52
Tonta, Y. (1995). Bilgi erişim sistemleri. (http://yunus.hacettepe.edu.tr/~soydal/bby156_2013/3/Bilgi ErisimSistemleri_tonta1995.pdf)http://yunus.hacettepe.edu.tr/~soydal/bby156_2013/3/Bilgi ErisimSistemleri_tonta1995.pdf Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s.17-35. (Tam metin)Tam metin Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval, s.1-18. (Tam metin)Tam metin Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval, s.3- 10 & 19-34. (Tam metin)Tam metin
 ErisimSistemleri_tonta1995.pdf Tonta, Y., Bitirim, Y. ve Sever, H. (2002). Türkçe Arama Motorlarında Performans Değerlendirme, s (Tam metin)Tam metin Manning, C.D., Raghavan, P. and Schütze, H. (2009). Introduction to Information Retrieval, s (Tam metin)Tam metin Baeza-Yates, R. and Ribeiro-Neto, B. (1999). Modern Information Retrieval, s & (Tam metin)Tam metin.")
















 problemleri (Matching and Assignment problems)>")

 2 friends... you'll have 3 years of good luck!!!>")
>")






