Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
Wisconsin Kart Sıralama Testi WCST
Gülay Büyükaksoy Kaplan’ın doktora tezi (2003) Wisconsin Kart Sıralama Testi WCST • soyutlama, • hipotez sınama, • zihinsel esneklik. Referans kartlar
 Wisconsin Kart Sıralama Testi WCST. • soyutlama, • hipotez sınama, • zihinsel esneklik. Referans kartlar.")
2
WCST-Testin Değerlendirilmesi
• Doğru yanıtlar • Tamamlanan kategoriler • Perseveratif (ısrarcı) yanıtlar • Kurulumu sürdürmede başarısızlık (FMS)
 yanıtlar. • Kurulumu sürdürmede başarısızlık (FMS)")
3
WCST- önerilen model • Kuralın belirlenmesi • Kart Seçimi
Sınıflama kuralını belirlemek Uygulayıcının yanıtı “doğru” ise kuralı tutmak, “yanlış” ise kuralı değiştirmek • Kart Seçimi Sınıflama kuralına uygun referans kartı belirlemek

4
Referans Kartlar Kart belirleme Çalışma belleği
Bir önceki kuralı tutmak veya yeni kuralı belirlemek için uygulayıcının yanıtını tutmak Rule Specifier Hipotez üreteci Uygulayıcının yanıtı”yanlış” ise alternatif kural üretme ve çalışma belleğine sunma Hypothesis Generator

5
Kırmızı:[1000] Üçgen:[1000] 1:[1000]
Kartların kodlanması Renk Şekil Sayı Kırmızı:[1000] Üçgen:[1000] 1:[1000] Sarı :[0100] Yıldız :[0100] 2:[0100] Mavi :[0010] Artı :[0010] 3:[0010] Yeşil :[0001] Daire :[0001] 4:[0001] renk şekil sayı
![Kırmızı:[1000] Üçgen:[1000] 1:[1000]](http://slideplayer.biz.tr/slide/10929652/39/images/5/K%C4%B1rm%C4%B1z%C4%B1%3A%5B1000%5D+%C3%9C%C3%A7gen%3A%5B1000%5D+1%3A%5B1000%5D.jpg "Kartların kodlanması. Renk Şekil Sayı. Kırmızı:[1000] Üçgen:[1000] 1:[1000] Sarı :[0100] Yıldız :[0100] 2:[0100] Mavi :[0010] Artı :[0010] 3:[0010] Yeşil :[0001] Daire :[0001] 4:[0001] renk. şekil. sayı.")
6
Benzetim Sonuçları Koşul Ham. uzak Hop. eşik #Doğru cevap #Kategori
% Pers. hata FMS Yorum 1 3 T 64.6 3.5 6.0 0 9.9 2.8 0 0 Esnek 4 3-2 64 1.8 6.0 0 9.5 2.1 7 2 67.6 3.7 14.2 4.6 Az Esnek 10 2-1 70.7 5.5 17.9 3.7 T1 73.7 6.1 1.1 0.5 19.7 2.9 3.2 1.6 Zihni dağınık 5 75.9 6.1 1.6 1.0 17.7 3.4 2.7 1.3 8 66.3 9.1 0.4 0.5 24.6 4.9 2.6 2.1 Katı/Dağ. 11 73.2 6.3 1.3 0.5 21.2 5.0 2.4 1.2 T2 66.2 8.4 0.3 0.5 26.5 6.4 2.4 1.8 6 72.6 7.9 0.8 0.8 25.9 6.2 3.1 1.7 9 66.7 9.9 0.5 0.7 27.9 8.6 2.0 1.5 12 59.8 6.3 0.1 0.3 29.1 6.9 2.0 0.9 14 58.8 6.9 1.1 0.4 32.4 6.2 1.1 0.6 Katı 17 31.5 4.7 0 0 38.6 4.8 0 0 15 61.9 8.3 0 0 27.7 6.8 18 30.4 4.1 39.4 3.5 13 39.4 0.5 1.0 0 67.8 0.5 Çok Katı 16 32.8 2.5 73.0 1.5 Katı/Dağ.

7
MAVİ YEŞİL KIRMIZI SARI YEŞİL MAVİ SARI KIRMIZI
Stroop Testi MAVİ YEŞİL KIRMIZI SARI YEŞİL MAVİ SARI KIRMIZI SARI KIRMIZI YEŞİL MAVİ KIRMIZI YEŞİL MAVİ SARI MAVİ SARI KIRMIZI YEŞİL YEŞİL MAVİ SARI KIRMIZI

8
Stroop Test Seçici Dikkat
özgün ödev için otomatik olan davranışı bastırmak • Ölçütler testin süresi hata sayısı, düzeltme sayısı

9
Stroop test-the proposed model
Duyusal ve motor devreler: Hopfield ağları Basal Çekirdekler: Maxnet , OF tarafından modüle edilen otomatik işlem Seçici dikkat: Kazanan hepsini alır Özgün bilgi geldiğinde OF’yi uyarmak için Hata Sezici : Perceptron yapıları ödev ile yanıtın uyuşmadığı durumlarda OF’yi uyaracak hata işaretini üretmek için

10
Benzetim Sonuçları Baz Ol. Süre (sec) # Hata # Düz. Yorum 0.4 0.1
28.4 ± 3.2 0.4 ± 0.6 0.08 ± 0.3 0.9 28.9 ± 2.4 0.3 ± 0.5 0.3 31.7 ± 1.8 2 ± 0.7 33.6 ± 4 2.8 ± 1.5 0.9 ± 0.9 0.2 36.6 ± 2.2 5.6 ± 1.9 39.7 ± 2 5 ± 1.3 1.75 ± 1.2 39.5 ± 2.5 9.6 ± 2.3 47 ± 2.8 9.2 ± 2.7 3.3 ± 1.7 0.05 40.4 ± 2.8 11.3 ± 2.2 0.3 ± 0.7 48.3 ± 2.5 11.4 ± 1.8 3 ± 1.5 bastırma süre

11
Nikotin Bağımlılığı için Bir Hesaplamalı Model
Selin Metin’in doktora çalışması (2010) Nikotin Bağımlılığı için Bir Hesaplamalı Model Eylem seçici devre Eylem Değerlendirme Değer Atama UDA ri Wr Pekiştirmeli Öğrenme Burada da denklemleri kaldir nasilsa bir sonrakinde var ama reinforcement learning ile action selection daki parametreyi degistirdigini bu parametrenin aslinda ventral tegmental area’dan dopaminin etkisini modelledigini action evaluatin da nelerin oldugunu anlat. Sadece diyagram olsun bir onceki neural substrateler ile iliskisini koyarak sema ile modelin genel hatlarini acikla
 Nikotin Bağımlılığı için Bir Hesaplamalı Model. Eylem seçici devre. Eylem Değerlendirme. Değer Atama. UDA. ri. Wr. Pekiştirmeli Öğrenme. Burada da denklemleri kaldir nasilsa bir sonrakinde var ama reinforcement learning ile action selection daki parametreyi degistirdigini bu parametrenin aslinda ventral tegmental area’dan dopaminin etkisini modelledigini action evaluatin da nelerin oldugunu anlat. Sadece diyagram olsun bir onceki neural substrateler ile iliskisini koyarak sema ile modelin genel hatlarini acikla.")
12
PEKİŞTİRMELİ ÖĞRENME Keşfetme ↔ Kullanma Strateji Aktör Ödül Değer
Ortam modeli Aktör Ortam Eylem ai Ödül ri Durum si ŞEKİL BİRAZ BUYUTULSE COK KUCUK KALMIŞ BURADA ANLATIRKEN KAVRAMSAL OLARAK NE YAPILDIĞI İLE NASIL GERÇEKLENDİĞİ AYRILSA İYİ OLACAK. YAZDIKLARINDAN ÇOK İÇİÇE GEÇMİŞ ANLAŞILMAZ OLMUŞ HİSSİNE KAPILDIM.ONCELİKLE KAVRAMSAL OLARAK NE AMAÇLANIYOR ONU BELİRTİP, PSİKOLOJİDE DE ( HANİ BİR PSİKOLOJİ KİTABİ VERMİSTİM YA ONDAKİ İNSTRUMENTAL CONDİTİONİNG OLAN KISIM REINFORCEMENT LEARNING’E KARŞI DÜŞER) HANGİ ÖĞRENME KURALI İLE İLİŞKİL OLDUĞUNDAN BAHSEDİP SONRA DA KİTABIN YAZARLARININ İLK MAKALESİ (ONU DA VERMİŞTİM HIZLICA DA OLSA BİR OKUSAN İYİ OLUR) İLE NASIL İLERLİYEN YILLARDA BİR MAKİNA ÖĞRENME YAKLAŞIMI OLUŞTURDUKLARINDAN BAHSEDİP GERÇEKLEME İÇİN NELER YAPILIYOR OZETLESEN İYİ OLUR. BOYLECE KAVRAMLAR İLE BU KAVRAMLARIN NASIL GERÇEKLENDİĞİNE DAİR FİKİR OLUŞUR. Pekiştirmeli öğrenme, durumları, yani seçenekleri, eylemler ile birleştiren bağıntıları keşfetme sürecidir. Amaç sayısal bir ödül işaretini en yüksek nihai değere ulaştırmaktır. Pekiştirmeli öğrenmenin iki önemli unsuru, keşfetmek ve kullanmaktır. Öğrenici, halihazırda sahip olduğu bilgiyi kullanarak ödül elde eder, fakat aynı zamanda gelecekte daha iyi eylemleri seçebilmek için keşifler de yapması gerekir. Keşifler, deneme-yanılma yöntemi ile arayarak yapılır ve dolayısıyla ödüller karar anında değil, daha geç elde edilir. Hatta ödüller anlık değil, daha sonraki adımları da değiştirecek biçimde uzun vadeli olabilir (örneğin bulunulan adım için en yüksek değerde olmayan ödül birkaç adımlık ilerleme sonunda birikerek en yüksek değeri alabilir). Strateji, öğrenicinin verilen bir zamandaki davranışını belirleyen, durumlardan eylemlere doğru bir eşleştirmedir. Pekiştirmeli öğrenmenin en önemli unsurudur çünkü tek başına davranışları belirlemeye yeterlidir. Ödül fonksiyonu, amacı belirler ve her durum-eylem çiftini o durumun istenirliğini gösteren bir sayı ile eşleştirir. Değer fonksiyonu, uzun vadede neyin iyi olduğunu belirler ve bir durumdan başlayarak gelecekte elde edilebilecek toplam ödülü gösterir. Ödüller, bir durumun anlık istenirliğini gösterirken değerler, birbirini takip eden durumların getireceği ödüllerin toplamını gösterir. Dolayısıyla o an için en fazla olmayan ödülü veren durum seçilebilir ancak takip eden durumlar göz önüne alındığında en fazla toplam ödül elde edilebilir. Ortam modeli planlama yapmak için kullanılır ve ortamın davranışını taklit eder. Ortam modeli ve planlama, pekiştirmeli öğrenme kuramına sonradan katılmış kavramlardır. Ortam modeli her zaman bulunmayabilir. Bizim için ödül sigara içince alınan zevk ve rahatlama duygusudur. Ortam ise sigara içilmesini tetikleyen dış/iç kaynaklı uyaranlardır. Durumlar sigara içilmiş durumlara denk gelir. Aktör, sigara içme eylemini gerçekleştirerek elde ettiği ödüle göre tekrar sigara içip içmemeye karar verir. Dayan, P.: Dopamine, Reinforcement Learning, and Addiction, Pharmacopsychiatry 42 (2009) S56-S65
 HANGİ ÖĞRENME KURALI İLE İLİŞKİL OLDUĞUNDAN BAHSEDİP SONRA DA KİTABIN YAZARLARININ İLK MAKALESİ (ONU DA VERMİŞTİM HIZLICA DA OLSA BİR OKUSAN İYİ OLUR) İLE NASIL İLERLİYEN YILLARDA BİR MAKİNA ÖĞRENME YAKLAŞIMI OLUŞTURDUKLARINDAN BAHSEDİP GERÇEKLEME İÇİN NELER YAPILIYOR OZETLESEN İYİ OLUR. BOYLECE KAVRAMLAR İLE BU KAVRAMLARIN NASIL GERÇEKLENDİĞİNE DAİR FİKİR OLUŞUR. Pekiştirmeli öğrenme, durumları, yani seçenekleri, eylemler ile birleştiren bağıntıları keşfetme sürecidir. Amaç sayısal bir ödül işaretini en yüksek nihai değere ulaştırmaktır. Pekiştirmeli öğrenmenin iki önemli unsuru, keşfetmek ve kullanmaktır. Öğrenici, halihazırda sahip olduğu bilgiyi kullanarak ödül elde eder, fakat aynı zamanda gelecekte daha iyi eylemleri seçebilmek için keşifler de yapması gerekir. Keşifler, deneme-yanılma yöntemi ile arayarak yapılır ve dolayısıyla ödüller karar anında değil, daha geç elde edilir. Hatta ödüller anlık değil, daha sonraki adımları da değiştirecek biçimde uzun vadeli olabilir (örneğin bulunulan adım için en yüksek değerde olmayan ödül birkaç adımlık ilerleme sonunda birikerek en yüksek değeri alabilir). Strateji, öğrenicinin verilen bir zamandaki davranışını belirleyen, durumlardan eylemlere doğru bir eşleştirmedir. Pekiştirmeli öğrenmenin en önemli unsurudur çünkü tek başına davranışları belirlemeye yeterlidir. Ödül fonksiyonu, amacı belirler ve her durum-eylem çiftini o durumun istenirliğini gösteren bir sayı ile eşleştirir. Değer fonksiyonu, uzun vadede neyin iyi olduğunu belirler ve bir durumdan başlayarak gelecekte elde edilebilecek toplam ödülü gösterir. Ödüller, bir durumun anlık istenirliğini gösterirken değerler, birbirini takip eden durumların getireceği ödüllerin toplamını gösterir. Dolayısıyla o an için en fazla olmayan ödülü veren durum seçilebilir ancak takip eden durumlar göz önüne alındığında en fazla toplam ödül elde edilebilir. Ortam modeli planlama yapmak için kullanılır ve ortamın davranışını taklit eder. Ortam modeli ve planlama, pekiştirmeli öğrenme kuramına sonradan katılmış kavramlardır. Ortam modeli her zaman bulunmayabilir. Bizim için ödül sigara içince alınan zevk ve rahatlama duygusudur. Ortam ise sigara içilmesini tetikleyen dış/iç kaynaklı uyaranlardır. Durumlar sigara içilmiş durumlara denk gelir. Aktör, sigara içme eylemini gerçekleştirerek elde ettiği ödüle göre tekrar sigara içip içmemeye karar verir. Dayan, P.: Dopamine, Reinforcement Learning, and Addiction, Pharmacopsychiatry 42 (2009) S56-S65.")
13
ri Eylem Seçici Devre Değer Atama Eylem Değerlendirme
Burada action selectionda wr’nin etkisine neden onem verdigimizi aciklayip bunu ayrica dallanma diyagrami ile acikladigimizi belirtip bir sonraki sayfaya bagla ppm/m, mpm/m, rpm/m, npm/m, dpm/m değişkenleri, sırasıyla beyindeki korteks, talamus, striatum, subtalamik nukleus, ve globus pallidus interna/substantia pars reticulata alt yapılarına karşılık gelen vektörleri göstermektedir. We emphasize ppm/m component because it shows the cortex premotor loop. Since premotor loop drives motor loop and cortex is the output to the motor organs (skeleton, muscles), ppm/m component displays the output of the overall system. Wrpm kösegen matrisi ile ventral striatumun (özellikle nuklues accumbensin) dorsal striatum (kaudat ve putamen) üzerindeki etkisi göstermektedir emotions over decisions. Wcpm matrisi ile duyusal uyaranlar gösterilmistir. delta and V are elements of reinforcement learning Wrpm has the most effect on A-S therefore we will examine the changes in our actions by using Wrpm. ri Değer Atama Eylem Değerlendirme
, ppm/m component displays the output of the overall system. Wrpm kösegen matrisi ile ventral striatumun (özellikle nuklues accumbensin) dorsal striatum (kaudat ve putamen) üzerindeki etkisi göstermektedir emotions over decisions. Wcpm matrisi ile duyusal uyaranlar gösterilmistir. delta and V are elements of reinforcement learning. Wrpm has the most effect on A-S therefore we will examine the changes in our actions by using Wrpm. ri. Değer Atama. Eylem Değerlendirme.")
14
BEYİNDEKİ DOPAMİN ALT SİSTEMİNİN ELEMANLARI
Yine buraya dallanma diyagramı dallanma diyagramında gözlenen kararlı denge noktalarına ilişkin dinamik davranış (zamanla değişim) Eğrileri ne tur dallanma olduğnu da konuşarak anlatacaksın. Yazı yok, sadece dallanmaların adını yaz
 Eğrileri ne tur dallanma olduğnu da konuşarak anlatacaksın. Yazı yok, sadece dallanmaların adını yaz.")
15
EYLEM DEĞERLENDİRME ALTSİSTEMİ
Aktivasyon fonksiyonları: Dinamik Sistem:

16
SİSTEMİN DALLANMA DİYAGRAMLARI
Eylem seçici devrede ppm değişkeninin Wr parametresine göre dallanması Değişkenlerin neler olduğunu ve her bir parametrenin ne için konulduğunu anlat sakın yazma ppm/m, mpm/m, rpm/m, npm/m, dpm/m değişkenleri, sırasıyla beyindeki korteks, talamus, striatum, subtalamik nukleus, ve globus pallidus interna/substantia pars reticulata alt yapılarına karşılık gelen vektörleri göstermektedir. Wrpm kösegen matrisi ile ventral striatumun (özellikle nuklues accumbensin) dorsal striatum (kaudat ve putamen) üzerindeki etkisi göstermektedir. Wcpm matrisi ile duyusal uyaranlar gösterilmistir. The action is selected by looking at the output of the p component. Since premotor loop directly drives motor loop, examining premotor output is sufficient to see the A-S output. Bifurcations are modifications of equilibrium points, periodic orbits or their stability properties observed according to the change of a parameter. These bifurcation simulations are obtained using XPPAUT. Dallanma diyagramında sigara içme ve içmemeye karşılık gelen dalları göster. Bunlar RL için kullanma bölgeleri. Hopf dallanması olan noktalar ise keşfetme bölgesi, sistem hangisini yapacağına dair arayış içinde.
 dorsal striatum (kaudat ve putamen) üzerindeki etkisi göstermektedir. Wcpm matrisi ile duyusal uyaranlar gösterilmistir. The action is selected by looking at the output of the p component. Since premotor loop directly drives motor loop, examining premotor output is sufficient to see the A-S output. Bifurcations are modifications of equilibrium points, periodic orbits or their stability properties observed according to the change of a parameter. These bifurcation simulations are obtained using XPPAUT. Dallanma diyagramında sigara içme ve içmemeye karşılık gelen dalları göster. Bunlar RL için kullanma bölgeleri. Hopf dallanması olan noktalar ise keşfetme bölgesi, sistem hangisini yapacağına dair arayış içinde.")
17
SİSTEMİN DAVRANIŞI – BAĞIMLILIK GELİŞTİREN
δ hata işareti & sigara içme için seçimler We model the presence or absence of something as 1 or 0. Therefore steady-state graphs have magnitudes of 0.75 and 0.25. The bifurcation diagram of A-S circuit are drawn for ppm according to Wr parameter

18
SİSTEMİN DAVRANIŞI – BAĞIMLILIK GELİŞTİRMEYEN
δ hata işareti & sigara içme için seçimler

19
SİSTEM DAVRANIŞI- KARARSIZ
δ hata işareti & sigara içme için seçimler

20
Davranış Değerlendirme
20 / 50 bağımlı Bağımlılk geliştirme için ortalama süre = 346 / adım ve σ = Davranış Seçici Devre Davranış Değerlendirme Değer Atama UDA ri Simulations are done using MATLAB. Simulation starts with random initial values. An action is selected according to the environmental stimulus. A reward is assigned to this action and its value is calculated. The output is used as the dopaminergic function to drive the A-S circuit. The values of Wr and Wc are updated and the loop starts again. When the number of successive smoking actions reaches 20, simulation stops. We have seen no statistical meaning to wait for longer than 20 selections. The model completed the task on average 63 trials with a standard deviation of In 40 successive runs, the number of simulations in which addiction does not occur under 65 steps is 14 (35%). DOĞRU AKIŞ DİYAGRAMI OLDUĞUNU KONTROL ET!!!!!!
. DOĞRU AKIŞ DİYAGRAMI OLDUĞUNU KONTROL ET!!!!!!")
21
W PARAMETRELERİNİN DEĞERLERİ
Bağımlılığın geliştirildiği durum: Burada degerlere dikkat cek hatta kritik degerleri daire icine al. Wc shows the environmental effect. After the learning ends its values shift to [1 0] namely smoking action for our simulation. The weight matrices for an addict state are given on the left The weight matrices for a process resulting as not addict are given on the right İlk değerler:

22
W PARAMETRELERİNİN DEĞERLERİ
Bağımlılığın geliştirilmediği durum: Burada degerlere dikkat cek hatta kritik degerleri daire icine al. Wc shows the environmental effect. After the learning ends its values shift to [1 0] namely smoking action for our simulation. The weight matrices for an addict state are given on the left The weight matrices for a process resulting as not addict are given on the right İlk değerler:

23
Yinelemeli ağlar (Recurrent Networks)
Çıkışlarda geçmişe ait verilerin de katkısı var Dinamik yapılar Kaotik davranış da dahil çok farklı davranışları modellemek mümkün

24
Elman Ağı ile zamanda yapı tanıma: kelime tanıma
Elman ağı belirli bir kurala göre oluşturulmuş sembol dizisinin altında yatan kuralı öğrenebiliyor. Bu semboller dili oluşturan sesler olarak düşünülebilir. Harf dizisine ilişkin gösterim: 6 özellik ile elde ediliyor Sessiz Sesli Kesikli Yüksek Dönüşlü Akortlu b [1 1 1] d g a [0 i u Mahmut Meral Bitirme Ödevi, 2003

25
önce üç sessiz harften biri rasgele olarak seçilip sesli harfler aşağıdaki kurala göre araya eklenmiştir. b -> ba d -> dii g -> guuu Örneğin rasgele seçilen sessiz harf dizisi dbgbddg… ise oluşan harf dizisi: diibaguuubadiidiiguuu… şeklindedir U(n+1) U(n)
 U(n)")
27
Elman Ağı ile kelime dizisi tanıma
Elman ağı, ses sembollerinden (harflerden) oluşan kelimeler kullanılarak bir harf dizisinin içinden anlamlı harf dizilerini de (kelimeleri) ayırabilir Uygulamada on üç farklı harften oluşan altı farklı kelime kullanılmaktadır. Harfler beş bitlik vektörler olarak kodlanmıştır. Kelimelerin uzunluğu üç ile yedi harf arasında değişmektedir. Altı kelimeden rasgele 450 kelime uzunluklu bir dizi oluşturdu. Daha sonra kelime dizisi 2106 harf uzunluğunda bir harf dizisine çevrilerek beş bitlik vektörler şeklinde kodlandı
 oluşan kelimeler kullanılarak bir harf dizisinin içinden anlamlı harf dizilerini de (kelimeleri) ayırabilir. Uygulamada on üç farklı harften oluşan altı farklı kelime kullanılmaktadır. Harfler beş bitlik vektörler olarak kodlanmıştır. Kelimelerin uzunluğu üç ile yedi harf arasında değişmektedir. Altı kelimeden rasgele 450 kelime uzunluklu bir dizi oluşturdu. Daha sonra kelime dizisi 2106 harf uzunluğunda bir harf dizisine çevrilerek beş bitlik vektörler şeklinde kodlandı.")
28
Giriş Çıkış e 00101 l 01000 m 01100 a 00001 n 01101 ğ ı 00110 i 00111 00100 z 10010 d 00010 y 10001 p 01110 t 01111

30
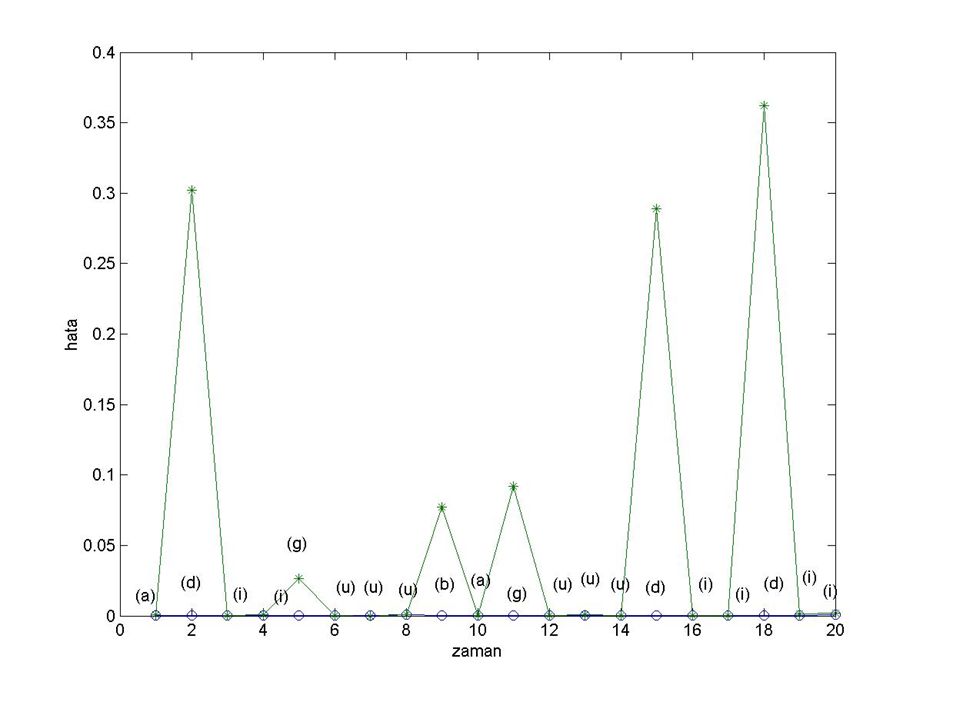
Kelimeler arası sınırlarda iki ve üzerinde hatalı bit oluşmaktadır
Kelimeler arası sınırlarda iki ve üzerinde hatalı bit oluşmaktadır. Bir nokta hariç ara noktalarda ise hatalı bit yoktur. . Sadece “zamanda” kelimesindeki “d” harfinin tahmininde bir hatalı bit oluşmaktadır. Bu durumun sebebi “elman” ve “zamanda” kelimelerinin her ikisinde de “man” dizisinin bulunmasıdır. ”zamanda” kelimesindeki “man” dizisinden sonra “d” gelmesi beklenirken, “elman” kelimesindeki “man” dizisinden sonra altı kelime içinden herhangi birinin ilk harfi (e,a,i,z,y,t) gelebilmektedir. Bu durum eğitimi olumsuz yönde etkileyerek hatanın yeterince azalmasını önlemektedir
 gelebilmektedir. Bu durum eğitimi olumsuz yönde etkileyerek hatanın yeterince azalmasını önlemektedir.")
Benzer bir sunumlar

>")

















.>")
