Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
BÖLÜM 5 Kimyasal Analizde Hatalar

2
Bölüm 5. Kimyasal Analizde Hatalar
Paris’te Montparnasse istasyonundaki bu meşhur tren kazası resminde de görüldüğü gibi, hatalar, kimi zaman felakete dönüşebilir. Granville’den (Fransa) 22 Ekim 1895’te gelen tren, frenleri tutmadığı için duramamış ve istasyon duvarına tırmanmış ve lokomotif 9 metre aşağıdaki caddeye düşmüştür. Bu bölümde açıklanacağı gibi, kimyasal analizlerde hataların, böylesine dramatik sonuçlara yol açması nadir de olsa mümkündür. Analitik sonuçların, hastalıkların teşhis ve tedavisi, tehlikeli atıkların kontrolü ve ağır suçların faillerinin bulunması gibi uygulama alanları vardır. Böyle durumlarda, analizlerin hatalı olması, kişileri ve toplumu derinden etkiler.
 22 Ekim 1895’te gelen tren, frenleri tutmadığı için duramamış ve istasyon duvarına tırmanmış ve lokomotif 9 metre aşağıdaki caddeye düşmüştür. Bu bölümde açıklanacağı gibi, kimyasal analizlerde hataların, böylesine dramatik sonuçlara yol açması nadir de olsa mümkündür. Analitik sonuçların, hastalıkların teşhis ve tedavisi, tehlikeli atıkların kontrolü ve ağır suçların faillerinin bulunması gibi uygulama alanları vardır. Böyle durumlarda, analizlerin hatalı olması, kişileri ve toplumu derinden etkiler.")
3
Ölçmelerde hatalar ve belirsizlikler kaçınılmazdır
Ölçmelerde hatalar ve belirsizlikler kaçınılmazdır. Hata terimi, farklı iki anlamda kullanılır: Birincisi ölçülen değer ile gerçek veya bilinen değer arasındaki farkı ifade eder. İkincisi ise, bir ölçmedeki tahminsel belirsizliği ifade eder. Hatalar, daha çok, yanlış kalibrasyondan, ya da sonuçlardaki rasgele değişimler ve belirsizliklerden kaynaklanır. Ölçmelerdeki belirsizlikler, aynı büyüklüğe ait ölçme sonuçlarının farklı çıkmasına yol açar. Tek bir analiz, sonuçların geçerliliği hakkında bilgi vermediğinden, bir analitik işlemin tamamı, genellikle aynı numuneden alınan iki veya daha fazla kısımda (tekrar numunesi ile) yapılır. Ortalama: Ortalama veya aritmetik ortalama , ölçümlerin toplamının, ölçüm sayısına bölünmesiyle bulunur: (xi, tekrarlanan N tane ölçümden oluşan bir takımdaki her bir x değerini gösterir.) Ortanca (medyan): Tekrarlanan veriler büyüklüklerine göre sıralandığında ortaya düşen değerdir.
 yapılır. Ortalama: Ortalama veya aritmetik ortalama , ölçümlerin toplamının, ölçüm sayısına bölünmesiyle bulunur: (xi, tekrarlanan N tane ölçümden oluşan bir takımdaki her bir x değerini gösterir.) Ortanca (medyan): Tekrarlanan veriler büyüklüklerine göre sıralandığında ortaya düşen değerdir.")
4
Şekil 5-1 20,00 ppm demir(III) içeren standart sulu
Örnek 1. Aşağıdaki şekilde gösterilen veriler için ortalama ve ortancayı hesaplayınız. Takımda çift sayıda (6) veri bulunduğu için, ortanca büyüklük bakımından 3. ve 4. sıradaki sayıların ortalaması olur: Ortanca = (19,6 + 19,8)/2 = 19,7 ppm Kesinlik: Kesinlik, ölçümlerin tekrarlanabilirliğini, yani tamamen aynı yolla elde edilen sonuçların birbirine yakınlığını gösterir. Bir takımın kesinliğini ifade etmek için xi değerinin ortalamadan ne kadar saptığı (di) (ortalamadan sapma) bulunur: Şekil ,00 ppm demir(III) içeren standart sulu bir çözeltide demir tayini için yapılan altı tekrar deneyinin sonucu. - hata + hata
 veri bulunduğu için, ortanca büyüklük bakımından 3. ve 4. sıradaki sayıların ortalaması olur: Ortanca = (19,6 + 19,8)/2 = 19,7 ppm. Kesinlik: Kesinlik, ölçümlerin tekrarlanabilirliğini, yani tamamen aynı yolla elde edilen sonuçların birbirine yakınlığını gösterir. Bir takımın kesinliğini ifade etmek için xi değerinin ortalamadan ne kadar saptığı (di) (ortalamadan sapma) bulunur: Şekil ,00 ppm demir(III) içeren standart sulu. bir çözeltide demir tayini için yapılan altı tekrar. deneyinin sonucu. - hata. + hata.")
5
Bir büyüklüğün gerçek değeri tam olarak
Doğruluk: Ölçümlerin gerçek veya kabul edilen değere olan yakınlığını ifade eder. Doğruluğun ölçüsü, hatanın büyüklüğüdür. Bir büyüklüğün gerçek değeri tam olarak bilinemediğinden, doğruluk tam olarak tayin edilemez. Görüldüğü gibi, bir ölçümün bağıl hatası mutlak hatanın gerçek değere oranıdır. Elde edilen değer yüzde, binde (ppt) ya da milyonda bir cinsinden ifade edilebilir. Örnek 1’deki verilerin ortalaması için bağıl hata: Er = (19,8-20,00)/20,00 x 100 = -%1 veya -10 ppt olur. Doğruluk ifadeleri Mutlak hata Bağıl hata
 ya da milyonda bir cinsinden ifade edilebilir. Örnek 1’deki verilerin ortalaması için bağıl hata: Er = (19,8-20,00)/20,00 x 100 = -%1 veya -10 ppt olur. Doğruluk ifadeleri. Mutlak hata. Bağıl hata.")
6
Ortalama mol kütlesini, b) Mol kütlesi için ortanca değeri,
Örnek 2. Aşağıda lityumun mol kütlesi tayini sonuçları listelenmiştir (xt: 6,941 g/mol). Ortalama mol kütlesini, b) Mol kütlesi için ortanca değeri, c) Lityumun mol kütlesi tayini esnasında yapılan mutlak ve bağıl hatayı bulunuz. Deney Mol kütlesi g/mol 1 6,9391 2 6,9407 3 6,9409 4 6,9399 5 6 7 6,9406 7 ölçüm içerisinden, 3 değerden küçük ve diğer 3 değerden de büyük olan 6,9406 sayısı ortancadır.
. Ortalama mol kütlesini, b) Mol kütlesi için ortanca değeri, c) Lityumun mol kütlesi tayini esnasında yapılan mutlak ve bağıl hatayı bulunuz. Deney. Mol kütlesi. g/mol. 1. 6, , , , , ölçüm içerisinden, 3 değerden küçük ve diğer 3 değerden de. büyük olan 6,9406 sayısı ortancadır.")
7
Deneysel verilerdeki hata tipleri:
Deneysel hatalar, rasgele (belirsiz) ve sistematik (belirli) hatalardan kaynaklanır. Genellikle bir ölçümde cevabı yüksek bir kesinlikle bildiğimizde, onun doğru değer olduğunu kabul ederiz. Oysa böyle bir kabul tam olarak doğru değildir. Aşağıdaki şekilde iki saf bileşikteki azot tayininde (Kjeldahl yöntemiyle) 4 analizci tarafından elde edilen sonuçlardaki mutlak hatalar verilmektedir. Azotun mikro-Kjeldahl yöntemiyle tayininde mutlak hata. Her nokta tek tayinle ilgili hatayı gösterir. (xi - xt) ile ifade edilen her düşey çizgi, takımın gerçek değerden olan mutlak ortalama sapmasıdır. Rasgele hata Rasgele hata Rasgele hata Sistematik hata Sistematik hata Rasgele hata
 ve sistematik (belirli) hatalardan kaynaklanır. Genellikle bir ölçümde cevabı yüksek bir kesinlikle bildiğimizde, onun doğru değer olduğunu kabul ederiz. Oysa böyle bir kabul tam olarak doğru değildir. Aşağıdaki şekilde iki saf bileşikteki azot tayininde (Kjeldahl yöntemiyle) 4 analizci tarafından elde edilen sonuçlardaki mutlak hatalar verilmektedir. Azotun mikro-Kjeldahl yöntemiyle tayininde mutlak hata. Her nokta tek tayinle ilgili hatayı gösterir. (xi - xt) ile ifade edilen her düşey çizgi, takımın gerçek değerden olan mutlak ortalama sapmasıdır. Rasgele hata. Rasgele hata. Rasgele hata. Sistematik hata. Sistematik hata. Rasgele hata.")
8
Görüldüğü gibi 2. ve 4. analizcilerin verileri diğerlerine göre ortalama değer etrafında daha fazla (simetrik olarak) dağılmıştır (rasgele hata). Başka bir deyişle yapılan hata (rasgele), ölçümün kesinliğine etki etmiştir. 1. ve 2. analizcinin sonuçlarına göre, 3. ve 4. analizcinin sonuçları gerçek değerlerden büyük oranda sapmalar göstermiştir (sistematik hata). Başka bir deyişle yapılan hata (sistematik), ölçümün doğruluğuna etki etmiştir. Öte yandan 1 numaralı analizci, kesinliği ve doğruluğu en iyi olan sonuçları elde etmiştir. Sistematik Hatalar: Sistematik hataların belirli bir değeri ve bilinen bir sebebi vardır ve aynı yolla yapılan ölçüm tekrarlarında hataların büyüklüğü aynıdır. Sistematik hatalar, bir gruptaki bütün verilere aynı şekilde etki eder (sapma eğilimi). Sistematik hata kaynakları : 1. Alet Hataları: Bütün ölçme cihazları sistematik hata kaynaklarıdır. 2. Yöntem Hataları: Fazla ya da az reaktif ilave edilmesi veya yanlış dalga boyunda ölçüm alınması. 3. Kişisel Hatalar: Dikkatsizlik, ihmal veya deneycinin kişisel kusurlarından kaynaklanır. Rasgele hatalardan farklı olarak, tekrarlanır hataların olması gerekir. Örneğin, bir kişi büretteki bir noktayı sürekli yüksek okuyabilir. Ya da renk körlüğü, titrasyon esnasında renk dönümlerinin sürekli kaçırılmasına sebep olabilir.
. Başka bir deyişle yapılan hata (sistematik), ölçümün doğruluğuna etki etmiştir. Öte yandan 1 numaralı analizci, kesinliği ve doğruluğu en iyi olan sonuçları elde etmiştir. Sistematik Hatalar: Sistematik hataların belirli bir değeri ve bilinen bir sebebi vardır ve aynı yolla yapılan. ölçüm tekrarlarında hataların büyüklüğü aynıdır. Sistematik hatalar, bir gruptaki bütün. verilere aynı şekilde etki eder (sapma eğilimi). Sistematik hata kaynakları : 1. Alet Hataları: Bütün ölçme cihazları sistematik hata kaynaklarıdır. 2. Yöntem Hataları: Fazla ya da az reaktif ilave edilmesi veya yanlış dalga boyunda ölçüm alınması. 3. Kişisel Hatalar: Dikkatsizlik, ihmal veya deneycinin kişisel kusurlarından kaynaklanır. Rasgele hatalardan farklı olarak, tekrarlanır hataların olması gerekir. Örneğin, bir kişi büretteki bir noktayı sürekli yüksek okuyabilir. Ya da renk körlüğü, titrasyon esnasında renk dönümlerinin sürekli kaçırılmasına sebep olabilir.")
9
Sistematik hatalar sabit veya orantılı olabilir.
Sabit hatalar: Sabit bir hatanın büyüklüğü, ölçülen miktarın büyüklüğüne bağlı olmaksızın sabittir. Bir gravimetrik analizde bir çökeleğin 200 mL yıkama sıvısı ile yıkanması sonucu, 0,50 mg çökeltinin kaybolduğunu farz edelim. Yapılan işlem gereği kaybolan miktar elde edilen çökeleğin miktarına bağlı kalmaksızın aynı olacaktır (sabit hata). Ancak, Çökelti 500 mg ise, bağıl hata, -(0,50/500)x100 = -% 0,1 olur. Çökelti 50 mg ise, bağıl hata, -(0,50/50)x100 = -% 1,0 olur. Görüldüğü gibi ölçülen büyüklük küçüldükçe bağıl hata artar. Orantılı hatalar: Orantılı hataların yaygın sebebi numunede girişim yapan safsızlıklardır. Numune miktarı ile orantılı olarak artar ya da azalır.
. Ancak, Çökelti 500 mg ise, bağıl hata, -(0,50/500)x100 = -% 0,1 olur. Çökelti 50 mg ise, bağıl hata, -(0,50/50)x100 = -% 1,0 olur. Görüldüğü gibi ölçülen büyüklük küçüldükçe bağıl hata artar. Orantılı hatalar: Orantılı hataların yaygın sebebi numunede girişim yapan safsızlıklardır. Numune miktarı ile orantılı olarak artar ya da azalır.")
10
Sistematik yöntem hatalarının tespiti:
1. Standart numunelerin analizi: Bir sistematik hatayı belirlemenin en güzel yolu, derişimleri tam olarak bilinen standart referans maddelerin analizlerinin yapılmasıdır. 2. Bağımsız Analizler: Standart numuneler bulunamazsa, uygulanan yönteme paralel olarak başka bir analitik yöntem daha uygulanır. 3. Tanık Tayinler: Tanık çözelti, tayinde kullanılan reaktif ve çözücüleri içerir ancak analiti içermez. Tanık çözeltiye de numuneye yapılan işlemlerin aynısı uygulanır. Tanıktan elde edilen sonuçlar, numune sonuçlarının düzeltilmesinde kullanılır. Örneğin, tanık çözeltide 3 ppm Pb tespit edilmişse, numunede tespit edilen Pb’den 3 ppm çıkartılarak sonuç düzeltilmiş olur. 4. Numune Miktarı: Numune miktarı değiştirilerek sabit hatalar tespit edilebilir. Örneğin, numune miktarı artarken, sabit hatanın etkisi azalmaktadır.

11
SORULAR ve PROBLEMLER 1. Sabit ve orantılı hatanın arasındaki farkı açıklayınız. 2. Sistematik yöntem hataları nasıl tespit edilir? 3. Bir analiz yöntemi % 1,2 altın içeren filizin analizinde kullanılmaktadır. 0,4 mg kayıp sonucu oluşan bağıl hatanın -% 0,2’yi geçmemesi için alınması gereken en az numune kütlesi ne olmalıdır? Numune kütlesi = mg

12
BÖLÜM 6 Kimyasal Analizde Rasgele Hatalar

13
Bölüm 6. Kimyasal Analizde Rasgele Hatalar
Her ölçme rasgele hatalar (belirsiz hatalar) içerir. Bu tür hatalar hiçbir zaman yok edilemez. Tespit edilemeyen küçük belirsizlikler birleşerek, tespit edilebilir rasgele hatayı oluştururlar. Belirsizliğin kaynağını belirlesek bile, o belirsizliği ölçemeyiz; çünkü bunlar ayrı ayrı ölçülemeyecek kadar küçüktürler. Örnek 1. Toplu hatanın, küçük dört rasgele hatanın birleşmesiyle oluştuğunu düşünelim. Her bir hatanın da sonucu ±U kadar değiştireceğini kabul edelim. Bu durumda aşağıdaki çizelgedeki kombinasyonları elde ederiz. En sık rastlanan durum ise, ortalamadan sapmanın olmadığı durumdur.
 içerir. Bu tür hatalar hiçbir zaman yok edilemez. Tespit edilemeyen küçük belirsizlikler birleşerek, tespit edilebilir rasgele hatayı oluştururlar. Belirsizliğin kaynağını belirlesek bile, o belirsizliği ölçemeyiz; çünkü bunlar ayrı ayrı ölçülemeyecek kadar küçüktürler. Örnek 1. Toplu hatanın, küçük dört rasgele hatanın birleşmesiyle oluştuğunu düşünelim. Her bir hatanın da sonucu ±U kadar değiştireceğini kabul edelim. Bu durumda aşağıdaki çizelgedeki kombinasyonları elde ederiz. En sık rastlanan durum ise, ortalamadan sapmanın olmadığı durumdur.")
14
(a) Dört rasgele belirsizlik
(b) On rasgele belirsizlik (c) Çok büyük sayıda rasgele belirsizlik içeren ölçmeler için frekans dağılımı.
 On rasgele belirsizlik. (c) Çok büyük sayıda rasgele belirsizlik içeren ölçmeler için frekans dağılımı.")
15
Gauss veya normal hata eğrisi, verilerin sonsuz veri takımının ortalaması etrafında simetrik dağılımını gösteren bir eğridir. Birçok nicel analitik deneylerden elde edilen tecrübeyle, tekrarlanan verilerin dağılımının, Gauss eğrisine benzediğini görebiliriz. Çünkü genellikle küçük rasgele hatalar birbirini giderme eğilimindedir ve ortalama üzerinde çok az etkiye sahiptirler. Bununla beraber, bazen aynı yönde meydana gelirler ve büyük pozitif veya negatif hata oluştururlar. Örnek 2. Bir pipetin kalibrasyonundaki rasgele belirsizliklerin kaynakları: Pipetin üzerindeki işaretlemeye göre, su seviyesi ve termometredeki civa seviyesi gibi okuma kararları Boşaltma zamanında ve boşaltırken pipetin eğimindeki değişmeler Pipetin hacmine, sıvının viskozitesine ve terazinin performansına etki eden sıcaklık dalgalanmaları Terazi okumalarında küçük değişmelere sebep olan titreşimler ve hava akımı Bu rasgele hata kaynaklarından herhangi birinin, ölçümün hatasına katkısını belirleyemeyiz; fakat onların toplu etkisi, verilerin ortalama etrafında dağılmalarına sebep olur.

16
Bir pipetin kalibrasyonu gibi basit bir işleme bile, küçük kontrol edilemeyen birçok değişken etki eder. Bu rastgele hata kaynaklarından herhangi birinin ölçüm hatasına katkısını belirleyemeyiz. Fakat onların toplu etkisi, verilerin ortalama etrafında dağılmalarına sebep olur. 16

17
Ölçüm sayısı arttıkça, analitik sonuçların sürekli bir eğri şeklini (Gauss hata eğrisi) aldığını görebiliriz.
 aldığını görebiliriz.")
18
Rasgele hatanın istatistik değerlendirilmesi:
İstatistik analiz, bir veri takımında var olan bir bilgiyi açığa çıkarır. Örneğin, bir normal hata (Gauss) eğrisini değerlendirmek için istatistik kullanılabilir. Popülasyon Ortalaması (μ) ve Örneklem Ortalaması Popülasyon, analizcinin ilgilendiği alınabilir bütün ölçümlerin kümesidir. Örneklem ise, popülasyondan seçilmiş bir ölçümler alt kümesidir. Yüzbinlerce tablet üreten bir vitamin hapı üretim hattında, kalite kontrol amacıyla herbir tabletin ayrı ayrı incelenmesi çok zaman alıcı ve zordur. Dolayısıyla analiz için seçilmiş tabletlerden oluşan bir örneklem alırız. Sonra bu örneklemi inceleyerek popülasyonun nitelikleri ile ilgili bir yargı geliştiririz. Bir şeker hastasının kanında glikoz tayin ederken, kanın tamamını kullanıp çok sayıda analiz (popülasyon) yapılabilir. Ancak bunun yerine daha az (makul) sayıda ölçüm (örneklem) tercih edilir. İstatistiksel örneklem ile analitik numune eş anlamlıdır. Popülasyon (aritmetik) ortalamasının gerçek ortalamayı temsil ettiği açıktır. Ancak, ölçme sayısı (N) artarsa, örneklem ortalaması , popülasyon ortalamasına (μ) yaklaşır:
 eğrisini değerlendirmek için istatistik kullanılabilir. Popülasyon Ortalaması (μ) ve Örneklem Ortalaması. Popülasyon, analizcinin ilgilendiği alınabilir bütün ölçümlerin kümesidir. Örneklem ise, popülasyondan seçilmiş bir ölçümler alt kümesidir. Yüzbinlerce tablet üreten bir vitamin hapı üretim hattında, kalite kontrol amacıyla herbir tabletin ayrı ayrı incelenmesi çok zaman alıcı ve zordur. Dolayısıyla analiz için seçilmiş tabletlerden oluşan bir örneklem alırız. Sonra bu örneklemi inceleyerek popülasyonun nitelikleri ile ilgili bir yargı geliştiririz. Bir şeker hastasının kanında glikoz tayin ederken, kanın tamamını kullanıp çok sayıda analiz (popülasyon) yapılabilir. Ancak bunun yerine daha az (makul) sayıda ölçüm (örneklem) tercih edilir. İstatistiksel örneklem ile analitik numune eş anlamlıdır. Popülasyon (aritmetik) ortalamasının gerçek ortalamayı temsil ettiği açıktır. Ancak, ölçme sayısı (N) artarsa, örneklem ortalaması , popülasyon ortalamasına (μ) yaklaşır:")
19
Gauss eğrileri, popülasyon ortalaması (m, mü) ve popülasyon standart sapması (s, sigma) adı verilen iki parametrenin fonksiyonu olarak gösterilebilir. Bu parametreler, örneklem ortalaması ve örneklemin standart sapması (s) ile tahmini olarak bulunabilir. Bunlar birer istatistiktir. Başka bir deyişle bir parametrenin, bir veri örnekleminden bulunan tahmini değerine istatistik denir. Örneklem ortalaması bir veri popülasyonu içinden seçilmiş sınırlı sayıdaki ölçmelerin aritmetik ortalamasıdır. Popülasyon standart sapması: Örneklem standart sapması: Dikkat edilirse soldaki eşitlikteki N yerine, sağdaki eşitlikte N-1 (serbestlik derecesinin sayısı) kullanılmıştır. Çünkü, az sayıda alınan örneklem için N-1 yerine N kullanılsaydı, ortalamaya bağlı s değeri, gerçek standart sapma değerinden (s) daha küçük olurdu. Yani s, bir negatif sapma taşırdı. Oysa burada elde edilen s, popülasyon standart sapmasının (s) daha az tek yönlü sapma gösteren tahmini bir değeri olur. Eğer N artırılırsa, s = s olur ve dolayısıyla örneklemin standart sapması yerine popülasyon standart sapması kullanılabilir. N → ∞ iken, → m ve s → s olur.
 ile tahmini olarak bulunabilir. Bunlar birer istatistiktir. Başka bir deyişle bir parametrenin, bir veri örnekleminden bulunan tahmini değerine istatistik denir. Örneklem ortalaması bir veri popülasyonu içinden seçilmiş sınırlı sayıdaki ölçmelerin aritmetik ortalamasıdır. Popülasyon standart sapması: Örneklem standart sapması: Dikkat edilirse soldaki eşitlikteki N yerine, sağdaki eşitlikte N-1 (serbestlik derecesinin sayısı) kullanılmıştır. Çünkü, az sayıda alınan örneklem için N-1 yerine N kullanılsaydı, ortalamaya bağlı s değeri, gerçek standart sapma değerinden (s) daha küçük olurdu. Yani s, bir negatif sapma taşırdı. Oysa burada elde edilen s, popülasyon standart sapmasının (s) daha az tek yönlü sapma gösteren tahmini bir değeri olur. Eğer N artırılırsa, s = s olur ve dolayısıyla örneklemin standart sapması yerine popülasyon standart sapması kullanılabilir. N → ∞ iken, → m ve s → s olur.")
20
Varyans (s2) ve diğer kesinlik ölçütleri:
Verilerin kesinliğini rapor etmek için genellikle standart sapma kullanılır. Bununla beraber, varyans (s2), bağıl standart sapma (RSD) ve varyasyon katsayısı (CV) da kullanılır. Varyans (s2): Standart sapmanın karesidir. Bağıl Standart Sapma (RSD) : Bir analizin kesinliğinin belirtilmesi için genelde standart sapma mutlak olarak değil, bağıl olarak verilir. Varyasyon katsayısı (CV) : Bağıl standart sapmanın 100 ile çarpılmış halidir. Yayılım (W) : Bir veri takımındaki en büyük ve en küçük değerler arasındaki farktır.
, bağıl standart sapma (RSD) ve varyasyon katsayısı (CV) da kullanılır. Varyans (s2): Standart sapmanın karesidir. Bağıl Standart Sapma (RSD) : Bir analizin kesinliğinin belirtilmesi için genelde standart sapma mutlak olarak değil, bağıl olarak verilir. Varyasyon katsayısı (CV) : Bağıl standart sapmanın 100 ile çarpılmış halidir. Yayılım (W) : Bir veri takımındaki en büyük ve en küçük değerler arasındaki farktır.")
21
Anlamlı rakamlar: Bir deneysel ölçümle ilgili muhtemel belirsizliğin gösterilmesinin basit bir yolu, sonucu sadece anlamlı rakamları içerecek şekilde yuvarlamaktır. Bir sayıdaki anlamlı rakamlar, kesin olan rakamların tamamı ve ilk belirsiz rakamdır. Anlamlı rakamların sayısını bulmak için kurallar: 1. Baştaki sıfırlar atılır. 2. Bir ondalık sayıda virgülden sonra gelen hariç, sondaki bütün sıfırlar atılır. 3. Sıfır olmayan iki rakam arasındaki bütün rakamlar (sıfır dahil) anlamlıdır. Sayısal hesaplamalarda anlamlı rakamlar: Toplama ve çıkarmada, sonucun ondalık rakam sayısı, işleme giren sayılar arasında, en az sayıda ondalık basamağı bulunan sayıdaki kadar olmalıdır. Örnek 2. 3,4 + 0, ,31 = 10,730 (sonuç 10,7’ye yuvarlatılmalıdır.) Çarpma ve bölmedeki en zayıf halka ise, en az anlamlı rakam içeren sayıdaki anlamlı rakam sayısıdır.
 anlamlıdır. Sayısal hesaplamalarda anlamlı rakamlar: Toplama ve çıkarmada, sonucun ondalık rakam sayısı, işleme giren sayılar arasında, en az sayıda ondalık basamağı bulunan sayıdaki kadar olmalıdır. Örnek 2. 3,4 + 0, ,31 = 10,730 (sonuç 10,7’ye yuvarlatılmalıdır.) Çarpma ve bölmedeki en zayıf halka ise, en az anlamlı rakam içeren sayıdaki anlamlı rakam sayısıdır.")
24
ÖRNEK: Aşağıdaki cevapları sadece anlamlı rakamlar kalacak şekilde yuvarlatınız.
log 4,000 × 10−5 = −4, ve (b) antilog 12,5 = 3, × 1012. (a) log 4,000 × 10−5 = −4,3979 (virgülden sonra sadece 4 rakam bırakırız) (b) antilog 12,5 = 3 × (sadece 1 rakam bırakabiliriz) ÖRNEK: 1,08 ≈ 1, ,965 ≈ 0, ,040 ≈ 0, ,37442x106 ≈ 2,374x106 Bir sayının sonundaki 5’i yuvarlarken elde edilen sonuç, çift sayı ile bitmelidir. 0,635 ≈ 0, ,625 ≈ 0, ,555 ≈ 61, ,069 ≈ 0, ,749 ≈ 33,75 0,027 ≈ 0,03 Hesaplama tamamlanıncaya kadar yuvarlatma yapmamak özellikle önemlidir. SORU: Bir kan numunesinin kurşun içeriğini tayin etmek için yapılan tekrarlanan analizlerde aşağıdaki sonuçlar elde edilmiştir: 0,752; 0,756; 0,752; 0,751 ve 0,760 ppm Pb. Bu veri takımının ortalamasını ve standart sapmasını hesaplayınız. Aynı veri takımı için (a) varyansı, (b) binde kısım olarak bağıl standart sapmayı, (c) varyasyon katsayısını ve (d) yayılımı hesaplayınız.
 antilog 12,5 = 3, × (a) log 4,000 × 10−5 = −4,3979 (virgülden sonra sadece 4 rakam bırakırız) (b) antilog 12,5 = 3 × 1012 (sadece 1 rakam bırakabiliriz) ÖRNEK: 1,08 ≈ 1,1 0,965 ≈ 0,96 0,040 ≈ 0,04 2,37442x106 ≈ 2,374x106. Bir sayının sonundaki 5’i yuvarlarken elde edilen sonuç, çift sayı ile bitmelidir. 0,635 ≈ 0,64 0,625 ≈ 0,62 61,555 ≈ 61,56 0,069 ≈ 0,07 33,749 ≈ 33,75. 0,027 ≈ 0,03. Hesaplama tamamlanıncaya kadar yuvarlatma yapmamak özellikle önemlidir. SORU: Bir kan numunesinin kurşun içeriğini tayin etmek için yapılan tekrarlanan analizlerde aşağıdaki sonuçlar elde edilmiştir: 0,752; 0,756; 0,752; 0,751 ve 0,760 ppm Pb. Bu veri takımının ortalamasını ve standart sapmasını hesaplayınız. Aynı veri takımı için (a) varyansı, (b) binde kısım olarak bağıl standart sapmayı, (c) varyasyon katsayısını ve (d) yayılımı hesaplayınız.")
25
Standart sapma = s = √ [(48,61-(15,5)2/5)]/(5-1) = 0,37
Standart sapma = s = √ [(48,61-(15,5)2/5)]/(5-1) = 0,37 Varyasyon katsayısı = CV = (0,37/3,1) x 100 = % 12 2. Problem 1’deki veriler için doğru kabul edilen değer 3,0 ppm olsaydı mutlak hata ve binde bir cinsinden bağıl hata ne olurdu? E = 3,1-3,0 = 0,1 ve Er = (0,1/3,0) x 1000 = 33 ppt olurdu.
![Standart sapma = s = √ [(48,61-(15,5)2/5)]/(5-1) = 0,37](http://slideplayer.biz.tr/slide/8910095/26/images/25/Standart+sapma+%3D+s+%3D+%E2%88%9A+%5B%2848%2C61-%2815%2C5%292%2F5%29%5D%2F%285-1%29+%3D+0%2C37.jpg "Standart sapma = s = √ [(48,61-(15,5)2/5)]/(5-1) = 0,37. Varyasyon katsayısı = CV = (0,37/3,1) x 100 = % Problem 1’deki veriler için doğru kabul edilen değer 3,0 ppm olsaydı mutlak hata ve binde bir cinsinden bağıl hata ne olurdu E = 3,1-3,0 = 0,1 ve Er = (0,1/3,0) x 1000 = 33 ppt olurdu.")
26
BÖLÜM 7 İstatistik Verilerin İşlenmesi ve Değerlendirilmesi

27
Bölüm 7. İstatistik Verilerin İşlenmesi ve Değerlendirilmesi
Yandaki resimde The Saturday Evening Post gazetesinde 1959’da çıkan "Suçlu mu, suçsuz mu?" başlıklı manşet resmi görülmektedir. Bir dava için kurulan 12 kişilik halk jürisindeki üyelerden biri diğer jüri üyeleri ile fikir ayrılığına düşmüş; diğerleri onu ikna etmeye çalışıyor. Jüri odasında iki tip hata olabilir: masum bir insanı suçlu bulmak veya bir suçluyu masum görmek. Benzer şekilde, istatistik testlerle, iki büyüklüğün aynı olup olmadığına karar verilir. Bu testlerde ya istatistiksel olarak aynı olan büyüklüklerin gerçekte de aynı olacağı reddedilir. Ya da istatistiksel olarak farklı olan büyüklüklerin gerçekte aynı olacağı kabul edilir.

28
Deney sonuçlarının kalitesinin pekiştirilmesi için, bir çok istatistik hesaplamalar (test uygulamaları) kullanılmaktadır: 1. Güven aralıkları: Kimyasal analizlerde, pek çok sayıda ölçüm almadan gerçek ortalama (μ) bulunamaz. Fakat istatistik kullanılarak, sınırlı sayıda ölçümle elde edilen ortalama değer merkez olmak üzere, popülasyon ortalamasının (μ) belli bir olasılıkla tayin edilen bir aralıkta olması beklenir. Bu sınırlara güven sınırı, bu sınırların belirlediği aralığa da güven aralığı (GA) denir. Kısaca, ortalama için güven aralığı, popülasyon ortalamasının (m) belli bir olasılıkla yer alması beklenen aralıktır. Güven seviyesi (GS) ise, gerçek ortalamanın belli bir aralıkta yer alması olasılığıdır. Örnek 1. Potasyum ölçümlerinden elde edilen bir veri takımı için popülasyon ortalamasının (% 99 olasılıkla ya da güven seviyesinde, GS) % 7,25 ± % 0,15 K olduğunu düşünelim. (GA= μ ± s) Buna göre ortalama değer (% 99 olasılıkla), % 7,10 - % 7,40 K aralığında yer almalıdır.
 bulunamaz. Fakat istatistik kullanılarak, sınırlı sayıda ölçümle elde edilen ortalama değer. merkez olmak üzere, popülasyon ortalamasının (μ) belli bir olasılıkla tayin edilen bir aralıkta olması beklenir. Bu sınırlara güven sınırı, bu sınırların belirlediği aralığa da güven aralığı (GA) denir. Kısaca, ortalama için güven aralığı, popülasyon ortalamasının (m) belli bir olasılıkla yer alması beklenen aralıktır. Güven seviyesi (GS) ise, gerçek ortalamanın belli bir aralıkta yer alması olasılığıdır. Örnek 1. Potasyum ölçümlerinden elde edilen bir veri takımı için popülasyon ortalamasının (% 99 olasılıkla ya da güven seviyesinde, GS) % 7,25 ± % 0,15 K olduğunu düşünelim. (GA= μ ± s) Buna göre ortalama değer (% 99 olasılıkla), % 7,10 - % 7,40 K aralığında yer almalıdır.")
29
s’nın bilindiği (veya s’nin s’ya yakın olduğu) durumlarda güven aralığı:
Bir veri takımındaki herhangi bir verinin (x), popülasyon ortalamasından (m) sapma miktarının standart sapmaya oranı (z parametresi) şöyle bulunur: Söz konusu eşitlik, z’nin ± değerlerine göre düzenlenirse, μ için GA = x ± zσ olur. Ancak, m için daha iyi bir tahmin elde etmek amacıyla, N tane ölçümün deneysel ortalaması , s ≈ σ kabulü yapabildiğimizde şu eşitlik kullanılır: Örnek 2. Aşağıda verilen Gauss eğrilerinde bağıl frekans, popülasyon standart sapma birimi cinsinden (σ) popülasyon ortalamasından sapma değeri (x-μ) olan z büyüklüğünün bir fonksiyonu olarak grafiğe geçirilmiştir. Görüldüğü gibi, ölçüm sayısı artırıldığında, güven seviyesi (olasılığı, GS) genişlerken, güven aralığı (GA) daralmaktadır. Örneğin yaptığımız her 100 ölçmenin 90’ının gerçek ortalamanın (μ) x ± 1,64 σ’lık aralığı içine düştüğünü kabul edebiliriz. Burada kullanılan olasılık düzeyi yani güven seviyesi (GS) olarak adlandırılır. Burada z değeri, aynı zamanda kabul edilen güven seviyesine bağlı bir parametredir.
, popülasyon ortalamasından (m) sapma miktarının standart sapmaya oranı (z parametresi) şöyle bulunur: Söz konusu eşitlik, z’nin ± değerlerine göre düzenlenirse, μ için GA = x ± zσ olur. Ancak, m için daha iyi bir tahmin elde etmek amacıyla, N tane ölçümün deneysel ortalaması , s ≈ σ kabulü yapabildiğimizde şu eşitlik kullanılır: Örnek 2. Aşağıda verilen Gauss eğrilerinde bağıl frekans, popülasyon standart sapma birimi cinsinden (σ) popülasyon ortalamasından sapma değeri (x-μ) olan z büyüklüğünün bir fonksiyonu olarak grafiğe geçirilmiştir. Görüldüğü gibi, ölçüm sayısı artırıldığında, güven seviyesi (olasılığı, GS) genişlerken, güven aralığı (GA) daralmaktadır. Örneğin yaptığımız her 100 ölçmenin 90’ının gerçek ortalamanın (μ) x ± 1,64 σ’lık aralığı içine düştüğünü kabul edebiliriz. Burada kullanılan olasılık düzeyi yani güven seviyesi (GS) olarak adlandırılır. Burada z değeri, aynı zamanda kabul edilen güven seviyesine bağlı bir parametredir.")
30
Şekil 7-1 Çeşitli ±z değerleri için Gauss eğrisi altında kalan alanlar.
(a) z = ±0,67; (b) z = ±1,28; (c) z = ±1,64; (d) z = ±1,96; (e) z = ±2,58.
 z = ±0,67; (b) z = ±1,28; (c) z = ±1,64; (d) z = ±1,96; (e) z = ±2,58.")
31
Farklı güven seviyeleri için z değerleri Çizelge 7-1’de ve güven aralığının N’ye bağlı olarak büyüklüğü, Çizelge 7-2’de görülmektedir.

32
s’nın bilinmediği durumda güven aralığı:
Sınırlı numune sayısı ve kısıtlı zaman durumlarında, s’nın doğru biçimde hesabı güçleşir. Bu durumda güven sınırları da oldukça genişler. s’deki değişebilirliği hesaba katmak için, başka bir istatistik parametre olan t değeri kullanılır: N tane ölçümün ortalaması için t değeri, şeklinde yazılır. Yukarıdaki her iki eşitlik, z parametresini veren eşitliklere benzemektedir. Benzer şekilde GA, şeklinde yazılır. t’nin, s’nin hesaplanmasının serbestlik sayısına (N-1) bağlı olduğu da unutulmamalıdır.
 bağlı olduğu da unutulmamalıdır.")
33
Örnek 3. Bir kan numunesinin alkol içeriği için aşağıdaki veriler elde edilmiştir:
% C2H5OH : 0,084; 0,089 ve 0,079. (a) Yöntemin kesinliği ile ilgili ek bilgi olmadığını farz ederek %95 güven sınırlarını hesaplayınız. Kesinlikle ilgili bilgi olmadığına göre s (ve dolayısıyla t) üzerinden hesap yapılır. Bunun için önce s’yi veren eşitlik kullanılır: Ancak yukarıdaki eşitliğin düzenlenmiş halini kullanmak daha kolaydır: (a) Σxi = 0, , ,079 = 0,252 ve (Σxi)2 = 0,063504 Σxi2 = 0, , , = 0,021218 s = √(0, , /3)/ (3-1) = % 0,005 C2H5OH olur.
 Yöntemin kesinliği ile ilgili ek bilgi olmadığını farz ederek %95 güven sınırlarını hesaplayınız. Kesinlikle ilgili bilgi olmadığına göre s (ve dolayısıyla t) üzerinden hesap yapılır. Bunun için önce s’yi veren eşitlik kullanılır: Ancak yukarıdaki eşitliğin düzenlenmiş halini kullanmak daha kolaydır: (a) Σxi = 0, , ,079 = 0,252 ve (Σxi)2 = 0, Σxi2 = 0, , , = 0, s = √(0, , /3)/ (3-1) = % 0,005 C2H5OH olur.")
34
Çizelge 7-3, serbestlik derecesi (N-1)=2
Burada = 0,252/3 = 0,084’tür. Çizelge 7-3, serbestlik derecesi (N-1)=2 ve % 95 güven seviyesi için t = 4,30 olduğunu göstermektedir. %95 GA = 0,084 ± (4,30 . 0,005)/√3 = %0,084 ± 0,012 C2H5OH olur. Yani popülasyon ortalaması %95 olasılıkla 0,096 ile 0,072 arasında kalır. (b) s → s = % 0,005 C2H5OH olduğunu farz ederek, ortalamanın % 95 güven sınırlarını hesaplayınız. s’yı artık bildiğimize göre, z istatistiği kullanılabilir. eşitliğini direkt kullanarak çözüm bulunur: % 95 GA = 0,084 ± (1,96 . 0,005)/√3 = = %0,084 ± 0,006 C2H5OH olur. (Eşitlikteki z değerinin 1,96 olur, Bakınız Çizelge 7.1.) Burada z istatistiği kullanıldığında güven aralığını önemli miktarda daralttığına dikkat ediniz.
=2. ve % 95 güven seviyesi için t = 4,30 olduğunu göstermektedir. %95 GA = 0,084 ± (4,30 . 0,005)/√3. = %0,084 ± 0,012 C2H5OH olur. Yani popülasyon ortalaması %95 olasılıkla 0,096 ile 0,072 arasında kalır. (b) s → s = % 0,005 C2H5OH olduğunu farz ederek, ortalamanın % 95 güven sınırlarını hesaplayınız. s’yı artık bildiğimize göre, z istatistiği kullanılabilir. eşitliğini direkt kullanarak çözüm bulunur: % 95 GA = 0,084 ± (1,96 . 0,005)/√3 = = %0,084 ± 0,006 C2H5OH olur. (Eşitlikteki z değerinin 1,96 olur, Bakınız Çizelge 7.1.) Burada z istatistiği kullanıldığında güven aralığını önemli miktarda daralttığına dikkat ediniz.")
35
Ha: m ≠ 0,02 ppm (m > 0,02 ppm yada m < 0,02 ppm )
2. Hipotez testinde istatistiğin (z ve t testlerinin) uygulanması: Genel olarak hipotez, karşılaşılan özel bir duruma ilişkin bir önermedir (varsayımdır). Popülasyon ortalamasının (m), bilinen değere (m0) yakınlığını belirleyebilmek için istatistik hipotez testi kullanılır. Herhangi bir hipotez testinde birbirine zıt iki sonuç vardır: 1. m = m0 kabul edilir (null hipotezi, H0) 2. m ≠ m0 kabul edilir (alternatif hipotez, Ha) İstatistikteki null hipotezi, gözlenen iki büyüklüğün aynı olduğunu ifade eder. Örneğin, bir endüstriyel atık sudaki kurşunun ortalama seviyesi 0,02 ppm bulunmuştur. Öte yandan, endüstriyel işlemlerdeki gelişmelere paralel olarak kurşun seviyesinin artma ya da azalma göstereceği de düşünülebilir. Buna göre hipotezimiz şöyle yazılır: H0: m = 0,02 ppm Ha: m ≠ 0,02 ppm (m > 0,02 ppm yada m < 0,02 ppm ) Bu hipotezler ışığında, çok sayıda ölçüm varsa (veya s biliniyorsa) z istatistiği (testi) (büyük örneklem), alternatif olarak, az sayıda ölçüm varsa (veya s bilinmiyorsa) t istatistiği (testi) (küçük örneklem) kullanılır.
 uygulanması: Genel olarak hipotez, karşılaşılan özel bir duruma ilişkin bir önermedir (varsayımdır). Popülasyon ortalamasının (m), bilinen değere (m0) yakınlığını belirleyebilmek için istatistik hipotez testi kullanılır. Herhangi bir hipotez testinde birbirine zıt iki sonuç vardır: 1. m = m0 kabul edilir (null hipotezi, H0) 2. m ≠ m0 kabul edilir (alternatif hipotez, Ha) İstatistikteki null hipotezi, gözlenen iki büyüklüğün aynı olduğunu ifade eder. Örneğin, bir endüstriyel atık sudaki kurşunun ortalama seviyesi 0,02 ppm bulunmuştur. Öte yandan, endüstriyel işlemlerdeki gelişmelere paralel olarak kurşun seviyesinin artma ya da azalma göstereceği de düşünülebilir. Buna göre hipotezimiz şöyle yazılır: H0: m = 0,02 ppm. Ha: m ≠ 0,02 ppm (m > 0,02 ppm yada m < 0,02 ppm ) Bu hipotezler ışığında, çok sayıda ölçüm varsa (veya s biliniyorsa) z istatistiği (testi) (büyük örneklem), alternatif olarak, az sayıda ölçüm varsa (veya s bilinmiyorsa) t istatistiği (testi) (küçük örneklem) kullanılır.")
36
t ve z testi için işlem sırası:
Null hipotezi oluşturulur. Ho: m = m0 kabul edilir. Test istatistiği oluşturulur. Alternatif hipotez oluşturulur, m ≠ m0 kabul edilir ve reddetme alanı belirlenir. (tkritik = t’nin tablodan elde edilen değeridir.) Ha : m = m0 için t (z) ≥ tkritik veya t ≤ -tkritik ise Ho reddedilir. Ha : m > m0 için t (z) ≥ tkritik ise Ho reddedilir. Ha : m < m0 için t (z) ≤ -tkritik ise Ho reddedilir.
 Ha : m = m0 için t (z) ≥ tkritik veya t ≤ -tkritik ise Ho reddedilir. Ha : m > m0 için t (z) ≥ tkritik ise Ho reddedilir. Ha : m < m0 için t (z) ≤ -tkritik ise Ho reddedilir.")
37
27,7 kcal/mol (ortalama değer) ≠ 30,8 kcal/mol (literatürde verilen)
Örnek 4. Bir sınıfta bulunan 30 öğrenci, kimyasal bir reaksiyonun aktifleşme enerjisini 27,7 kcal/mol (ortalama değer) olarak tayin etmişler ve bu tayindeki standart sapma 5,2 kcal/mol olarak hesaplanmıştır. Bu değer literatürde verilen 30,8 kcal/mol ile (1) % 95 güven seviyesinde ve (2) % 99 güven seviyesinde, uyumlu mudur ? N = 30 olduğundan, s = σ alınabilir (büyük örneklem-z testi). Çizelge 7.1.’e bakıldığında, % 95 güven seviyesi için z = ± 1,96 ve % 99 güven seviyesi için ise z = ± 2,58 dir. Test istatistiği şöyle hesaplanır: -3,26 ≤ -1,96 olduğundan H0 hipotezi reddedilir. Doğal olarak, % 99 güven seviyesi koşulu da red olunur. Çünkü güven seviyesi arttıkça, güven aralığı da artar ve daha yüksek dağılıma sahip bir sonuç ortaya çıkar. 27,7 kcal/mol (ortalama değer) ≠ 30,8 kcal/mol (literatürde verilen) Sonuç olarak; öğrenci ortalamasının literatürdeki verilerden gerçekte farklı olduğunu ve bu farkın tam olarak rasgele hatalardan kaynaklanmadığı belirlenmiş oldu.
 olarak tayin etmişler ve bu tayindeki standart sapma 5,2 kcal/mol olarak hesaplanmıştır. Bu değer literatürde verilen 30,8 kcal/mol ile. (1) % 95 güven seviyesinde ve. (2) % 99 güven seviyesinde, uyumlu mudur N = 30 olduğundan, s = σ alınabilir (büyük örneklem-z testi). Çizelge 7.1.’e bakıldığında, % 95 güven seviyesi için z = ± 1,96 ve % 99 güven seviyesi için ise z = ± 2,58 dir. Test istatistiği şöyle hesaplanır: -3,26 ≤ -1,96 olduğundan H0 hipotezi reddedilir. Doğal olarak, % 99 güven seviyesi koşulu da red olunur. Çünkü güven seviyesi arttıkça, güven aralığı da artar ve daha yüksek dağılıma sahip bir sonuç ortaya çıkar. 27,7 kcal/mol (ortalama değer) ≠ 30,8 kcal/mol (literatürde verilen) Sonuç olarak; öğrenci ortalamasının literatürdeki verilerden gerçekte farklı olduğunu ve bu farkın tam olarak rasgele hatalardan kaynaklanmadığı belirlenmiş oldu.")
38
Birleşik Standart Sapma: Tek başına s1 ve s2 standart sapmaları ile verilenden daha iyi bir popülasyon standart sapması (σ) tahmini elde etmek için ise birleşik standart sapma değeri kullanılır. Örnek: Şeker hastalarında glikoz seviyeleri rutin olarak ölçülüp kaydedilir. Glikoz düzeyi kısmen yüksek olan bir hastada glikoz derişimleri, farklı aylarda spektrofotometrik bir analitik yöntemle tayin edilmiştir. Glikoz düzeyini ayarlamak için diyete alınan bir hastada, diyetin etkinliğini belirlemek üzere aşağıdaki değerler bulunmuştur. Yöntem için birleşik standart sapmayı bulunuz. 38

40
Ortalamalardaki farklar için t testi:
t testi, iki veri setinin ortalamaları arasındaki farkın gerçek mi yoksa rasgele hatalardan mı kaynaklandığını bulmak amacıyla da kullanılır. Yada sonuçlar arasındaki farkın anlamlılığını tayin etmek için de kullanılır. Eğer sonuçların doğruluğuna güveniliyorsa, analizi yapılan iki maddenin aynı olup olmadığına karar vermek amacıyla da kullanılabilir. 1. analizci tarafından N1 tane deney tekrarı için ve 2. analizci tarafından N2 tane tekrarı için ortalama değerlerini varsayalım. Bu durumda türetilen t istatistiği şöyle formüle edilir: Örnek 5. İki şarap fıçısı, farklı kaynaklardan gelip gelmediklerini anlamak amacıyla alkol içerikleri bakımından analiz edilmiştir. Yapılan 6 analizden birinci fıçıdaki ortalama alkol içeriği % 12,61 etanol olarak bulunmuştur. İkinci fıçı için yapılan 4 analizin ortalaması da % 12,53 etanol olarak bulunmuştur. 10 analizin birleşik s değeri olarak % 0,070 elde edilmiştir. Bu veriler, % 95 güven seviyesinde, şaraplar arasında bir fark olduğunu gösterir mi? t istatistiği formülünden t = 1,771 olarak hesaplanır. t için kritik değer, tablodan % 95 güven seviyesinde ve 10-2=8 serbestlik derecesi için, 2,31 dir. % 95 güven seviyesinde 1,771 < 2,31 olduğundan bu iki şarap aynı kaynaktan gelmektedir.

41
Buna göre; H0: μ1 = μ2 yazabiliriz ya da (μ1 - μ2 = 0).
Null hipotezi, iki ortalamanın birbirine eşit olduğunu, hiçbir önemli fark olmadığını ve varsa da bu herhangi farkın rastgele hatalardan kaynaklandığını söyler. Buna göre; H0: μ1 = μ2 yazabiliriz ya da (μ1 - μ2 = 0). Hesaplanan değer < Tablo değeri (th < tt) ise; (H0) null hipotezinin kabulü Hesaplanan değer ≥ Tablo değeri (th ≥ tt) ise; (H0) null hipotezinin reddi 2.hipotezi test edemeyiz, ancak 1.hipotezi test edebiliriz (kabul veya red) Test istatistiği, istenilen belirli bir güven seviyesi için tablodan elde edilen kritik t değeri ile karşılaştırılır. Burada serbestlik derecesi olarak N1+N2-2 alınır. Test istatistiğinin mutlak değeri, kritik değerden küçükse, null hipotezi kabul edilir ve ortalamalar arasında anlamlı bir fark olmadığı gösterilmiş olur. t için test değeri, kritik değerden daha büyükse, ortalamalar arasında, anlamlı bir fark vardır. thesap < ttablo H0 red H0 kabul ttablo: 2,31 thesaplanan: 1,771 41
. Hesaplanan değer < Tablo değeri (th < tt) ise; (H0) null hipotezinin kabulü. Hesaplanan değer ≥ Tablo değeri (th ≥ tt) ise; (H0) null hipotezinin reddi. 2.hipotezi test edemeyiz, ancak 1.hipotezi test edebiliriz (kabul veya red) Test istatistiği, istenilen belirli bir güven seviyesi için tablodan elde edilen kritik t değeri ile karşılaştırılır. Burada serbestlik derecesi olarak N1+N2-2 alınır. Test istatistiğinin mutlak değeri, kritik değerden küçükse, null hipotezi kabul edilir ve ortalamalar arasında anlamlı bir fark olmadığı gösterilmiş olur. t için test değeri, kritik değerden daha büyükse, ortalamalar arasında, anlamlı bir fark vardır. thesap < ttablo. H0 red. H0 kabul. ttablo: 2,31. thesaplanan: 1,")
42
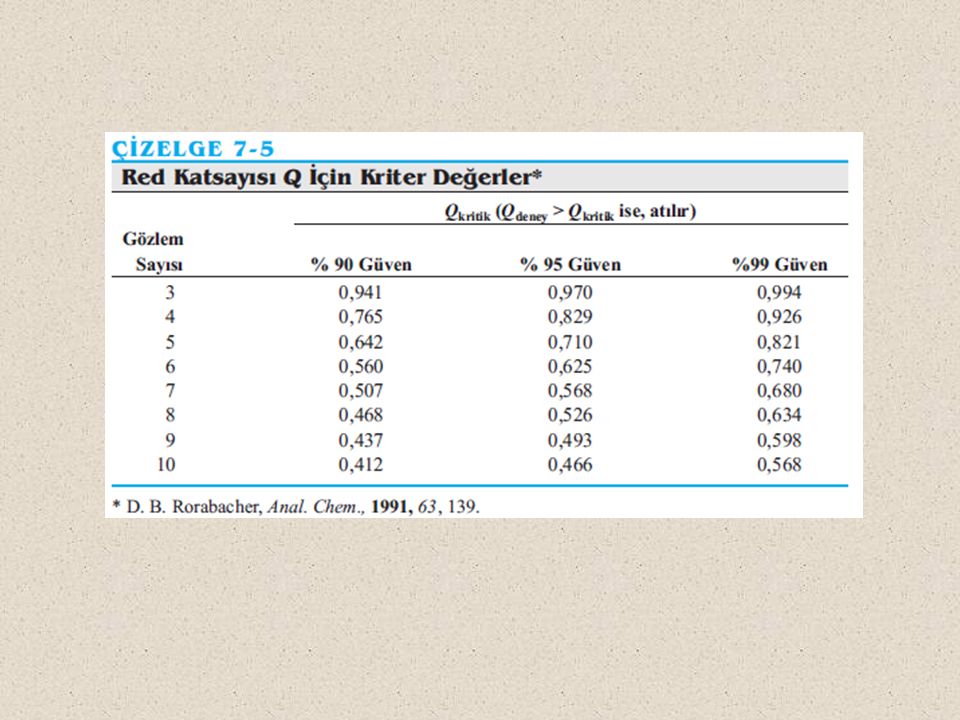
3. Kaba hataların belirlenmesi (Q testi):
Bazen, bir veri takımı içinde bazı değerler rasgele hatalar ile ortaya çıkacak hata aralığının dışına çıkabilir. Şüpheli veri gözden kaçmış bir kaba hatanın sonucu olabilir. Bu değerler (şüpheli veri), değerlendirme dışı tutulmalıdır. Ancak, bu değerlerin atılmasına karar verilirken bazı hesaplamalar yaparak buna karar vermeliyiz. Q testi bu amaç için sıkça kullanılan basit bir istatistiksel yöntemdir. Bu yöntemde şüpheli veri ile (xq) ile ona en yakın değer (xn) arasındaki farkın, yayılıma (W=Xeb-Xek) bölünmesiyle Q değeri hesaplanır: Bu oran daha sonra çizelgeden elde edilen kritik Q değeri ile karşılaştırılır. Q değeri, Qkritik değerinden büyükse, şüpheli veri belirlenen güven seviyesinde atılabilir. Aksine, Q değeri, Qkritik değerinden küçükse, şüpheli veri hesaba katılmalıdır (atılmamalıdır).
, değerlendirme dışı tutulmalıdır. Ancak, bu değerlerin atılmasına karar verilirken bazı hesaplamalar yaparak buna karar vermeliyiz. Q testi bu amaç için sıkça kullanılan basit bir istatistiksel yöntemdir. Bu yöntemde şüpheli veri ile (xq) ile ona en yakın değer (xn) arasındaki farkın, yayılıma (W=Xeb-Xek) bölünmesiyle Q değeri hesaplanır: Bu oran daha sonra çizelgeden elde edilen kritik Q değeri ile karşılaştırılır. Q değeri, Qkritik değerinden büyükse, şüpheli veri belirlenen güven seviyesinde atılabilir. Aksine, Q değeri, Qkritik değerinden küçükse, şüpheli veri hesaba katılmalıdır (atılmamalıdır).")
44
Şüpheli veriler için Q testi.
Örnek: Bir kalsit numunesinin analizinde CaO yüzdesi 55,95; 56,00; 56,04; 56,08 ve 56,23 olarak bulunmuştur. Son değer normal görünmemektedir. Bu değer tutulmalı mı, yoksa atılmalı mıdır? 56,23 ve 56,08 arasındaki fark % 0,15 dir. Yayılım ise % 0,28 dir. Beş ölçüm için %95 güven seviyesinde Q kritik 0,710 dir. 0,54 < 0,71 olduğundan şüpheli veri hesaba katılmalıdıır.

Benzer bir sunumlar









 Kİ-KARE DAĞILIMI VE ÖZELLİKLERİ>")












