Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
HUFFMAN VE TELEGRAF KODLAMALARI
Dilay YILDIRIM Damla AYGÜL Ezgi DEMİR

2
HUFFMAN KODLAMASI Sayısal haberleşme tekniklerinin önemli ölçüde arttığı günümüzde ,sayısal verilerin iletilmesi ve saklanması bir hayli önem kazanmıştır. Sayısal iletişim (digital communication) kuramında veriler çok çeşitli yöntemle sıkıştırılabilir. Bu yöntemlerden en çok bilineni David HUFFMAN tarafından öne sürülmüştür
 kuramında veriler çok çeşitli yöntemle sıkıştırılabilir. Bu yöntemlerden en çok bilineni David HUFFMAN tarafından öne sürülmüştür.")
3
David Huffman kimdir? Huffman Algoritması ,MIT de Robert Fano tarafından kurulan bir sınıfta ,öğrenci olan David Huffman tarafından 1952 yılında geliştirilmiştir.(ve bilişim teorisi alanında bir ilktir.)
")
4
HUFFMAN KODLAMASININ GEREKLİLİĞİ;
Huffman kodlaması verilen bir model (olasılık kümesi) için en uygun örnek kodunu oluşturur. Çünkü Huffman kodu,bilgisayar biliminde,veri sıkıştırması için kullanılan bir entropi kodlama algoritmasıdır. Huffman’ın algoritması,her sembol (ve ya karakter ) için özel bir kod üretir.
 için en uygun örnek kodunu oluşturur. Çünkü Huffman kodu,bilgisayar biliminde,veri sıkıştırması için kullanılan bir entropi kodlama algoritmasıdır. Huffman’ın algoritması,her sembol (ve ya karakter ) için özel bir kod üretir.")
5
HUFFMAN ALGORİTMASINDAKİ KODLAR;
Huffman algoritmasının kodları ikilik sistemdeki 1 ve 0 ‘lar dan oluşan bit haritası şeklindedir. Bir diğer önemli özelliği de veri içerisinde EN AZ kullanılan karakter için EN UZUN, EN ÇOK kullanılan karakter için de EN KISA karakteri üretir. Huffman tekniği günümüzde tek başına kullanılmaz.LZW,RLE gibi yöntemlerle birlikte kullanılır.

6
Huffman Algoritmasının sorduğu 2 basit soru :
Karakterleri kodlamak için sabit uzunluk ( aynı sayıda bit) kullanmalı mıyız? Sabit uzunluk kullanmayacak isek iki karakter arasındaki farkı nasıl anlayacağız?
 kullanmalı mıyız Sabit uzunluk kullanmayacak isek iki karakter arasındaki farkı nasıl anlayacağız")
7
Değişken Uzunluklu Kodlamanın Gerekliliği ;
Huffman kodu resimlerin sıkıştırılmasında (JPEG) ve ses kütüklerinin sıkıştırılmasında (MP 3) kullanılmaktadır. Sıkıştırma algoritmaları temel olarak iki kategoride incelenir.Bunlar kayıplı ve kayıpsız sıkıştırma algoritmalarıdır. Kayıplı algoritmalarda sıkıştırılan veriden orjinal veri elde edilemezken kayıpsız sıkıştırma algoritmalarında sıkıştırılmış veriden orjinal veri elde edilebilir.
 ve ses kütüklerinin sıkıştırılmasında (MP 3) kullanılmaktadır. Sıkıştırma algoritmaları temel olarak iki kategoride incelenir.Bunlar kayıplı ve kayıpsız sıkıştırma algoritmalarıdır. Kayıplı algoritmalarda sıkıştırılan veriden orjinal veri elde edilemezken kayıpsız sıkıştırma algoritmalarında sıkıştırılmış veriden orjinal veri elde edilebilir.")
8
Kayıplı sıkıştırma tekniklerine verilebilecek en güzel örnekler MPEG ve JPEG gibi standartlarda kullanılan sıkıştırmalardır. Bu tekniklerde sıkıştırma oranı arttırıldığında orijinal veride bozulmalar ve kayıplar görülür. Örneğin sıkıştırılmış resim formatı olan JPEG dosyalarının kaliteli yada az kaliteli olmasının nedeni sıkıştırma katsayısıdır. Yani benzer iki resim dosyasından daha az disk alanı kaplayan daha kötü kalitededir deriz.

9
Kayıpsız veri sıkıştırmada ;
durum çok farklıdır. Bu tekniklerde önemli olan orijinal verilerin aynen sıkıştırılmış veriden elde edilmesidir. Bu teknikler daha çok metin tabanlı verilen sıkıştırılmasında kullanılır. Bir metin dosyasını sıkıştırdıktan sonra metindeki bazı cümlelerin kaybolması istenmediği için metin sıkıştırmada bu yöntemler kullanılır.

10
HUFFMAN KODLAMASINDA SIKIŞTIRMA TEKNİĞİ;
Sıkıştırma tekniğinde verilerin frekans tablosunu elde etmek için statik ve dinamik yaklaşımları söz konusudur. Eğer statik yöntem seçilmişse iki yaklaşım daha vardır. Birinci yaklaşım, metin dosyasının diline göre sabit bir frekans tablosunu kullanmaktır. Frekans tablosunu elde etmek için kullanılan diğer bir yöntem ise metni baştan sona tarayarak her bir karakterin frekansını bulmaktır. Bu yöntemin dezavantajı ise sıkıştırılan verilerde geçen sembollerin frekansının da bir şekilde saklanma zorunluluğunun olmasıdır.

11
HUFFMAN AĞACININ OLUŞTURULMASI;
Frekans tablosunu metin dosyasını kullanarak elde ettikten sonra yapmamız gereken’’Huffman Ağacını’’ oluşturmaktır. Huffman ağacı hangi karakterin hangi bitlerle temsil edileceğini(kodlanacağını) belirlememize yarar.
 belirlememize yarar.")
12
HUFFMAN AĞACININ ALGORİTMALARI;
Ağacı oluşturmanın çeşitli algoritmaları olduğu gibi, en basit olanı, bir rüçhan sırası (öncelik sırası, priority queue) kullanmaktır. Bu sırada, en düşük olasılığa sahip olan düğüm (node), en yüksek rüçhana (en geride olacaktır) sahip olacaktır.
 kullanmaktır. Bu sırada, en düşük olasılığa sahip olan düğüm (node), en yüksek rüçhana (en geride olacaktır) sahip olacaktır.")
13
ALGORİTMA ADIMLARI; Algoritmanın adımları aşağıdaki şekildedir:
1. Algoritma tarafından kodlanacak olan her sembol için birer yaprak düğüm, rüçhan sırasına eklenir. 2. Sırada, birden fazla düğüm kaldığı sürece aşağıdaki adımlar döngü halinde yapılır. a. Sıradan, en yüksek rüçhana sahip iki düğüm alınır. (bu düğümlerin en az kullanım sıklığına sahip olduğunu hatırlayınız) b. Yeni bir iç düğüm (internal node) oluşturulup, değer olarak bu alınan iki düğümün toplamı atanır. c. Yeni düğüm ağaca ve sıraya eklenir. 3. Döngü bitip tek düğüm kaldıysa, bu düğüm, kök düğüm yapılır ve algoritma sona erer.
 b. Yeni bir iç düğüm (internal node) oluşturulup, değer olarak bu alınan iki düğümün toplamı atanır. c. Yeni düğüm ağaca ve sıraya eklenir. 3. Döngü bitip tek düğüm kaldıysa, bu düğüm, kök düğüm yapılır ve algoritma sona erer.")
14
ÖRNEK; Bu örnekte aşağıdaki frekans tablosu kullanılacaktır.
Bu tablodan çıkarmamız gereken şudur : Elimizde öyle bir metin dosyası varki "a" karakteri 50 defa, "b" karakteri 35 defa .... "ğ" karakteri 4 defa geçiyor. Amacımız ise her bir karakteri hangi bit dizileriyle kodlayacağımızı bulmak.

15
ÇÖZÜM; 1 - Öncelikle "Huffman Ağacını" ndaki en son düğümleri(dal) oluşturacak bütün semboller frekanslarına göre aşağıdaki gibi küçükten büyüğe doğru sıralanırlar.
 oluşturacak bütün semboller frekanslarına göre aşağıdaki gibi küçükten büyüğe doğru sıralanırlar.")
16
2 - En küçük frekansa sahip olan iki sembolün frekansları toplanarak yeni bir düğüm oluşturulur. Ve oluşturulan bu yeni düğüm diğer varolan düğümler arasında uygun yere yerleştirilir. Bu yerleştirme frekans bakımından küçüklük ve büyüklüğe göredir.

17
3 - 2.adımdaki işlem tekrarlanarak en küçük frekanslı iki düğüm tekrar toplanır ve yeni bir düğüm oluşturulur.

18
4 - 2.adımdaki işlem tekrarlanarak en küçük frekanslı iki düğüm tekrar toplanır ve yeni bir düğüm oluşturulur.Yeni dizimiz aşağıdaki şekilde olacaktır.

19
5 - 2.adımdaki işlem tekrarlanarak en küçük frekanslı iki düğüm tekrar toplanır ve yeni bir düğüm oluşturulur.

20
6 - 2.adımdaki işlem en tepede tek bir düğüm kalana kadar tekrar edilir.Böylece huffman ağacının son hali aşağıdaki gibi olacaktır.

21
7 - Huffman ağacının son halini oluşturduğumuza göre her bir sembolün yeni kodunu oluşturmaya geçebiliriz. Sembol kodlarını oluşturuken Huffman ağacının en tepesindeki kök düğümden başlanır. Kök düğümün sağ ve sol düğümlerine giden dala sırasıyla "0" ve "1" kodları verilir. Sırası ters yönde de olabilir. Bu tamamen seçime bağlıdır. Ancak ilk seçtiğiniz sırayı bir sonraki seçimlerde korumanız gerekmektedir.

22
Dalların kodlarla işaretlenmiş hali aşağıdaki gibi olacaktır.

23
8 - Sıra geldi her bir sembolün hangi bit dizisiyle kodlanacağını bulmaya. Her bir sembol dalların ucunda bulunduğu için ilgili yaprağa gelene kadar dallardaki kodlar birleştirilip sembollerin kodları oluşturulur.

24
Şimdi örneğimizdeki gibi bir frekans tablosuna sahip olan metnin Huffman algoritması ile ne oranda sıkışacağını bulalım : Sıkıştırma öncesi gereken bit sayısını bulacak olursak : Her bir karakter eşit uzunlukta yani 8 bit ile temsil edildiğinden toplam karakter sayısı olan ( ) = 127 ile 8 sayısını çarpmamız lazım. Orijinal veriyi sıkıştırmadan saklarsak 127*8 = 1016 bit gerekmektedir. Huffman algoritmasını kullanarak sıkıştırma yaparsak kaç bitlik bilgiye ihtiyaç duyacağımızı hesaplayalım : 50 adet "a" karakteri için 50 bit, 35 adet "b" karakteri için 70 bit, 20 adet "k" karakteri için 60 bit....4 adet "ğ" karakteri için 20 bite ihtiyaç duyarız. (yukarıdaki tabloya bakınız.) Sonuç olarak gereken toplam bit sayısı = 50*1 + 35*2 + 20*3 + 10*4 + 8*5 + 4*5 = = 280 bit olacaktır.
 = 127 ile 8 sayısını çarpmamız lazım. Orijinal veriyi sıkıştırmadan saklarsak 127*8 = 1016 bit gerekmektedir. Huffman algoritmasını kullanarak sıkıştırma yaparsak kaç bitlik bilgiye ihtiyaç duyacağımızı hesaplayalım : 50 adet a karakteri için 50 bit, 35 adet b karakteri için 70 bit, 20 adet k karakteri için 60 bit....4 adet ğ karakteri için 20 bite ihtiyaç duyarız. (yukarıdaki tabloya bakınız.) Sonuç olarak gereken toplam bit sayısı = 50*1 + 35*2 + 20*3 + 10*4 + 8*5 + 4*5 = = 280 bit olacaktır.")
25
SONUÇ; 1016 bitlik ihtiyacımızı 280 bite indirdik. Yani yaklaşık olarak %72 gibi bir sıkıştırma gerçekleştirmiş olduk. Gerçek bir sistemde sembol frekanslarınıda saklamak gerektiği için sıkıştırma oranı %72’ten biraz daha az olacaktır. Bu fark genelde sıkıştırılan veriye göre çok çok küçük olduğu için ihmal edilebilir.

26
Bu durumda BİLGİSAYAR sözcüğünün sıkıştırılmış hali Bu durumda BİLGİSAYAR sözcüğünün sıkıştırılmış hali dir. Toplamda 30 bit kullanılmıştır. Bu da bize %62,5’luk bir yer kazancı sağlar. dir. Toplamda 30 bit kullanılmıştır. Bu da bize %62,5’luk bir yer kazancı sağlar. Peki bu bitler gerçekten rastgele mi elde ediliyor?

27
Her harfin bit temsilini nasıl elde ederiz?
PAPAĞAN sözcüğündeki harflerin frekans tablosu yukarıdaki gibidir.

28
(i) Daha sonra, her karakteri ve frekansını içeren ağaç düğümleri frekanslarına göre artan sırayla yazılır. (ii) En düşük frekanslı ilk iki düğüm toplanır ve toplanan düğümlerin içerdiği semboller ve toplam frekans bir düğüme yazıldıktan sonra toplanan elemanlar sol ve sağ çocuk olarak bu düğüme eklenir. (iii)En üst seviyedeki düğümler arasında bu işlem devam eder.
 En düşük frekanslı ilk iki düğüm toplanır ve toplanan düğümlerin içerdiği semboller ve toplam frekans bir düğüme yazıldıktan sonra toplanan elemanlar sol ve sağ çocuk olarak bu düğüme eklenir. (iii)En üst seviyedeki düğümler arasında bu işlem devam eder.")
29
(iv) En üst seviyede bir düğüm kaldığında ağaç tamamlanmış olur.
(v) Huffman ağacının oluşması için bit atamalarının da yapılması gerekiyor. Bunun için de, ağaçta sol çocukların bağlandığı bağlara ‘0’, sağ çocukların bağlandığı bağlara da ‘1’ atanır.
 Huffman ağacının oluşması için bit atamalarının da yapılması gerekiyor. Bunun için de, ağaçta sol çocukların bağlandığı bağlara ‘0’, sağ çocukların bağlandığı bağlara da ‘1’ atanır.")
31
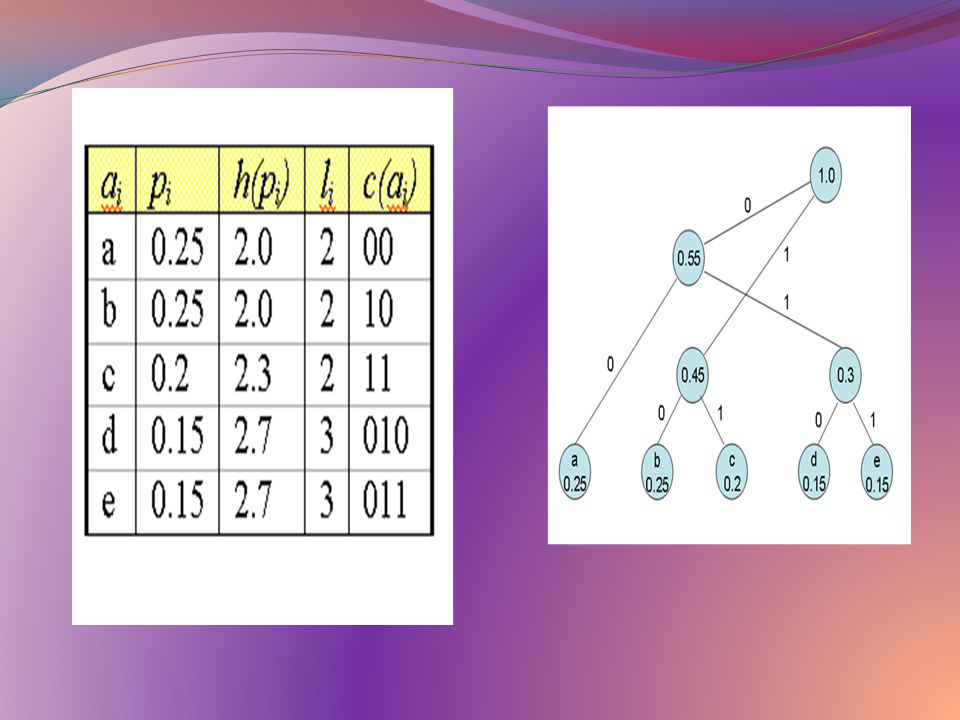
Örnek h(x) = log2(1/P(x))
Ax={ a , b , c , d , e } Px={0.25, 0.25, 0.2, 0.15, 0.15} 1.0 1 0.55 1 0.45 1 0.3 1 a 0.25 b 0.25 c 0.2 d 0.15 e 0.15 00 10 11 010 011

34
Huffman kodu ile sıkıştırılmış katarın eski haline getirilmesi;
Önek ağacı kullanıldığı ve yaprak düğümler harici veri saklanılmadığı için Huffman Ağacında kod sözcüklerinin çözülmesi oldukça kolaydır. Kodlanmış verinin çözülmesi için kök düğümden başlanarak ve her gelen bit’e karşılık kodlanmış veride bir ilerlenerek yaprak düğüme ulaşılır. Yaprak düğüme ulaşıldığında bir sonraki koda geçildiği anlaşılır ve tekrar kök düğümden başlanarak aynı işlem kodlanmış veri bitene kadar tekrarlanır.

35
ÖRNEK; Huffman Kodu ile kodlanmış elimizde bu katarın olduğunu düşünelim; “ ”

36
ÇÖZÜM; Huffman ağacından faydalanarak bu katarın ilk karakterden başlayıp yolları takip ettiğimizde; • 1 -> abfc • 0 -> a (hiç çocuğu yok, köke dön) • 1 -> bfc • 1 -> b (hiç çocuğu yok, köke dön)
 • 1 -> bfc. • 1 -> b (hiç çocuğu yok, köke dön)")
37
Dezavantajları Huffman algoritması az sayıda karakter çeşidine sahip ve büyük boyutlardaki verilerde çok kullanışlı olabilir. Fakat oluşturulan ağacın sıkıştırılmış veriye eklenmesi zorunludur. Bu da sıkıştırma verimini düşürür. Adaptive Huffman (Uyarlanır Huffman) gibi teknikler bu sorunu halletmek için geliştirilmişlerdir.
 gibi teknikler bu sorunu halletmek için geliştirilmişlerdir.")
38
Uyarlanır Huffman Kodlaması
Huffman kodlaması, kodlanacak kaynağın olasılık bilgisine ihtiyaç duyar. Eğer bu bilgi yoksa, Huffman kodlaması iki geçişli bir prosedür haline gelir: ilk geçişte olasılık bilgileri elde edilir, ikinci geçişte kaynak kodlanır. Önceden karşılaşılan sembollerin istatistiği temel alınarak, Uyarlanır (Dinamik) Huffman Kodlaması olarak bilinen yaklaşım ile, Huffman kodlaması tek geçişli hale getirilebilir. Fakat her bir sembol kodlanırken, daha önce kodlanmış olan sembollerin istatistiğini çıkarmak ve bu istatistiğe göre Huffman kodlamasını yapmak çok masraflı olacaktır. Zamanla, daha az hesaplama yaparak uyarlanır kodlama yapabilen birçok farklı yöntem geliştirilmiştir
 Huffman Kodlaması olarak bilinen yaklaşım ile, Huffman kodlaması tek geçişli hale getirilebilir. Fakat her bir sembol kodlanırken, daha önce kodlanmış olan sembollerin istatistiğini çıkarmak ve bu istatistiğe göre Huffman kodlamasını yapmak çok masraflı olacaktır. Zamanla, daha az hesaplama yaparak uyarlanır kodlama yapabilen birçok farklı yöntem geliştirilmiştir.")
39
Bir veri kümesini Huffman tekniği ile sıkıştırabilmek için veri kümesinde bulunan her bir sembolün ne sıklıkta tekrarlandığını bilmemiz gerekir. Örneğin bir metin dosyasını sıkıştırıyorsak her bir karakterin metin içerisinde kaç adet geçtiğini bilmemiz gerekiyor. Dolayısıyla sıkıştırma işlemine geçmeden önce frekans tablosunu çıkarmamız gerekmektedir. Bu yönteme « Statik Huffman Tekniği « de denilmektedir. Diğer bir teknik olan «Dinamik Huffman Tekniği«nde sıkıştırma yapmak için frekans tablosuna önceden ihtiyaç duyulmaz.

40
Metin Sıkıştırma; Özet:Veri sıkıştırmada ana amaç bilgiyi temsil etmek için gerekenden fazla bulunanlari azaltmaktir. Veri sıkıştırmanin tarihini Braille ve Morse kodlama olusturur. Braille kodlama, 1820 yilinda Louis Braille tarafindan körlerin okumasina imkan saglamak için gelistirilmis ve halen günümüzde kullanilmaktadir. Morse kodlama, ilk olarak 1832 yilinda Samuel Morse tarafindan gelistirilmis bir telgraf kodudur.

41
Mors Alfabesi; Mors alfabesi, kısa ve uzun işaretler (nokta ve çizgiler) kullanarak bilgi aktarılmasını sağlayan yöntem. 1832'de telgraf ile ilgilenmeye başlayan Samuel Morse tarafından ,1835 yılında oluşturuldu. 1837'de kullanılmaya başladı. 1840 yılında patent için başvuruldu. İlk hat ABD'de Baltimore, Maryland ile başkent Washington arasında kuruldu. İlk mesaj incilden bir cümleyi içeriyordu, gönderim tarihi 24 Mayıs 1844 idi. Orijinal mors kodu kısa ve uzun sinyallerin kombinasyonunun bir sayıya karşılık gelmesinden oluşmuştu. Her sayı da bir harfe karşılık geliyordu. Asistanı Veil ile bu konu üzerine ortaklaşa çalışmaya başlayan Morse, bir süre sonra Veil'in önerdiği sistemin daha basit olduğuna ikna oldu. Veil'in sisteminde kısa ve uzun sinyallerin yanı sıra duraklamalar da kullanılıyordu. Bu sistem daha sonra Amerikan Mors Kodu olarak isimlendirildi.

42
Mors Kodu; Mors kodu; sesli olarak, radyo sinyallerinin açılıp kapatılmasıyla, telegraf tellerinden geçen elektrik akımıyla, mekanik yolla ya da görsel (ışıkların yanıp sönmesi) gibi çeşitli yollarla iletilebilir. Sistem genel olarak Mors alfabesi olarak adlandırılsa da uygulamada İngiliz alfabesi ve buna bağlı noktalama işaretlerini ifade etmek için iki farklı tür mors kodu kullanılmaktadır. Bunların birincisi olan Amerikan Mors Alfabesi, genellikle telgraf sistemlerinde kullanılırken, Uluslararası Mors Alfabesi ise araları görmezden gelerek sadece kısa ve uzun sinyallere göre çalışır.
 gibi çeşitli yollarla iletilebilir. Sistem genel olarak Mors alfabesi olarak adlandırılsa da uygulamada İngiliz alfabesi ve buna bağlı noktalama işaretlerini ifade etmek için iki farklı tür mors kodu kullanılmaktadır. Bunların birincisi olan Amerikan Mors Alfabesi, genellikle telgraf sistemlerinde kullanılırken, Uluslararası Mors Alfabesi ise araları görmezden gelerek sadece kısa ve uzun sinyallere göre çalışır.")
43
Mors alfabesi basitçe iki çeşit sinyalin (kısa ve uzun sinyal) farklı kombinasyonlarının harfleri, sayıları ya da noktalama işaretlerini oluşturduğu bir haberleşme dilidir. Genellikle elektrik ya da radyo sinyali kullanılarak uzak bir noktaya yazılı bir metnin ulaştırılmasında kullanılır. Kısa ve uzun sinyallerin dışında aralardaki sessizlikler de anlam taşımaktadır. Kısa aralık harfler arasında, orta uzunlukta aralık kelimeler arasında ve uzun aralıklar ise cümleleri birbirinden ayırmakta kullanılır.

45
mors koduna çevrilmiş hali
VEDAT SİAP dilay yıldırım ezgi demir damla aygül

46
Mors Kodu Kullanmanın Avantajları;
Mors kodu radyo cihazları ile yayınlanmak istendiği zaman diğer radyo bazlı iletişim cihazlarından daha basit bir düzenek kullanmak yeterlidir. Yüksek cızırtılı, düşük frekanslı ortamlarda bile kullanılabilmektedir. Bir diğer avantajı da daha düşük bant genişliğine ihtiyaç duymasıdır. Örneğin sesli iletişimde Hz aralığı kullanılırken, Mors kodu için tek taraflı 4000 Hz yeterli olmaktadır. Mors alfabesinin geliştirilerek kullanıldığı bir diğer alan ise Q kodlarıdır. Amatör radyocular, sık kullandıkları mesajları kısaltıp Q kodları haline çevirmişlerdir. Radyo frekansı üzerinden haberleşmelerinde bu Q kodlarını kullanırlar. Bunun dışında mors alfabesi ile haberleşme yazılı mesajlaşmadan daha hızlıdır. Hatta bazı cep telefonu şirketleri mors alfabesi uyumlu cep telefonu üretmektedir.

47
Mors Alfabesi Haritası;

48
Haritanın Kullanımı; Mors kodlarını dinlerken kalemi en üstteki noktaya yerleştirin. Sinyali dinlemeye başlayın ve sinyalin uzunluğuna göre kaleminizi alt kademeye indirin. Kısa sinyallerde önce aşağı sonra sola, Uzun sinyallerde ise önce aşağı sonra da sağa doğru harekete ediniz.

49
Örneğin BİR UZUN İKİ KISA SİNYAL için
İlk sinyal olan uzun sinyali duyunca kalemi aşağı ve sağa doğru kaydırınız, Şu anda T harfinde olmanız gerekmektedir. Daha sonra iki kısa sinyal için iki kere aşağı ve sola doğru gidilmesi gerekir. Yani önce N'ye sonra da D harfine gelinmelidir. Bir uzun iki kısa sinyalin karşılığı olan D harfi bir kenara not edilir ve sonraki sinyal beklenir.

50
Günümüze Doğru Mors Alfabesi;
1991 yılında Amerika Birleşik Devletleri'nde FCC'nin(İletişim ve yayıncılıkta hava dalgalarının kullanılmasını kontrol eden hükümet dairesi.)Amatör Radyocu lisansını alabilmek için dakikada 5 kelimeyi Mors alfabesi ile alıp, göndermek gerekliydi. 2000 yılına kadar amatör radyo lisanslarının en üst seviyesi olan extra class için bu rakam 20 kelimeye kadar çıkıyordu yılından itibaren bu lisans için de 5 kelime yeterli sayıldı. 2003 yılında Dünya Radyo İletişimcileri Konferansı'nda alınan karar gereğince Uluslararası Mors Alfabesini bilmek amatör telsizci sertifikası alma koşulu olmaktan çıkarıldı.
Amatör Radyocu lisansını alabilmek için dakikada 5 kelimeyi Mors alfabesi ile alıp, göndermek gerekliydi yılına kadar amatör radyo lisanslarının en üst seviyesi olan extra class için bu rakam 20 kelimeye kadar çıkıyordu yılından itibaren bu lisans için de 5 kelime yeterli sayıldı yılında Dünya Radyo İletişimcileri Konferansı nda alınan karar gereğince Uluslararası Mors Alfabesini bilmek amatör telsizci sertifikası alma koşulu olmaktan çıkarıldı.")
51
DİNLEDİĞİNİZ İÇİN TEŞEKKÜR EDERİZ…

Benzer bir sunumlar






>")

>")






>")





>")
