Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
Yapısal Eşitlik Modellemesi
Zafer Çepni Hacettepe Üniversitesi Mersin, 2010

2
Temel Kaynaklar Kline, 2005 Brown, 2006
İçerikteki tüm şekiller ve referanslar bu iki temel kaynaktan alınmıştır.

3
İçerik Veri Kontrolü Açımlayıcı Faktör Analizi Yol Analizi
Doğrulayıcı Faktör Analizi Yapısal Eşitlik Modeli

4
Veri Kontrolü – Uç Değerler
Uç Değerler Likert tipi veri setleri için uç değerler hemen her zaman veri girişi hatasından kaynaklanır. Veri girişi esnasında olabilecek hatalar ise frekans dağılımları göz önüne alınarak bulunarak düzeltilebilir. SPSS ile de PRELIS ile de mümkün olsa da SPSS ile veya Excel benzeri bir yazılımla veri yönetimi daha kolay olabilir.

5
Kayıp Veriler Kayıp veriler modelin sonuç bulamamasına sebep olabilir. Ayrıca LISREL kayıp veriler ile sonuç bulduğunda da model veri uyumu indekslerinin tamamını üretmez. Kayıp veriler için kullanılan geleneksel yöntemler: İkili silme veya tekli silme (pairwise ve listwise). Veriler “pairwise” silindiğinde her bir kovaryans farklı sayılarda kişi üzerinden hesaplanır. Bu durum kovaryans matrisinde mantıklı olmayan ve tersi alınamayan bir kovaryans matrisi oluşmasına yol açabilir (nonpozitive definite hatası).
. Veriler pairwise silindiğinde her bir kovaryans farklı sayılarda kişi üzerinden hesaplanır. Bu durum kovaryans matrisinde mantıklı olmayan ve tersi alınamayan bir kovaryans matrisi oluşmasına yol açabilir (nonpozitive definite hatası).")
6
Kayıp Veriler Örneğin, rxw=0,70 ve ryw=0,80 ise rxy değeri 0,13 ile 0,99 arasında olmalıdır. Eğer pairwise silme yapılırsa rxy bu aralık dışında değerler alabilir; mesela -0,12. Bu durumda LISREL kestirim yapamaz ve “nonpozitive definite matrix” uyarısı verir. Listwise silme işleminde ise bir birey tek bir maddeye cevap vermese dahi veri setinden o birey kaybedilir. Bu da örneklem genişliğinde büyük kayıplara yol açabilir. Zaten geniş örneklemlere ihtiyaç duyan Yapısal Eşitlik Modeli (Structural Equation Modeling, SEM) analizlerinde örneklem genişliğinden ödün vermek parametrelerin standart hatalarının çok geniş olmasına yol açabilir.
 analizlerinde örneklem genişliğinden ödün vermek parametrelerin standart hatalarının çok geniş olmasına yol açabilir.")
7
Kayıp Veriler Kayıp veri için önerilen yöntem: Multiple Imputation. Datanın ve kayıp datanın dağılımına göre farklı noktalardaki kayıp verilere farklı veriler atar. Kayıp veri konusunda kullanılabilecek temel referans: (Allison, 2003).
.")
8
Normallik Çok değişkenli normallik sayıltısı en çok olabilirlik (Maximum Likelihood, ML) kestirimler için gereklidir. LISREL ile bu sayıltının formal testi yapıldığında hemen hemen her data seti bu testten “kalır.” Ancak tek değişkenli olarak, uç değerler, çarpıklık ve basıklık incelendiğinde çok boyutlu değişkenlik kaynaklı sorun yaratacak durumlar çözülebilir.
 kestirimler için gereklidir. LISREL ile bu sayıltının formal testi yapıldığında hemen hemen her data seti bu testten kalır. Ancak tek değişkenli olarak, uç değerler, çarpıklık ve basıklık incelendiğinde çok boyutlu değişkenlik kaynaklı sorun yaratacak durumlar çözülebilir.")
9
Normallik Uç değerler frekans dağılımlarına bakarak görülebilir. Bu uç değerler Likert tipi verilerde hemen hemen her zaman hatalı veri girişinden kaynaklanır. Örneğin 5-li Likert tipi data içinde yer alan 55 puanlar aslında 5 yazarken olmuştur. Kabul edilebilir çarpıklık değeri (-3, +3) aralığı alınabilir. Kabul edilebilir basıklık için 10’dan küçük değerler alınabilir. Basıklık değerleri 20’yi geçtikten sonra problem teşkil edebilir.
 aralığı alınabilir. Kabul edilebilir basıklık için 10’dan küçük değerler alınabilir. Basıklık değerleri 20’yi geçtikten sonra problem teşkil edebilir.")
10
Normallik PRELIS’te değişken türü continuous (sürekli) seçildikten sonra değişkenlere ait min, max, skewness, kurtosis değerleri görülebilir. Çarpık dağılımlara sahip değişkenler Tabachnick ve Fidell (2007) tarafından açıklanan transformasyonlarla normale yaklaştırılmaya çalışılabilir. Ancak bazı dağılımlar hangi transformasyona tabi tutulursa tutulsun normale yaklaşmayacaktır.
 seçildikten sonra değişkenlere ait min, max, skewness, kurtosis değerleri görülebilir. Çarpık dağılımlara sahip değişkenler Tabachnick ve Fidell (2007) tarafından açıklanan transformasyonlarla normale yaklaştırılmaya çalışılabilir. Ancak bazı dağılımlar hangi transformasyona tabi tutulursa tutulsun normale yaklaşmayacaktır.")
11
Normallik Normallik sayıltısından belirgin şekilde sapmalar olduğunda Robust Maximum Likelihood (MLM) veya Ağırlıklandırılmış En Küçük Kareler (Weighted Least Squares, WLS) kullanılmalıdır. Bu yöntemlerin kullanılması için LISREL asimtotik kovaryans matrislerine ihtiyaç duyar. Bu matrisler PRELIS aracılığı ile oluşturulup ardından gelen analizlerde kullanılır.
 veya Ağırlıklandırılmış En Küçük Kareler (Weighted Least Squares, WLS) kullanılmalıdır. Bu yöntemlerin kullanılması için LISREL asimtotik kovaryans matrislerine ihtiyaç duyar. Bu matrisler PRELIS aracılığı ile oluşturulup ardından gelen analizlerde kullanılır.")
12
Normallik MLM kestirim yöntemleri metodunda yer almasa da asimtotik kovaryanslar matrisi üzerinden ML ile kestirim yapıldığında SBχ2 ve buna uygun hata kestirimleri vererek MLM’nin sonuçlarının okunmasını sağlar. MLM kullanıldığında modellerin kıyaslamaları için χ2(fark) testleri normal χ2(fark) testleri kadar basit değildir. MLM ile kestirimi yapılan modellerin kıyaslanması için uygun prosedürler normalde kullanılacaklardan farklıdır (Brown, 2006, p. 385).
 testleri normal χ2(fark) testleri kadar basit değildir. MLM ile kestirimi yapılan modellerin kıyaslanması için uygun prosedürler normalde kullanılacaklardan farklıdır (Brown, 2006, p. 385).")
13
Normallik WLS yöntemi uygun çalışması için çok geniş örneklemlere ihtiyaç duymaktadır. Daha küçük örneklem genişliklerinde ise yanlı kestirimler yaptığı gösterilmiştir. Bu nedenle WLS yerine Robust Maximum Likelihood (MLM) tercih edilebilmektedir. Sonuç olarak, araştırmacıların normallik sayıltısından büyük sapmalar göstermeyecek veri setleri elde etmeye çalışmaları yararlarına olacaktır.
 tercih edilebilmektedir. Sonuç olarak, araştırmacıların normallik sayıltısından büyük sapmalar göstermeyecek veri setleri elde etmeye çalışmaları yararlarına olacaktır.")
14
Madde Parselleri Normallik sayıltısının madde bazında yeterli kategori olmaması sebebiyle sağlanmadığı durumlarda maddelerin gruplanarak madde parselleri ile analiz yapılmasını öneren araştırmacılar olmuştur (Yuan, Bentler, & Kano, 1997).
.")
15
Madde Parselleri Hem normallik sayıltısının sağlanması olasılığını artırdığı hem de daha basit modeller kurulmasına olanak tanıdığı için madde parselleri geçmişte önerilse de her maddenin tek başına analize dahil edildiği modellerden daha iyi sonuçlar vermediği gösterilmiştir (Hau & March, 2004). Bu nedenle madde parsellerinin kullanımı gitgide azalmaktadır. Madde parselleme yerine, WLS ve MLM gibi normallik gerektirmeyen kestirme yöntemlerine daha çok bir eğilim görülmektedir.
. Bu nedenle madde parsellerinin kullanımı gitgide azalmaktadır. Madde parselleme yerine, WLS ve MLM gibi normallik gerektirmeyen kestirme yöntemlerine daha çok bir eğilim görülmektedir.")
16
Çoklu bağlantılılık Çoklu bağlantılılık (multicollinearity), tersi alınamayan kovaryans matrisinin yol açtığı nonpositive definite matrix hatasının bir başka sebebidir. Değişkenler arasında 0,85’den fazla korelasyon olması ile kendini gösterir. Eğer bu şekilde değişkenler varsa bu değişkenlerden birisi analiz dışında bırakılarak veya toplanarak bu sorun çözülebilir.
, tersi alınamayan kovaryans matrisinin yol açtığı nonpositive definite matrix hatasının bir başka sebebidir. Değişkenler arasında 0,85’den fazla korelasyon olması ile kendini gösterir. Eğer bu şekilde değişkenler varsa bu değişkenlerden birisi analiz dışında bırakılarak veya toplanarak bu sorun çözülebilir.")
17
Çoklu bağlantılılık Kovaryans matrisinin determinantının pozitif olup olmadığını görmek için temel bileşenler analizi yapılıp özdeğerler incelenebilir. Tüm özdeğerler sıfırdan büyükse matrisin tersi alınabiliyordur ve nonpositive definite hatasının bir kaynağı elenmiş olur.

18
Değişenlerin varyansları
Değişenlerin varyansları arasındaki farkların çok büyük olması modelin parametrelerinin kestirimindeki iteratif sürecin işleyişini kötü etkileyebilir. Bu durumda modele dair parametre kestirimlerinin yer alacağı bir sonuç bulunamaz (model does not converge hatası). Değişkenlerin varyansı oranlandığında 10’u geçmemesi önerilir. Eğer böyle bir durum varsa varyansı küçük olan değişken bir sabit katsayı ile çarpılarak varyansı o sayı oranında artırılır.
. Değişkenlerin varyansı oranlandığında 10’u geçmemesi önerilir. Eğer böyle bir durum varsa varyansı küçük olan değişken bir sabit katsayı ile çarpılarak varyansı o sayı oranında artırılır.")
19
Güvenirlik SEM, ölçme hatasını modele entegre etmektedir. Ancak bu durum, düşük güvenirlik için bir çare olduğu anlamına gelmez. Kullanılan ölçme araçlarının ürettikleri puanların güvenirliklerinin istenen düzeyde olması beklenir. Ölçme araçlarını daha önce kullanan araştırmacıların buldukları güvenirlik katsayıları aynı ölçme araçlarını kullanan diğer araştırmacıların da aynı sonuçları bulacağını garantilemez. Dolayısıyla, her araştırmacı, kendi data setinden hesaplanan güvenirlik katsayılarını rapor etmelidir.

20
Açımlayıcı Faktör Analizi
Temel bileşenler analizi, ölçek geliştirme amacıyla kullanılmamalı, bu amaç için common factor analysis tercih edilmelidir (Floyd & Widaman, 1995). Likert tipi data (5’li – 7’li) eşit aralıklı veya yarı eşit aralıklı (quasi-interval) olarak alınıp faktör analizine [ve diğer parametrik analizlere] tabi tutulabilir (Floyd & Widaman, 1995). Çok değişkenli normallik sadece Maximum Likelihood ile parametre kestirimi yapılırken önemlidir. MINRES, veya Least Squares ile faktör analizi yaparken çok değişkenli normallik ihtiyacı yoktur (Floyd & Widaman, 1995).
. Likert tipi data (5’li – 7’li) eşit aralıklı veya yarı eşit aralıklı (quasi-interval) olarak alınıp faktör analizine [ve diğer parametrik analizlere] tabi tutulabilir (Floyd & Widaman, 1995). Çok değişkenli normallik sadece Maximum Likelihood ile parametre kestirimi yapılırken önemlidir. MINRES, veya Least Squares ile faktör analizi yaparken çok değişkenli normallik ihtiyacı yoktur (Floyd & Widaman, 1995).")
21
Minimum örneklem genişliği
Örneklem büyüklüğü için öneriler: Madde başına 5 kişi, en az 200 (Gorsuch, 1983) Madde başına 10; en az 100 (Streiner, 1994)
 Madde başına 10; en az 100 (Streiner, 1994)")
22
Kaç boyut? Boyut sayısına karar verirken özdeğeri 1’in üzerinde olan faktör sayısı alınmamalıdır (Floyd & Widaman, 1995). Bu yöntem, çoğu zaman olması gerekenden çok sayıda faktör üretmektedir (Zwick & Velicer, 1986). Bazı özel durumlarda da daha az faktör ürettiği gösterilmiştir (Cliff, 1988).
. Bu yöntem, çoğu zaman olması gerekenden çok sayıda faktör üretmektedir (Zwick & Velicer, 1986). Bazı özel durumlarda da daha az faktör ürettiği gösterilmiştir (Cliff, 1988).")
23
Kaç boyut? Boyut sayısına karar vermek için Screeplot göz önüne alınmalıdır. Olası boyut sayılarına dair çözümler ayrı ayrı ele alınmalı ve en uygun olan seçilmelidir (Floyd & Widaman, 1995).
.")
24
Madde sayısı Bir boyuttaki madde sayısı 3’ten az olmamalıdır (Comrey, 1988). Ancak zaten uygun ölçüde güvenirlik elde etmek için bu sayının üzerine çıkmak gerekecektir.
. Ancak zaten uygun ölçüde güvenirlik elde etmek için bu sayının üzerine çıkmak gerekecektir.")
25
Döndürme Ölçme araçlarının faktörleri arasındaki korelasyonların sıfır olması şartı yoktur. Hatta toplam puan vermesi beklenen ölçme araçlarında bu korelasyonların çok düşük olması istenmez. Dolayısıyla, varimax yerine oblique [örneğin promax] döndürme tercih edilmelidir. Zaten faktörler arası korelasyonlar sıfır olacaksa oblique döndürme sonucunda da sıfır çıkabilir (Floyd & Widaman, 1995).
.")
26
Açımlayıcı faktör analizinde faktörlerin açıkladığı varyans %50 ve üzeri olması önerilmiştir (Streiner, 1994). Faktör yüklerinin 0,30’un üzerinde olması istenir (Floyd & Widaman, 1995). Faktör puanları için ağırlıklandırılmış toplamlara gerek yoktur, madde puanları toplamı da iş görür (Gorsuch, 1983; Floyd & Widaman, 1995).
. Faktör puanları için ağırlıklandırılmış toplamlara gerek yoktur, madde puanları toplamı da iş görür (Gorsuch, 1983; Floyd & Widaman, 1995).")
27
Açımlayıcı faktör analizi rapor edilirken faktör yüklerinden sadece 0,30’un üzerindekileri rapor etmek uygun değildir, hepsini vermek gerekir. Okumayı kolaylaştırmak için esas faktör yükü kalın punto ile yazılabilir (Floyd & Widaman, 1995). Metod etkisi ile faktörlerce açıklanamayan kovaryanslar gösteren maddeler, açımlayıcı faktör analizinde farklı boyutlar gibi görünme eğilimindedir. Bu tür durumlarda hataların korelasyonuna izin veren doğrulayıcı faktör analizleri kullanılmalıdır.
. Metod etkisi ile faktörlerce açıklanamayan kovaryanslar gösteren maddeler, açımlayıcı faktör analizinde farklı boyutlar gibi görünme eğilimindedir. Bu tür durumlarda hataların korelasyonuna izin veren doğrulayıcı faktör analizleri kullanılmalıdır.")
28
Rapor edilmesi gerekenler
Temel bileşenler analizinin mi faktör analizinin mi yapıldığı (Ölçek geliştirme için faktör analizi yapmak gerekiyor.) Paylaşılan varyans kestirimleri Extraction method (Normallik sağlanabiliyorsa ML; sağlanamıyorsa MINRES [SPSS için Least Squares] seçilmelidir.) Faktör sayısının belirlenmesi için hangi yöntemin/kriterin kullanıldığı
 Paylaşılan varyans kestirimleri Extraction method (Normallik sağlanabiliyorsa ML; sağlanamıyorsa MINRES [SPSS için Least Squares] seçilmelidir.) Faktör sayısının belirlenmesi için hangi yöntemin/kriterin kullanıldığı")
29
Rapor edilmesi gerekenler
Özdeğerler, döndürme öncesi faktörlerin açıkladığı varyans oranları Döndürme yöntemi (Ölçek geliştirmede oblique [promax] seçilmeli zira faktörlerin aralarında korelasyon göstermesi istenir.) Döndürülmüş faktör yüklerinin tamamı (Sadece 0,30’un üzerindekiler değil.) Faktörler arasındaki korelasyonlar Döndürülme sonrası faktörler tarafından açıklanan varyans oranı
 Döndürülmüş faktör yüklerinin tamamı (Sadece 0,30’un üzerindekiler değil.) Faktörler arasındaki korelasyonlar Döndürülme sonrası faktörler tarafından açıklanan varyans oranı")
30
Yapısal Eşitlik Modellemesi Temel Adımları
Yol Analizi (PA), Doğrulayıcı Faktör Analizi (CFA) ve Yapısal Eşitlik Modellemesi (SEM) uygulamaları için geçerli olan adımlar şu şekilde sıralanabilir: Modelin oluşturulması Modelin serbestlik derecesinin (df) bulunması (df < 0 iken model kestirilemez) Gerekli minimum örneklem genişliğinin hesaplanması Veri toplanması, kontrolü gerekiyorsa kayıp verilerin doldurulması
, Doğrulayıcı Faktör Analizi (CFA) ve Yapısal Eşitlik Modellemesi (SEM) uygulamaları için geçerli olan adımlar şu şekilde sıralanabilir: Modelin oluşturulması. Modelin serbestlik derecesinin (df) bulunması (df < 0 iken model kestirilemez) Gerekli minimum örneklem genişliğinin hesaplanması. Veri toplanması, kontrolü gerekiyorsa kayıp verilerin doldurulması.")
31
Temel Adımlar Modelin çalıştırılması
Model veri uyumunun irdelenmesi (sağlanmazsa modelin değiştirilmesine geçilir.) Parametrelerin yorumlanması Denk modeller arasında neden araştırmacının önerdiği modelin uygun olduğunun veya seçildiğinin irdelenmesi
 Parametrelerin yorumlanması. Denk modeller arasında neden araştırmacının önerdiği modelin uygun olduğunun veya seçildiğinin irdelenmesi.")
32
Temel Adımlar Model veri uyumu sağlanamazsa veya Heywood vakaları [negatif hata varyansları veya 1’i geçen standart katsayılar] görülürse veya bazı parametreler anlamsız görülürse modelin literatürden destekli ampirik, teorik veya mantıksal gerekçeler ile yeniden oluşturulması Model veri uyumu sağlandıktan, Heywood vakaları gibi sorunların olmadığını görüldükten ve model parametrelerinin yorumlanması Bulguların uygun şekilde rapor edilmesi

33
Yol Analizi

34
Bağımsız değişkenler (LISREL dili ile X değişkenleri): Exercise ve Hardiness
Bağımlı değişkenler (LISREL dili ile Y değişkenleri): Fitness, Stress ve Illness Fitness ve Stress aracı değişkenler olarak adlandırılır. Aracı değişkenler de LISREL modellerinde Y değişkeni olarak atanır.
: Fitness, Stress ve Illness. Fitness ve Stress aracı değişkenler olarak adlandırılır. Aracı değişkenler de LISREL modellerinde Y değişkeni olarak atanır.")
35
Model birden çok çoklu regresyonu bir şekle uyarlanması olarak da görülebilir. Düz oklar yol katsayılarını gösteriyor ve regresyon katsayıları olarak yorumlanıyor. Standartlaştırılmış çözümlerde ise korelasyon katsayıları olarak görülebilir. Yalnız datadaki iki değişken arasındaki basit korelasyondan ziyade çoklu regresyon katsayılarındaki gibi diğer yordayıcı değişkenler sabitken aradaki korelasyonu gösterir.

36
Bu durum, iki değişken arasındaki var olan basit korelasyonun başka değişkenlerden mi kaynaklanıp kaynaklanmadığının da test edilmesine olanak tanır.

37
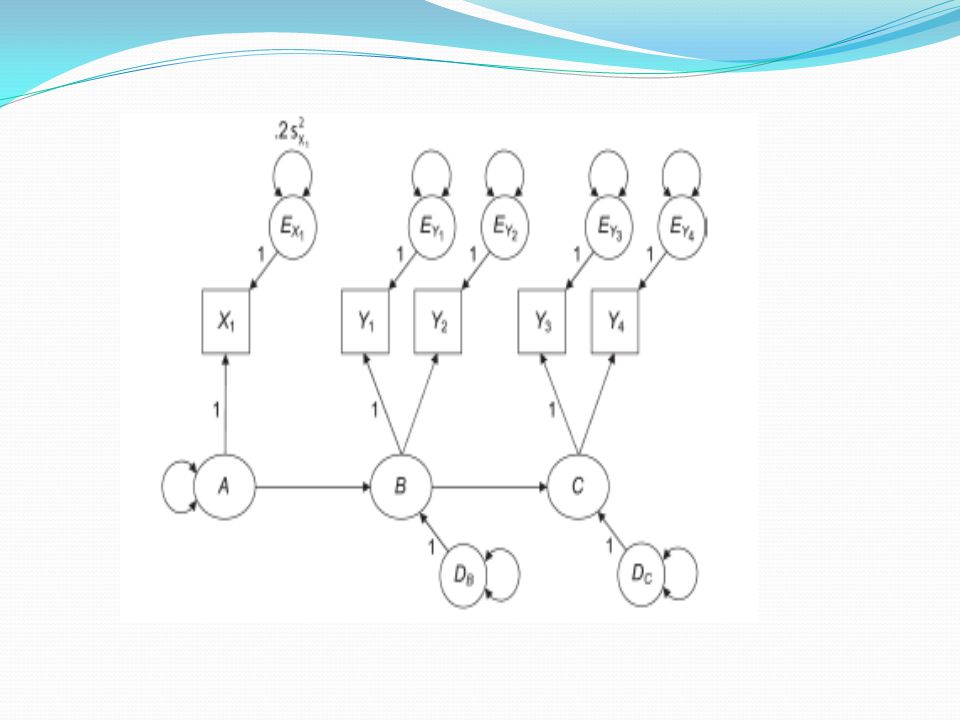
Şekildeki X değişkenlerinin üzerinde çizilmiş yuvarlak biçimli oklar onların varyansını temsil ediyor. Exercise ile Hardiness arasındaki bombeli ok nedensellik iddiası olmayan [açıklanmayan] ilişkiyi gösteriyor. Daire içindeki D’ler disturbance yani hata varyansını gösteriyor. Çoklu regresyondaki kestirim hatasını (residual) temsil ediyor. Örneğin, Stress değişkenindeki varyansı Exercise, Hardiness ve Fitness değişkenleri yorduyor.
 temsil ediyor. Örneğin, Stress değişkenindeki varyansı Exercise, Hardiness ve Fitness değişkenleri yorduyor.")
38
Stress değişkeninin bu yordama ile açıklanan varyansı dışında kalan varyans model tarafından açıklanamıyor ve bu hata varyansı olarak modelde yerini alıyor. Hata varyansları gözlenen değişkenler olmadığından diğerleri gibi dikdörtgen içinde değil daire içinde gösteriliyor. Hata varyansları gözlenen değişkenler olmadıkları için kendiliğinden gelen bir varyansları da yok. Bu durum, onları ölçeksiz kılıyor. Bu nedenle ölçeklenmeleri gerekiyor.

39
Gizil değişkenlerin ölçeklenmesi
Gizil değişkenleri ölçeklemenin bir yolu onların kestirdiği bir gösterge (gözlenen değişken) ile aralarındaki yol katsayısını 1 kabul etmektir. Gizil değişkenleri ölçeklemenin ikinci yolu da varyanslarını 1 kabul etmektir. LISREL varsayılan seçenek olarak bunu yapmaktadır.
 ile aralarındaki yol katsayısını 1 kabul etmektir. Gizil değişkenleri ölçeklemenin ikinci yolu da varyanslarını 1 kabul etmektir. LISREL varsayılan seçenek olarak bunu yapmaktadır.")
40
Hata varyansları, LISREL grafiklerinde yuvarlak içinde değil kenarda boşta duran sayılar olarak gösterilirler.

42
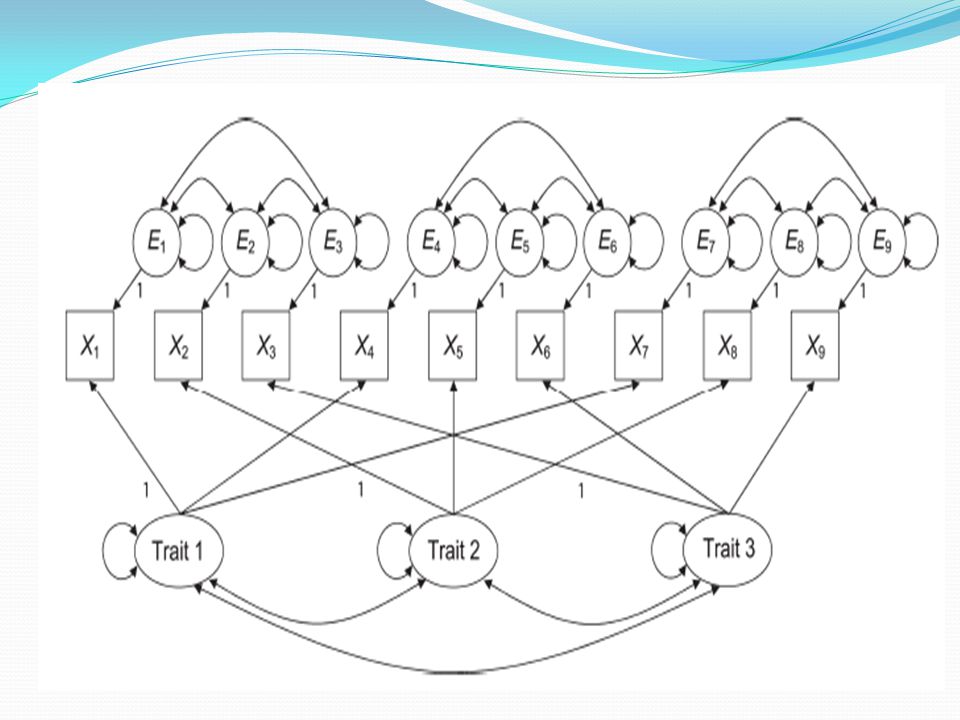
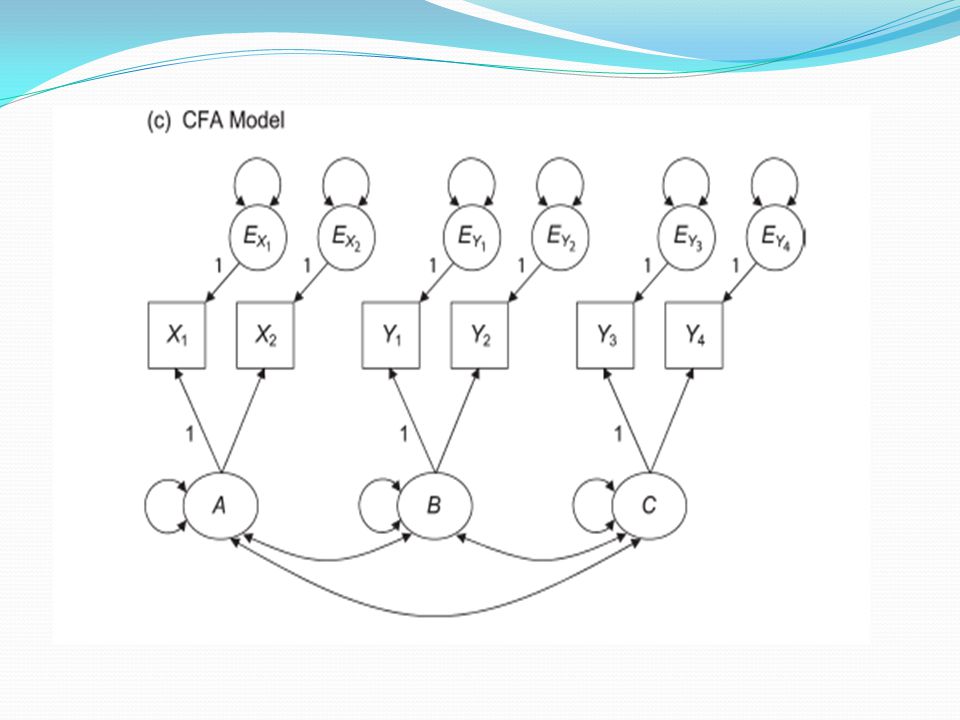
Doğrulayıcı faktör analizi

43
Doğrulayıcı faktör analizi modelleri birer ölçme modelidir.
Şekildeki A1 – A5 ve C1 – C5 gözlenen değişkenleri alttaki iki gizil değişkenin birer göstergesidir (indicator).
.")
44
Ölçme modelleri iki tür çalışmada kullanılmaktadır:
Ölçme araçlarının psikometrik özelliklerinin incelenmesinde ve Gizil değişkenler arasındaki ilişkilerin incelendiği yapısal modellerin test edildiği SEM çalışmalarının ön basamağı olarak ölçme modelinin doğrulanmasında.

45
Ölçme araçlarının psikometrik özelliklerinin incelendiği çalışmalarda gizil değişkenler bir ölçme aracının boyutlarını temsil eder. Göstergeler de bu boyutlara ait maddelerdir.

46
Ölçme modeli testini, yapısal eşitlik modellerinin test edilmesinin ilk basamağı olarak kullanan çalışmalarda ise gizil değişkenler çalışmada yer alan tüm esas değişkenleri gösterir. Aynı ölçme aracı içinde bulunmak zorunda değillerdir. Göstergeler ise nadiren ölçme aracının maddeleri olur. Çoğunlukla bu çalışmalarda göstergeler, ölçme araçlarının alt boyutlarından elde edilen toplam puanlar veya ölçme araçlarının tamamından alınan toplam puanlar olur.

47
Göstergelerin bu şekilde alınması için kullanılan ölçme araçlarının psikometrik kalitelerinin daha önceki çalışmalarla gösterilmiş olması beklenir. Dolayısıyla, yukarıdaki şekilde A1 – A5 aynı genel kavramı ölçen bir ölçme aracının alt boyutlarından alınan puanlar olabileceği gibi, aynı kavramı ölçmekte kullanılan farklı ölçme araçlarından alınan puanlar da olabilir.

48
Şekilde hata varyansları, göstergelerin faktör yükleri, faktör varyansları ve faktör kovaryansı (standart çözüm için faktörler arası korelasyonu) görülmektedir. Yukarıdaki şekilde A1 ve C1 gizil değişkenleri ölçeklemek için kullanılmışlardır.

50
Uygun bir ölçme modelinde faktör yüklerinin yüksek, hata varyanslarının düşük, faktör korelasyonlarının 0,85’den küçük olması beklenir. Faktör korelasyonlarının 0,85’i geçmesi ise aslında daha az faktörle model veri uyumunun sağlanabileceğini ve varlığı iddia edilen faktörlerin birbirinden ayrı kavramlar olmadıkları düşünülür.

51
Bir toplam puan vermesi hedeflenen ölçme araçları için bu faktör korelasyonunun sıfır dolaylarına inmemesi beklenir. Zira sıfıra yakın korelasyon gösteren faktör puanlarının toplanması anlamlı olmayacaktır.

52
Hem PA hem de CFA’da amaç gözlenen değişkenler arasındaki ilişkileri gösteren kovaryans matrisindeki değerleri daha az parametre kullanarak yeniden oluşturmaktır. Örneğin B5 ile B4 arasındaki mevcut data setindeki korelasyon değerine (0,12) karşılık modelin öngördüğü değer izleme kuralları ile 0,34 * 0,43 = 0,15 olarak bulunur.
 karşılık modelin öngördüğü değer izleme kuralları ile 0,34 * 0,43 = 0,15 olarak bulunur..")
53
Modelin öngördüğü korelasyon bazen data setindeki korelasyondan büyük bazen de küçük olur. Modelin öngördüğü korelasyonlar (kovaryanslar) data setindeki veriye ne kadar yaklaşırsa o ölçüde yüksek model veri uyumu sağlanmış olur. (daha ileride S ve ∑ matrisleri olarak geçecek)
 data setindeki veriye ne kadar yaklaşırsa o ölçüde yüksek model veri uyumu sağlanmış olur. (daha ileride S ve ∑ matrisleri olarak geçecek).")
54
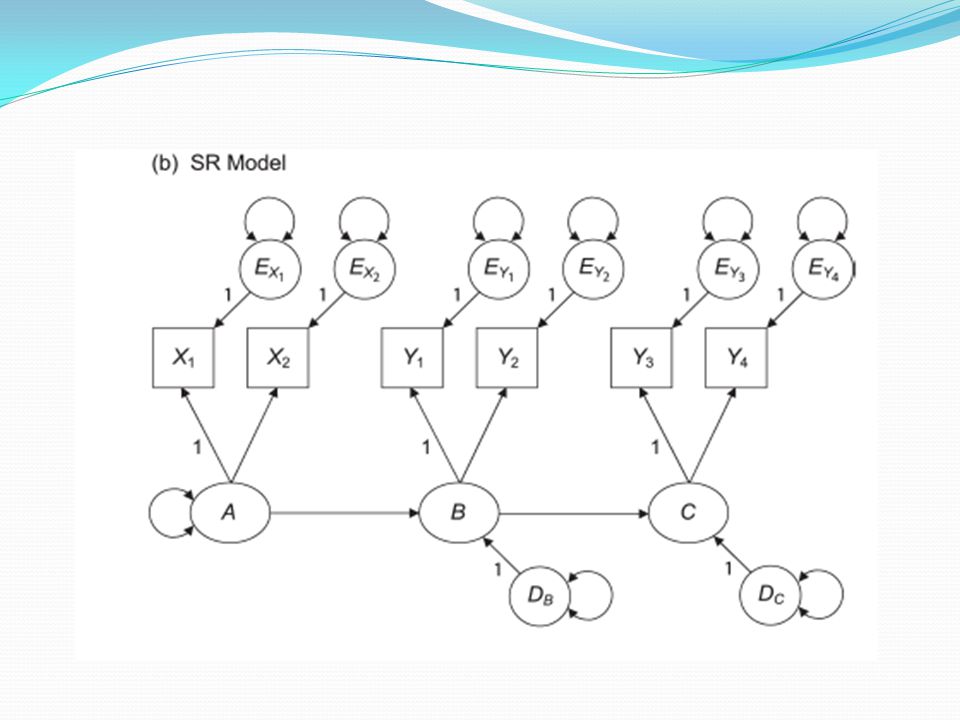
Yapısal Eşitlik Modelleri
Hem ölçme modeli hem de gizil değişkenler arasında yol katsayıları bulunan modellerdir. Ölçme modelinden farklı olarak, sadece faktörler arasında ilişkiler olduğunu değil, bu ilişkilerin doğrudan mı dolaylı mı olduğunu veya yönlerini de belirtir.

56
Şimdiye kadar bahsedilen SEM uygulamalarında analize tabi tutulan öğe genellikle gözlenen değişkenlere ait kovaryans matrisidir. Bu matrise bir kovaryans yapısı denir. (Korelasyonlar matrisi analize tabi tuutlduğunda tüm değişkenler standartlaştırılmış olacaktır.) Daha ileri uygulamalarda kovaryanslar yanında ortalamalar da analize tabi tutularak SEM uygulamaları yapılabilir.
 Daha ileri uygulamalarda kovaryanslar yanında ortalamalar da analize tabi tutularak SEM uygulamaları yapılabilir.")
57
Bu nedenle SEM tekniklerinin sadece korelasyonel çalışmalarda kullanılacağı düşünülmemelidir. Farklı grupların (örneğin deney, kontrol ve plasebo gruplarının) gizil değişkenler üzerindeki ortalamalarının birbiriyle kıyaslanması, gizil değişken üzerinde bireylerin zaman içinde gelişmelerinin izlenmesi gibi deneysel veya boylamsal çalışmaların verilerinin analizi için de SEM kullanılabilir. Bu sunuda ortalama yapıları yer almayacaktır.
 gizil değişkenler üzerindeki ortalamalarının birbiriyle kıyaslanması, gizil değişken üzerinde bireylerin zaman içinde gelişmelerinin izlenmesi gibi deneysel veya boylamsal çalışmaların verilerinin analizi için de SEM kullanılabilir. Bu sunuda ortalama yapıları yer almayacaktır.")
58
YOL ANALİZİ DETAYLARI

59
Korelasyon ve nedensellik
İki değişken arasında korelasyonun var olması veya regresyon katsayısının anlamlı bulunması, değişkenlerden birinin diğerine yol açtığı anlamına gelmez. İki değişken arasındaki ilişki esasen üçüncü bir değişkenin her ikisine birden yol açmasından da kaynaklanabilir. Esas sebep olan değişken kontrol edildikten sonra diğer iki değişken arasında hesaplanacak olan kısmi korelasyonun sıfıra yaklaştığı görülebilir.

60
Yol analizi içinde yer alan yol katsayıları, bir değişkeni yordayan diğer değişkenler sabit tutulduktan sonra hesaplanan regresyon katsayıları olarak yorumlanabilirler. Dolayısıyla, iki değişken arasındaki korelasyonun üçüncü bir değişken sebebiyle mi yüksek olduğu, değişkenlerin doğrudan ve dolaylı etkileri PA ile test edilebilir.

61
Korelasyon veya regresyon katsayılarının tek başlarına nedensellik kanıtlamaması çalışmalarda değişkenlerin birbirlerine neden olup olmadığının irdelenmeyeceği anlamına gelmez. Regresyon katsayıları dışında içeriğe dair literatürden veya mantıksal çıkarımlar nedensellik kanıtı olarak sunulabilir.

62
Hipotez testi PA de dahil tüm SEM uygulamaları hipotez testi bakımından diğer istatistiksel yöntemlerden farklıdır. Ho hipotezi SEM dışındaki yöntemlerde araştırmacının reddetmek istediği hipotezdir. Bu yöntemlerde, Ho’ın reddedilemediği durumlarda, araştırmacı Ho’ın doğru olduğunu göstermiş olmaz. Yalnızca Ho’ın reddedileceği istatistiksel kanıtların bulunmadığı söylenebilir. “retain as a possibility”.

63
PA, CFA ve SEM analizlerinde ise araştırmacının kabul etmek istediği hipotez Ho’dır. Ancak tabiatı gereği hipotez testleri Ho’ı ancak reddedebilir veya reddedemez. Ho doğru bulunmuştur veya kabul edilmiştir gibi çıkarımlar tıpkı diğer hipotez testlerinde yapılamadığı gibi SEM çerçevesinde de yapılamaz. Sadece, Ho’ın reddedilmesi için yeterli güç varken (0,80 ve üzeri) reddedilmiyorsa Ho’ın doğru olması muhtemel güçlü bir alternatif olduğu söylenebilir.
 reddedilmiyorsa Ho’ın doğru olması muhtemel güçlü bir alternatif olduğu söylenebilir..")
64
Sonuç olarak, test edilen bir modelin model veri uyumu yüksek bulunduğunda modelin doğru olduğu ispatlanmış olmaz.

65
Modelin oluşturulması
Çoklu regresyonda olduğu gibi önemli bir bağımsız değişkenin model dışına tutulması regresyon katsayılarını tamamen değiştirebilir. Dolayısıyla, hali hazırda x ve y değişkenlerinin z değişkenini yordadığı biliyorken, w değişkeninin yordama gücünü araştırmak isteyen bir araştırmacı modeline sadece w değişkenini yordayıcı değişken olarak almamalıdır. X, y ve w değişkenlerinin tümü modelde yer almalıdır.

66
Yol Analizinde Ölçme Hatası
Y değişkenlerinin hata varyansları içinde hem modelin açıklayamadığı varyans hem de ölçme hatasından kaynaklı varyans yer alır. Ancak, X değişkenleri PA içinde ölçme hatası olmadan yer almaktadır. Dolayısıyla PA içinde özellikle X değişkenlerinin ölçüm güvenirliklerinin yüksek olması beklenir. Ölçme hatalarının modele entegre edilebilmesi için ise SEM uygulanması gereklidir.

67
Nedensellik – Ok yönü Yol analizi oklarının yönü nedenselliğe işret ettiği için modeldeki okların yönünün neden o şekilde belirlendiği açıklanmalıdır. Eğer değişkenlerin birbirlerini ne yönde etkilediği araştırmacı tarafından kestirilemiyorsa farklı modeller kurulup onların test edilmesi ve kıyaslanması önerilebilir. Değişkenler arasında iki yönlü okların konması da seçenekler arasında olsa da modeli “nonrecursive” yapacak ve model kestirimini ve yorumlanmasını zorlaştıracaktır. Üçüncü bir seçenek ise çoklu regresyonu tercih etmektir.

68
Denk modeller Model veri uyumu bakımından birbiriyle aynı sonucu veren modeller denk modeller olarak anılır (equivalent models). Bu modellerden hangisinin seçilmesi gerektiğine dair istatistiksel kanıt yoktur. Araştırmacı, içerik bakımından literatür destekli veya mantıksal kanıtlarla denk modeller arasında seçim yapmak zorundadır.
. Bu modellerden hangisinin seçilmesi gerektiğine dair istatistiksel kanıt yoktur. Araştırmacı, içerik bakımından literatür destekli veya mantıksal kanıtlarla denk modeller arasında seçim yapmak zorundadır.")
69
Model Serbestlik Derecesi
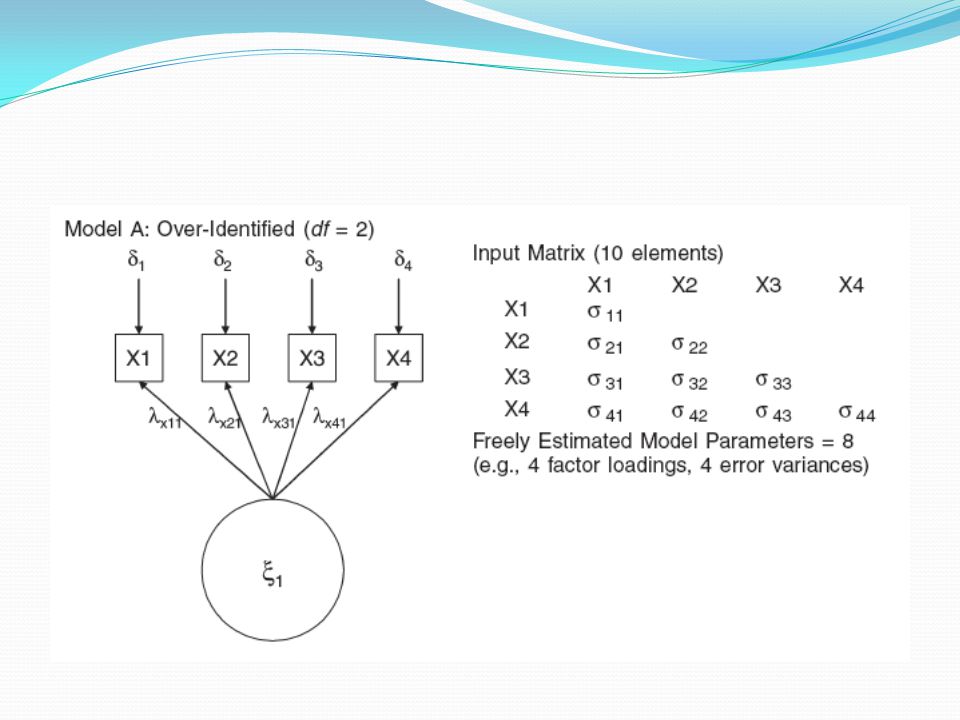
Analize tabi tutulan matriste, yani modelin parametre kestirmekte kullanacağı bilgide, gözlenen değişkenlerin varyansları ve kovaryansları mevcuttur. Bu matristeki elemanların sayısı, p gözlenen değişken sayısı olmak üzere p*(p+1)/2 olarak bellidir. Bir modelin bu sayıdan daha fazla parametre kestirmesi olanaksızdır.
/2 olarak bellidir. Bir modelin bu sayıdan daha fazla parametre kestirmesi olanaksızdır.")
70
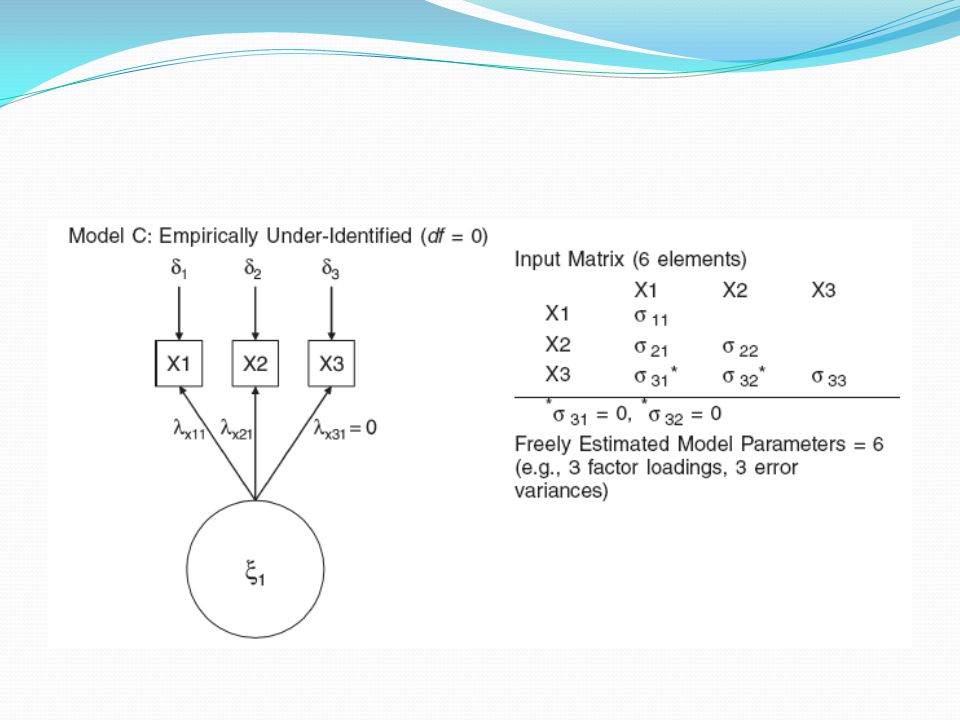
Eğer modelin kestireceği parametre sayısı p
Eğer modelin kestireceği parametre sayısı p*(p+1)/2’yi geçerse LISREL bir sonuç üretmez. Bu tür modellere yeterince tanımlanmamış modeller denir (under identified). Bu modellerin serbestlik derecesi sıfırdan küçüktür.
/2’yi geçerse LISREL bir sonuç üretmez. Bu tür modellere yeterince tanımlanmamış modeller denir (under identified). Bu modellerin serbestlik derecesi sıfırdan küçüktür.")
71
Modelin kestirmesi gereken parametre sayısı p
Modelin kestirmesi gereken parametre sayısı p*(p+1)/2’ye eşit ise bu model tam belirlenmiş model (just identified) olur. “Just identified” modellerde serbestlik derecesi 0’dır. Bu modellerde de çözüm için iterasyon gerekmez ve model veri uyumu testleri yapılmaz zira model verideki kovaryansları aynen üretir. Ancak bu modeller ham veriden daha kullanışlı bir bilgi üretemezler.
/2’ye eşit ise bu model tam belirlenmiş model (just identified) olur. Just identified modellerde serbestlik derecesi 0’dır. Bu modellerde de çözüm için iterasyon gerekmez ve model veri uyumu testleri yapılmaz zira model verideki kovaryansları aynen üretir. Ancak bu modeller ham veriden daha kullanışlı bir bilgi üretemezler.")
72
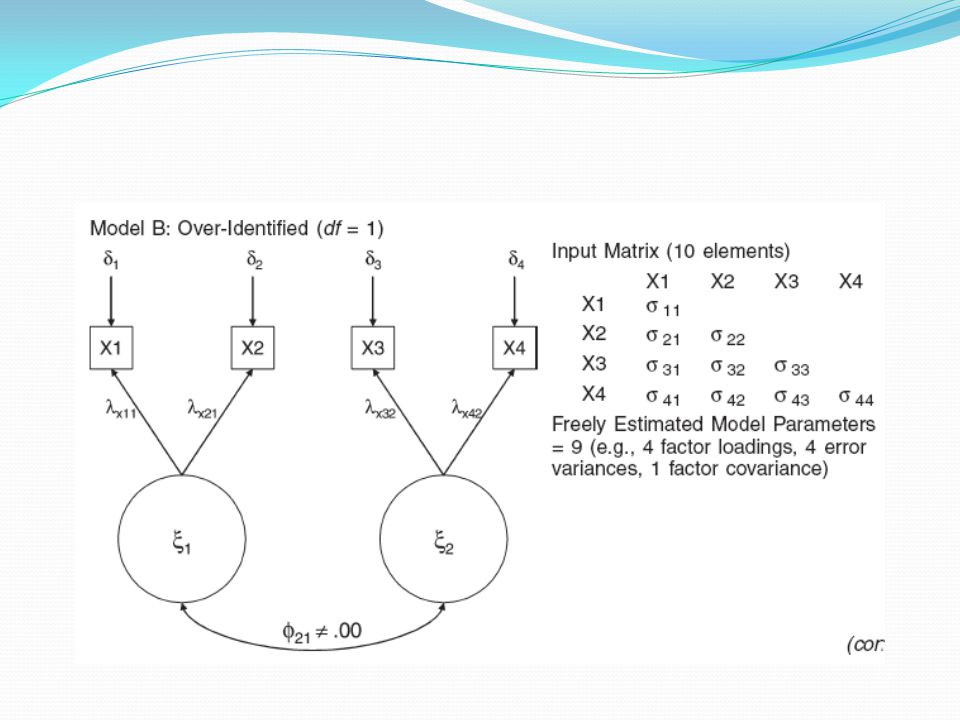
LISREL’in model parametrelerini kestirebilmesi için modelin serbestlik derecesinin 0’dan büyük olması gerekir. “Over identified” modeller denen bu modellerin model veri uyumu testleri yapılabilir zira model daha az parametre ile veri setindeki kovaryansları oluşturmaya çalışır. Örneklemin kovaryanslarına ne kadar yaklaşırsa o ölçüde model veri uyumu sağlanmış olur.

73
Modelin serbestlik derecesinin (df) hesaplanması için eldeki kovaryans matrsinin eleman sayısından modelin kestireceği parametre sayısı çıkarılır. Modelin kestireceği parametreler şunlardır: X değişkenlerinin varyansları + X değişkenlerinin kovaryansları + Yönlü oklar + Hata varyansları

74
dfM = 5*(5+1)/2 – 15 = 15 – 15 = 0
/2 – 15 = 15 – 15 = 0")
75
Bazı durumlarda dfM > 0 olsa bile iki gözlenen arasındaki korelasyon 0,95 ve üzerinde ise (multicollinearity) esasen iki farklı değişken gibi davranmaz ve modelin veri olarak kullanacağı kovaryans matrisinde teoride vereceği kadar veri olmaz. Bu nedenle model çözüm üretemeyebilir. Bu modellere ampirik olarak yetersiz tanımlanmış modeller denir. Bu mesele veri kontrolü aşamasında çözülürse sorun çıkmaz.

76
Örneklem verisi içinde sıfıra çok yakın korelasyonlar da bazı durumlarda ampirik olarak yetersiz tanımlanmış modeller oluşmasına yol açabilir. Modelin serbestlik derecesi (dfM) örneklem büyüklüğü ile ilgili değildir.
 örneklem büyüklüğü ile ilgili değildir.")
77
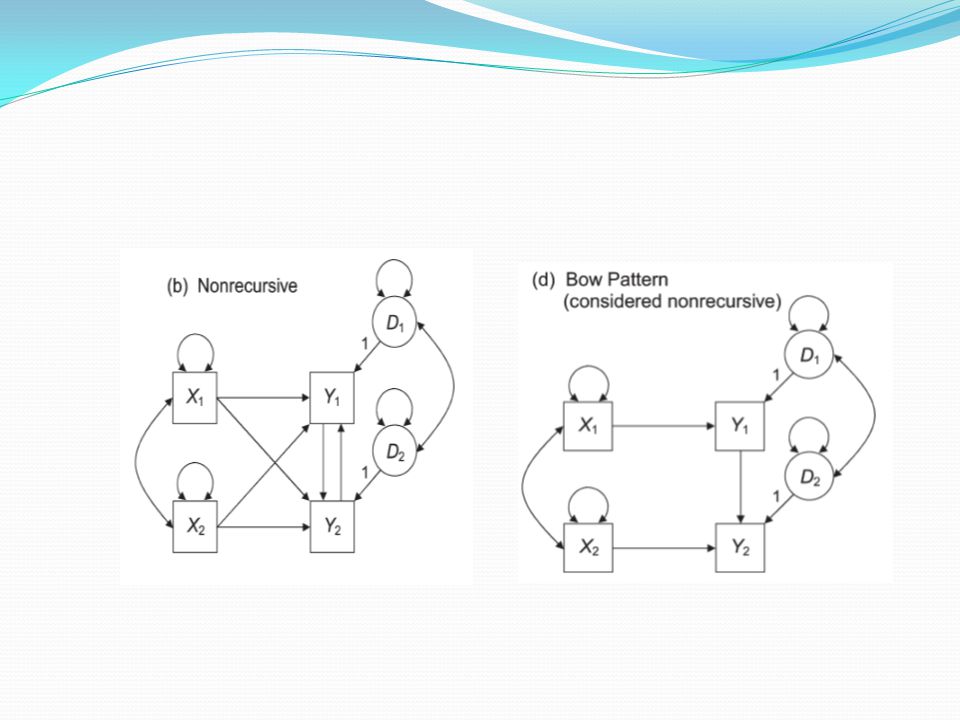
Recursive ve nonrecursive modeller
Recursive modellerde Y değişkenlerindeki hata varyansları arasında kovaryans ve çift yönlü etkileşim oku yoktur.

79
Nonrecursive modellere dair işlemler bu sunuda yer almayacaktır
Nonrecursive modellere dair işlemler bu sunuda yer almayacaktır. Burada geçen serbestlik derecesi hesabı ve muhtemelen diğer analizler hakkında geçen bilgiler recursive modeller için geçerlidir. Bir yol analizi modeli recursive ise serbestlik derecesi negatif değildir. Bir yol analizinde tüm değişkenler arası birer ok ile doğrudan bağlıysa (doğrudan etkiler) model serbestlik derecesi sıfır olur.
 model serbestlik derecesi sıfır olur.")
80
Örneklem Genişliği Minimum örneklem genişliği model tarafından kestirilecek parametre sayısının en az 10 katı kadardır. Normal dağılım sayıltısının sağlandığı veri setleri için 5 kat yeterli olabilir. Ancak hiçbir koşulda 150’nin altında bir örneklem sayısı ile PA, CFA veya SEM analizi yapılması uygun görülmemektedir (Kline, 2005; Bentler & Chou, 1987, Anderson & Gerbing, 1988).
.")
81
Güç SEM çerçevesinin dışındaki istatistiksel yöntemlerde güç araştırmacının lehine işlemektedir. Yani güç arttıkça araştırmacının istediği sonucu alması olasılığı artar (istediği sonucun doğru olduğu kabulüyle). SEM çerçevesinde durum biraz farklıdır. Güç [örneklem genişliği] arttıkça gerçekte doğru olmayan bir modelin model uyum indeksleri ile reddedilmesi olasılığı da artar. Yani eğer araştırmacı önerdiği modelde yanılıyorsa ve düşük güç sahibi bir çalışma yapıyorsa model veri uyumu bakımından araştırmacının “lehine” bir durum söz konusu olmaktadır.
. SEM çerçevesinde durum biraz farklıdır. Güç [örneklem genişliği] arttıkça gerçekte doğru olmayan bir modelin model uyum indeksleri ile reddedilmesi olasılığı da artar. Yani eğer araştırmacı önerdiği modelde yanılıyorsa ve düşük güç sahibi bir çalışma yapıyorsa model veri uyumu bakımından araştırmacının lehine bir durum söz konusu olmaktadır.")
82
Öte yandan, düşük güçle [küçük örneklemle] yapılan bir çalışmada modelin parametreleri kestirilirken parametrelerin standart hataları çok geniş kalacak ve parametrelerin istatistiksel olarak anlamlı bulunmaları olasılığı düşecektir. Bu da araştırmacının “aleyhine” bir durum teşkil edecektir.
![Öte yandan, düşük güçle [küçük örneklemle] yapılan bir çalışmada modelin parametreleri kestirilirken parametrelerin standart hataları çok geniş kalacak ve parametrelerin istatistiksel olarak anlamlı bulunmaları olasılığı düşecektir.](http://slideplayer.biz.tr/slide/1961689/7/images/82/%C3%96te+yandan%2C+d%C3%BC%C5%9F%C3%BCk+g%C3%BC%C3%A7le+%5Bk%C3%BC%C3%A7%C3%BCk+%C3%B6rneklemle%5D+yap%C4%B1lan+bir+%C3%A7al%C4%B1%C5%9Fmada+modelin+parametreleri+kestirilirken+parametrelerin+standart+hatalar%C4%B1+%C3%A7ok+geni%C5%9F+kalacak+ve+parametrelerin+istatistiksel+olarak+anlaml%C4%B1+bulunmalar%C4%B1+olas%C4%B1l%C4%B1%C4%9F%C4%B1+d%C3%BC%C5%9Fecektir..jpg "Bu da araştırmacının aleyhine bir durum teşkil edecektir..")
83
Genel olarak tüm istatistiksel analizler için gücün 0,80 dolaylarında olması beklenir. SEM analizleri için 0,80 dolaylarında güç elde edilmesi için gerekli örneklem büyüklüğü dfM değerinden etkilenir. Farklı dfM düzeyleri için gerekli örneklem büyüklükleri MacCallum, Browne ve Sugawara (1996) tarafından tablolar halinde sağlanmıştır.
 tarafından tablolar halinde sağlanmıştır..")
84
Bu tablolar incelendiğinde çok küçük serbestlik derecesine sahip bir modelin doğru olmadığı kabulüyle 0,80 güç ile reddedilmesi için gerekli örneklem genişlikleri 1000 – 2000 sayılarına ulaşmaktadır. Bu durum, sadece birkaç sorudan oluşan bir ölçme modelini test eden bir araştırmacının model veri uyumunun sağlanmasını ölçme modelinin geçerli olduğuna dair güçlü bir kanıt sayması düşündürücüdür.

85
Örneğin serbestlik derecesi 5 olan bir model test edilirken 100 kişilik bir örneklem kullanıldığında, model geçersiz/yanlış olduğu halde düşük model veri uyumu göstermesi olasılığı 0,10 dolaylarındadır. İlgili tablolar MacCallum vd (1996) tarafından sağlanmıştır.
 tarafından sağlanmıştır.")
86
Aynı tablolar incelendiğinde karmaşık modeller için gücün çok küçük sayılarda bile 0,80 dolaylarına çıkacağını göstermektedir. Ancak bu durum küçük serbestlik dereceleri yüksek modellerin küçük örneklemler ile test edilebileceğini göstermemektedir. Zira bahsi geçen tablo değerleri sadece model veri uyumu üzerine kurulmuştur.

87
Araştırmacıların parametre kestirimlerinde belirli ölçüde hasiyet sağlamaları için yukarıda verilen örneklem genişliklerini sağlamaları gereklidir. (modelce kestirilecek parametre başına 10 kişi, normal dağılım sağlanıyorsa 5 ve 150+)
 .")
88
Parametre Kestirme Yötemleri
En yaygın kullanılan ve normallik sayıltısı gerektiren yöntem en çok olabilirliktir (Maximum Likelihood, ML). Normallik sayıltısını sağlamayan sürekli değişkenler için Robust Maximum Likelihood (MLM) önerilmektedir. Bir diğer normallik sayıltısı bulunmayan yöntem de ağırlıklandırılmış en küçük karelerdir (Weighted Least Squares, WLS).
. Normallik sayıltısını sağlamayan sürekli değişkenler için Robust Maximum Likelihood (MLM) önerilmektedir. Bir diğer normallik sayıltısı bulunmayan yöntem de ağırlıklandırılmış en küçük karelerdir (Weighted Least Squares, WLS).")
89
MLM ve WLS kestiricilerinin kullanılması için asimtotik kovaryans matrisinin oluşturulması gerekmektedir. Özellik WLS çok geniş örneklemlere ihtiyaç duymaktadır.

90
En Çok Olabilirlik Maximum Likelihood (ML)
Y değişkenlerinin çok değişkenli normal olduğunu varsayar. Örneklemdeki data setinin varyans kovaryans matrisi (S) ile modelin kestirdiği kovaryanslar matrisinin (Σ) birbirine yakın olmasına dayalı bir en çok olabilirlik fonksiyonu tanımlanmıştır (FML). Gözlenen değişken sayısı p olmak üzere, FML = ln(|S|) – ln(|Σ|) + trace[(S)(Σ-1)] – p
 ile modelin kestirdiği kovaryanslar matrisinin (Σ) birbirine yakın olmasına dayalı bir en çok olabilirlik fonksiyonu tanımlanmıştır (FML). Gözlenen değişken sayısı p olmak üzere, FML = ln(|S|) – ln(|Σ|) + trace[(S)(Σ-1)] – p")
91
S ve Σ matrisleri birbirine yaklaştıkça bu değer de sıfıra yaklaşmaktadır. Bu iki matris tamamen aynı olduğunda ise sıfır değerini alır.

92
ML kestiricisi bir başlama değerinden itibaren model parametrelerini kestirir. Ardından oluşturduğu ilk model için FML fonksiyonunun değerini hesaplar. Elde ettiği bilgileri kullanarak ikinci bir parametre kestirimi yapar. İkinci parametre kestirimi için hesaplayacağı FML değerinin daha küçük olması beklenir.

93
Bu şekilde iteratif olarak daha iyi çözümlere ulaşır
Bu şekilde iteratif olarak daha iyi çözümlere ulaşır. Artık hesapladığı FML değerleri arasındaki fark çok az olduğunda veya programın kendisine izin verdiği maksimum iterasyon sayısına ulaştıktan sonra durur ve son kestirilen parametrelerle modeli rapor eder.

94
Ancak bazen işler yolunda gitmez
Ancak bazen işler yolunda gitmez. Bazı durumlarda itertif süreç içinde yeni kestirimin FML değeri bir öncekinden daha iyi olmaz. Bu durumlarda LISREL “model does not converge” hatası verir. Sayıltıların sağlanmaması, ampirik yeterince tanımlanmamışlık, örneklem büyüklüğünün yetersizliği, model belirlemesindeki hatalar bu şekilde ML kestiricisinin sonuç bulamamasına sebep olabilir.

95
Heywood vakaları Bazı durumlarda da işlerin yolunda gitmediği model parametrelerine bakmadan anlaşılamaz. Heywood vakaları denen negatif hata varyansı ve mutlak değeri 1’den büyük standart regresyon katsayıları görülebilir. Bu durumun olası sebepleri arasında şunlar yer alır: Modelin çok yanlış tanımlanması Uç değerler Örneklem genişliği < 100 ve bir faktörde 2 gösterge kombinasyonu Ampirik df < 0

96
Hata varyansının negatif olduğu Heywood vakalarının olduğu bir modelde bazı araştırmacılar hata varyansını LISREL komutları ile 0’a eşitleyerek bu problemin etrafından dolanmaktadır. Ancak bu yöntem modeldeki veya data setindeki ciddi bir problemi görmezden gelmek anlamı taşımakta ve önerilmemektedir (Brown, 2006).
..")
97
Normallik sağlanmayınca
ML kestiricisi normallik sayıltısı sağlanmadığında da parametrelerin değerlerini uygun şekilde kestirebilmektedir. Ancak parametrelerin standart hataları yanlı olmaktadır. Bu nedenle de parametrelerin istatistiksel anlamlılığına dair testler uygun sonuçlar vermemektedir.

98
Parametrelerin yorumlanması
Y değişkeninin varyansı 25, hata varyansı ise 15 olsun. Bu durumda Y değişkeninin varyansının 15/25 = % 60’ı model tarafından açıklanamamaktadır. Dolayısıyla Y değişkeninin varyansının % 40’ı modeldeki Y’yi yordayan değişkenlerce açıklanmaktadır (R2 = 0,40). Yol katsayıları ise regresyon katsayıları gibi, standartlaştırılmış yol katsayıları da standartlaştırılmış regresyon katsayıları veya korelasyon katsayıları gibi yorumlanır. Örneğin, “X değişkenindeki 1 puan artış, Y değişkenindeki 2,53 puanlık artışı yordamaktadır.”
. Yol katsayıları ise regresyon katsayıları gibi, standartlaştırılmış yol katsayıları da standartlaştırılmış regresyon katsayıları veya korelasyon katsayıları gibi yorumlanır. Örneğin, X değişkenindeki 1 puan artış, Y değişkenindeki 2,53 puanlık artışı yordamaktadır.")
99
Standartlaştırılmış yol katsayıları için 0,10 civarı küçük, 0,30 civarı orta büyüklükte ve 0,50’nin üzerindeki katsayılar ise büyük etkiler olarak yorumlanabilir (Cohen, 1988). Ancak bu ayrımlar makasla kesilmiş kriterler gibi kullanılmamalıdır. Örneğin 0,49 ve 0,51 bambaşka büyüklüklere işaret eden iki katsayı gibi yorumlanmamalıdır.

100
Nedensellik (tekrar) Bir yol analizi modelinin yönlü oklarının parametre değerleri nedensellik için yeterli kanıt oluşturmamaktadır. Ancak yol analizi parametreleri kanıtlarının yanında aşağıdakiler de eklendiğinde nedensellik kabul görecektir: Modelin başka çalışmalarda başka örneklemler üzerinde de benzer katsayılar sağlaması Denk modellerin elenmesi

101
Maniple edilebilir değişkenlerin kontrol altında tutulduğu deneysel çalışmaların bulgularıyla yol analizi bulgularının örtüşmesi Değişkenlere yapılacak müdahalelerin etkilerinin önceden doğru biçimde kestirilebilmesi

102
Bir yol analizi örneği

103
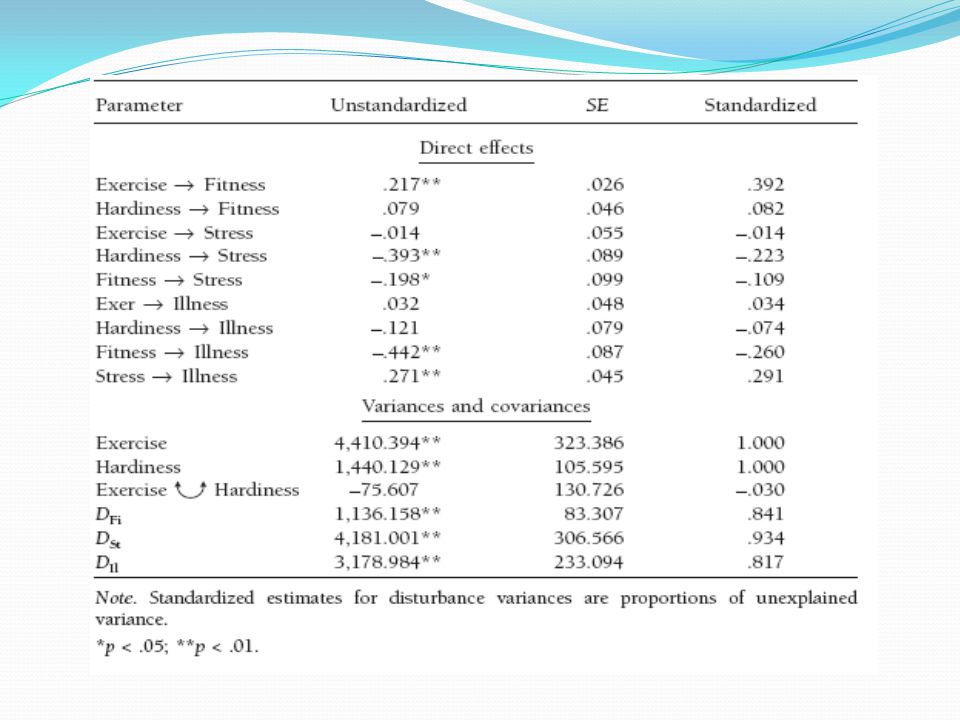
Hardiness değişkeni sabit tutulduğunda, Exercise değişkeni üzerindeki bir standart sapma artış Fitness değişkeni üzerindeki 0,392 standart sapma artışı yordamaktadır. LSIREL her bir katsayı için t değerini vermekte ve istatistiksel olarak anlamlı olmayanlarını kırmızı ile göstermektedir. Yukarıdaki şekilde anlamlı olmayan (p > 0,05) yol katsayıları kesikli oklarla gösterilmiştir. Anlamlılık düzeyi geniş örneklemler için t değerlerinin z gibi yorumlanmasıyla elde edilebilir.
 yol katsayıları kesikli oklarla gösterilmiştir. Anlamlılık düzeyi geniş örneklemler için t değerlerinin z gibi yorumlanmasıyla elde edilebilir..")
105
X değişkenlerinin Y değişkenleri üzerindeki etkilerinin büyüklükleri standartlaştırılmış yol katsayıları ile kıyaslanabilir. Buna göre, yukarıdaki örnekte “Exercise değişkeninin Fitness üzerindeki standartlaştırılmış etkisi Hardiness değişkeninin Fitness üzerindeki etkisinin yaklaşık dört katıdır” denebilir.

106
Doğrudan, dolaylı ve toplam etkiler
Fitness değişkeninin Ilness üzerindeki doğrudan standartlaştırılmış etkisi -0,260 olarak görülmektedir. Fitness değişkeni Illness değişkenini ayrıca Stress değişkeni üzerinden dolaylı olarak da etkilemektedir. Bu etkinin standartlaştırılmış sayısal değeri izleme kuralı ile bulunabilir: -0,109 * 0,291 = -0,032.

107
Fitness değişkeninin Illness değişkeni üzerindeki toplam standartlaştırılmış etkisi doğrudan ve dolaylı etkisi toplanarak bulunabilir: -0,260 + (-0,032) = -0,292. Bu toplam etki de standartlaştırılmış regresyon katsayısı olarak yorumlanabilir.

108
S – Σ matrisi Model veri uyumunun bir göstergesi olarak S ve Σ matrislerinin arasındaki fark matrisinin (residual matrix) irdelenmesi önerilir. Ancak kovaryanslar göstergelerin varyanslarından etkilendikleri için bu matrisin standartlaştırılmış halinini yani korelasyonların hata matrisinin incelenerek 0,10 değerini geçen değerlendirilenmesi önerilmiştir.
 irdelenmesi önerilir. Ancak kovaryanslar göstergelerin varyanslarından etkilendikleri için bu matrisin standartlaştırılmış halinini yani korelasyonların hata matrisinin incelenerek 0,10 değerini geçen değerlendirilenmesi önerilmiştir.")
109
LISREL kovaryans matrisini incelediğinde korelasyonlara dair hata matrisini sağlamamaktadır. Bunun yerine kovaryansların hata matrisindeki elemanlara z testi yapmakta ve bu elemanların 0’dan farklı olup olmadıklarına dair bir istatistiksel hipotez testi sağlamaktadır.

110
Model veri uyumu indeksleri
Model veri uyumu genellikle SEM çerçevesinde yapılan çalışmalarda esas odak noktası olmaktadır. Ancak bu durum eleştirilmektedir. Model veri uyumu kadar parametrelerin mantıklı olması ve yorumlanmaları da önemlidir. Model veri uyumu indeksleri ile ilgili dikkat edilecek ikinci bir nokta ise model veri uyumunun sağlanmış olmasının modeli doğru/anlamlı/mantıklı kılmayacağıdır.

111
Son olarak, model veri uyumunun sağlanmış olması modeldeki yordayıcı değişkenlerin güçlü birer yordayıcı olduğu anlamına gelmez. Hata varyansları yüksek (ve R2 değerleri düşük) modeller de model veri uyumu sağlayabilir.
 modeller de model veri uyumu sağlayabilir..")
112
Modeller karmaşıklaştıkça model veri uyumu sağlamaları olasılığı artar
Modeller karmaşıklaştıkça model veri uyumu sağlamaları olasılığı artar. Ancak çok karmaşık modeller ham veriden daha farklı ve önemi bir bulgu sağlamazlar. SEM çerçevesinde amaç, model veri uyumundan çok fazla ödün vermeden, basit teorik olarak anlamlı modeller geliştirmektir.

113
Rapor edilmesi önerilen indeksler:
χ2(dfM) ve p χ2(dfM)/ dfM veya Normed Chi-Square (NC) RMSEA (%90 güven aralığı) CFI SRMR
 ve p. χ2(dfM)/ dfM veya Normed Chi-Square (NC) RMSEA (%90 güven aralığı) CFI. SRMR.")
114
χ2(dfM) ve p Modelin ki kare değeri, serbestlik derecesi ve anlamlılık düzeyidir. Örneklem büyüklüğü arttıkça χ2(dfM) değeri de artar ve ilgili serbestlik derecesinde model veri uyumu çok yakın olsa bile p < 0,05 çıkar. Yani model reddedilir. Dolayısıyla, bu indekse bakarak modeli reddetmemek gerekir. Ancak yine de rapor edilmelidir. Örnek rapor edilme şekli: χ2(34) = 88,159, p < 0,001
 değeri de artar ve ilgili serbestlik derecesinde model veri uyumu çok yakın olsa bile p < 0,05 çıkar. Yani model reddedilir. Dolayısıyla, bu indekse bakarak modeli reddetmemek gerekir. Ancak yine de rapor edilmelidir. Örnek rapor edilme şekli: χ2(34) = 88,159, p < 0,001")
115
MLM veya WLS kestiricileri kullanıldığında
SBχ2 indeksi kullanılmalıdır.

116
NC χ2(dfM)/ dfM veya Normed Chi-Square
χ2 değerinin serbestlik derecesine bölünmesiyle elde edilir. 2, 3 veya 5’in altında olmasını öneren araştırmacılar mevcuttur (Bollen, 1989). Ancak örneklem büyüklüğünün etkisini tamamen yok edememiştir.
. Ancak örneklem büyüklüğünün etkisini tamamen yok edememiştir.")
117
RMSEA (%90 güven aralığı)
Model karmaşıklığının etkisini hesaba katar. Aynı χ2 değerini üreten iki modelden daha basit olan modelin RMSEA indeksi daha düşük çıkacaktır. RMSEA indeksinin 0,05 altında olması çok yakın model veri uyumuna; 0,08’e kadar olması kabul edilebilir uyuma işaret etmektedir. RMSEA ≥ 10 olan modeller ise zayıf model veri uyumu nedeniyle reddedilmektedir (Broene & Cudeck, 1993).
.")
118
RMSEA değeri %90 güven aralığıyla birlikte rapor edilmelidir
RMSEA değeri %90 güven aralığıyla birlikte rapor edilmelidir. Üst sınırının 0,10’un altında kalması beklenir. Güven aralığının geniş olması ise daha geniş bir örnekleme ihtiyaç duyulduğuna işaret eder.

119
CFI Tüm kovaryansların 0 kabul edildiği bir taban model ile kıyaslama yapar. 0,90 ve üzerinde olması önerilir (Hu & Bentler, 1999).
.")
120
SRMR 0,10’un altında olması önerilir (Klein, 2005).
.")
121
AIC Hiyerarşik olmayan modeller kıyaslanırken kullanılır. Daha düşük değere sahip model tercih edilmelidir (Kline, 2005).
.")
122
Rapor edilmesi gerekmeyen indeksler
GFI, AGFI, PGFI, NFI, NNFI, PNFI, PCFI, CAIC, BIC ve ECVI Yukarıdaki indeksler verildiğinde bu indekslerin kullanılması veya rapor edilmesine gerek yoktur (Brown, 2006; Kline, 2005).
.")
123
Hiyerarşik modellerin test edilmesi
A ve B iki model olsun. A modeli üzerindeki oklardan biri ya da birkaçı kaldırıldığında B modeli elde ediliyorsa veya A modelindeki parametrelerden biri ya da bir kaçı sabitlendiğinde/kısıtlandığında B modeli elde ediliyorsa bu iki model hiyerarşik yapıdadır. Her durumda daha karmaşık olan A modeli daha iyi model veri uyumu sağlayacaktır. Ancak amaç, model veri uyumunda istatistiksel olarak anlamlı ölçüde kayıp vermeden daha basit modeli kabul etmektir.

124
Daha basit olan B modelinin oluşturulmasında sadece A modelindeki bazı parametrelerin istatistiksel olarak anlamsız çıkması veya LISREL’in modifikasyon indeksleri sağlamış olması gerekçe olmamalı, içeriğe dair literatürden veya mantıksal kanıtların da sağlanması gereklidir.

125
A ve B hiyerarşik modellerinin testinde χ2fark testi uygulanır
A ve B hiyerarşik modellerinin testinde χ2fark testi uygulanır. Örneğin, A modeli için χ2(4) = 13,20 B modeli için χ2(5) = 18,30 [daha basit modelde df daha yüksektir.] ise χ2fark = χ2(5) – χ2(4) = χ2(1) = 18,30 – 13,20 = 5,10 bulunur. χ2(1) = 5,10 için p = 0,024 olduğundan model veri uyumları arasındaki fark 0,05 düzeyinde anlamlıdır. [p değeri Excel yardımıyla bulunabilir.]
 = 13,20 B modeli için χ2(5) = 18,30 [daha basit modelde df daha yüksektir.] ise χ2fark = χ2(5) – χ2(4) = χ2(1) = 18,30 – 13,20 = 5,10 bulunur. χ2(1) = 5,10 için p = 0,024 olduğundan model veri uyumları arasındaki fark 0,05 düzeyinde anlamlıdır. [p değeri Excel yardımıyla bulunabilir.]")
126
χ2fark testi anlamlı bulunursa daha karmaşık olan model (örnekte A modeli); anlamsız bulunursa daha basit olan model tercih edilmelidir. Burada test edilen iki modelin de uygun model veri uyumunu sağlaması beklenir. Hiyerarşik modellerin test edilmesinde MLM ve WLS kullanılmış ise yukarıdaki χ2fark testi geçerli olmayacaktır.

127
Denk Modeller Aynı model veri uyumunu sergileyen modeller denk modellerdir. Denk modeller aynı model veri uyumunu sağladıkları için istatistiksel olarak aralarında bir tercih yapılamaz. Denk modeller içerik olarak anlamları, değişkenlerin ilişkileri ve nedenselliklerin yönü bakımından birbirlerinden farklıdır.

128
Yöntembilimcilere göre, araştırmacı öngördüğü modelin uygun olduğuna dair kanıtları sunduktan sonra denk modelleri de göz önüne alarak neden o diğer denk modellerden birinin değil de kendi önerdiği modelin daha uygun bulunduğunu teorik olarak açıklamalıdır. Ancak literatürde buna özen gösterilmediği görülmektedir. Hatta bazı yöntembilimciler SEM uygulayan araştırmacıların hemen hemen hepsinin denk modellerden bihaber olduğunu veya görmezden geldiklerini iddia etmektedir (MacCallum & Austin, 2000).
.")
129
Var olan bir modele denk modellerin neler olabileceği iki kural ile özetlenmiştir (Klein, 2005, p.154).
.")
130
Doğrulayıcı Faktör Analizi

131
Bir göstergenin bir tek gizil değişkene (boyuta) ait olduğu ve hata varyanslarının korelasyonlarının sıfır kabul edildiği ölçme modelleri konjenerik ölçme modelleridir. Göstergelerin hata varyansları iki tür varyansı yansıtır: (1) tesadüfi ölçme hatasını ifade eden varyans ve (2) ölçme biçiminden kaynaklı faktörler tarafından açıklanmayan varyans (örneğin ters yönlü maddeler arasındaki paylaşılan varyans).
 tesadüfi ölçme hatasını ifade eden varyans ve (2) ölçme biçiminden kaynaklı faktörler tarafından açıklanmayan varyans (örneğin ters yönlü maddeler arasındaki paylaşılan varyans).")
132
SEM çerçevesinde yer alan ölçme modellerinin konjenerik olması zorunluluğu yoktur. Dolayısıyla bir gösterge birden çok faktör tarafından yordanabilir veya birkaç gösterge arasındaki hata varyanları arasındaki korelasyonlar model tarafından serbestçe kestirilmesi sağlanabilir. Ancak bu eklenen serbest kovaryansların modeli karmaşıklaştırdığı da göz önüne alınmalıdır.

133
Daha önemlisi, bu kararların teorik olarak desteklenmemesi durumunda sadece modifikasyon indeksleri işaret ettiği için, model veri uyumunu artırmak amacıyla alınmaması hatırlanmalıdır. Örneğin göstergelerin hat varyanslarının birbirleriyle korelasyonlarının serbest bırakılması için zıt yönlü maddeler olması uygun bir teorik destek olabilir.

134
Formatif göstergeler Standart ölçme modellerinde faktörler göstergeleri yordar. Bu nedenle, ölçülen gizil değişken üzerindeki değişimlerin göstergelerden alınan puanları belirlediği düşünülür. Ancak sosyo-ekonomik düzey (SED) gibi değişkenlerin esasen kendilerini oluşturan göstergelerin sebebi değil sonucu olduğu görülmektedir. Bu durumlarda SEM çerçevesinde okların yönü değişecektir. SED gibi gizil değişkenlerin göstergelerine formatif gösterge denir.
 gibi değişkenlerin esasen kendilerini oluşturan göstergelerin sebebi değil sonucu olduğu görülmektedir. Bu durumlarda SEM çerçevesinde okların yönü değişecektir. SED gibi gizil değişkenlerin göstergelerine formatif gösterge denir.")
135
dfM Modelin kestirmesi gereken parametreler sayılırken faktörlerin varyansları, kovaryansları, göstergelerin hata varyansları, faktör yükleri sayılır. Ancak gizil değişkenin ölçeklenmesi için araştırmacı tarafından 1 olarak belirlenen faktör yükleri veya LISREL tarafından 1’e sabitlenen faktör varyansları hesaba katılmaz.

136
Örneklem data setinde yer alan varyans kovaryans matrisinin elemanlarının sayısı p*(p+1)/2’dir. Bu sayıdan modelin kestireceği parametre sayısı çıkarıldığında modelin serbestlik derecesi bulunur.

142
Parametrelerin yorumlanması
Konjenerik ölçme modellerinde standartlaştırılmış faktör yükleri standart regresyon katsayıları veya faktör ile gösterge arasındaki korelasyon olarak yorumlanır. Faktör yüklerinin yüksek ( > 0,60), gösterge hata varyanslarının düşük olması beklenir. Birden çok faktörlü modeller için faktörler arası korelasyonların 0,85’i geçmemesi beklenir.
, gösterge hata varyanslarının düşük olması beklenir. Birden çok faktörlü modeller için faktörler arası korelasyonların 0,85’i geçmemesi beklenir.")
143
Konjenerik ölçme modeli altında, standartlaştırılmış çözümlerde bir göstergeye ait faktör yükünün karesi ile hata varyansı toplandığında 1 bulunur. Yine konjenerik ölçme modeli altında, standartlaştırılmamış çözümlerde ise faktör yükün karesi ile hata varyansının karesi toplandığında göstergenin varyansı elde edilir.

144
Normallikten sapmanın etkisi
Göstergeler iki, üç veya dört kategorili olduklarında normal dağılım sayıltısını sağlamaları pek mümkün değildir. Bu durumlarda ML yerine, MLM veya WLS kullanılmalıdır.

145
Ölçme modellerinin test edilmesi
Tek faktörlü bir ölçme modeli reddedilemiyorsa çok faktörlü modellerin analizine gidilmesi doğru değildir. Teorik model birden çok faktörü işaret ediyor olsa bile tek faktörlü modelin reddedilememesi maddelerin birbirinden farklı kavramları ölçmediğine dair bir kanıttır. Tek ve çok faktörlü iki ölçme modeli hiyerarşiktir ve χ2fark testi ile aralarında seçim yapılabilir. Bir CFA örneği: Pınar, Çelik, & Bahçecik (2009)
")
146
Rapor edilmesi gerekenler
Önerilen model için kavramsal ve teorik gerekçeler Hangi madde/göstergelerin hangi faktöre ait olduğu Gizil değişkenlerin ölçeklenmesi Model tarafından kestirilen ve araştırmacı tarafından sabitlenen parametreler Modelin tanımlı olduğunun gösterilmesi Örneklem genişliği, örnekleme metodu, örneklemin karakteristik özellikleri Sayıltıların test edilmesi Kayıp verilerin analizi ve ne yapıldıkları

147
Gösterge korelasyonları ve standart sapmaları
Model parametrelerinin kestirilmesinde kullanılan yazılım ve sürümü (LISREL 8.8 gibi) Analize tabi tutulan data matrisi (kovaryans matrisi, asimtotik kovaryanslar matrisi gibi) Kullanılan kestirim metodu (ML, MLM, WLS gibi)
 Analize tabi tutulan data matrisi (kovaryans matrisi, asimtotik kovaryanslar matrisi gibi) Kullanılan kestirim metodu (ML, MLM, WLS gibi)")
148
Genel model veri uyumu indeksleri
Genel model veri uyumu indeksleri. Örneğin; χ2(48) = 188,050, p < 0,001, NC = 3,918, CFI = 0,886, SRMR = 0,067 ve RMSEA = 0,124 (%90 güven aralığı 0,103 – 0,145)
 = 188,050, p < 0,001, NC = 3,918, CFI = 0,886, SRMR = 0,067 ve RMSEA = 0,124 (%90 güven aralığı 0,103 – 0,145)")
149
Modelin üretemediği kovaryansların nasıl irdelendiği (modifikasyon indeksleri, standartlaştırılmış hatalar matrisi gibi gibi değerlerin en büyüğü rapor edilebilir) Model yeniden şekillendirilmişse bu yeniden şekillendirmenin (eklenen veya çıkarılan parametrelerin) teorik istatistiksel gerekçeleri İstatistiksel olarak anlamlı olmayanlar dahil tüm parametrelerin kestirilen değerleri Parametrelerin istatistiksel anlamlılığı yanında pratik anlamlılığının irdelenmesi Modelin kavramsal olarak doğurduğu sonuçlar ve modelin yorumlanması
 teorik istatistiksel gerekçeleri. İstatistiksel olarak anlamlı olmayanlar dahil tüm parametrelerin kestirilen değerleri. Parametrelerin istatistiksel anlamlılığı yanında pratik anlamlılığının irdelenmesi. Modelin kavramsal olarak doğurduğu sonuçlar ve modelin yorumlanması.")
150
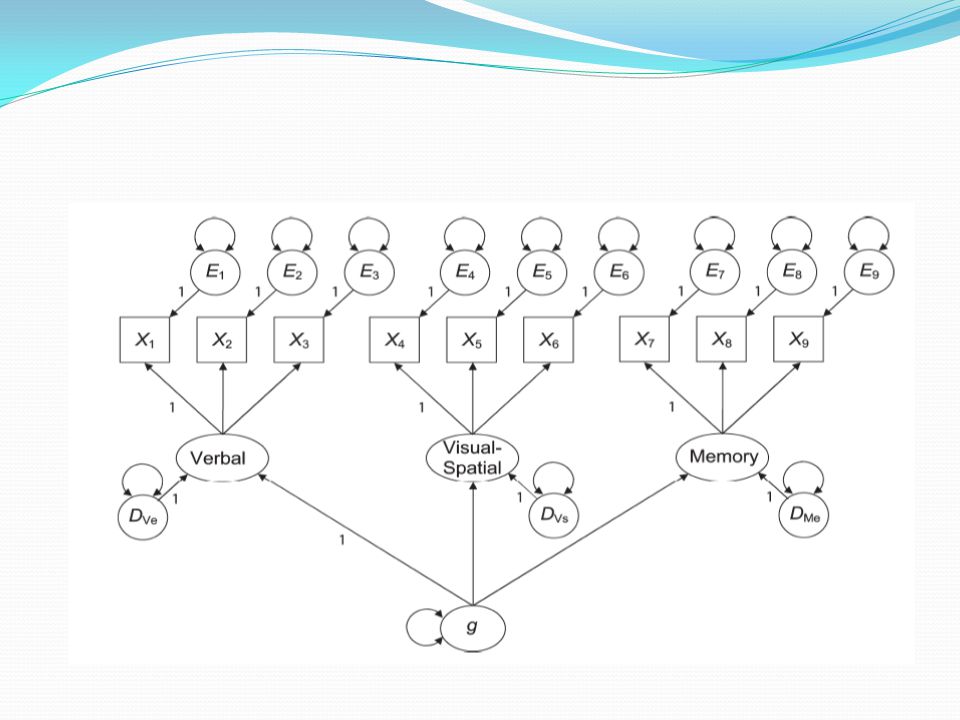
İkinci düzey doğrulayıcı faktör analizi
Bir ölçme modelinde faktörler arasındaki yüksek korelasyonların sebebinin üçünün de arkasında yer alan ikinci düzey bir faktör olduğu düşünülürse veya faktörlerin bir üst yapının alt boyutları olduğu düşünülürse ikinci düzey CFA uygulanabilir. İkinci düzey faktör analizinin uygun sonuçlar vermesi, ölçme kullanılan ölçme aracından faktör puanları yanı sıra genel bir toplam puanın da çıkarılmasının anlamlı olacağına dair bir kanıt olarak görülebilir.

151
İkinci düzey CFA için birinci düzey faktörler ikinci düzey faktörün göstergeleri olarak alınır. Bu nedenle, serbestlik derecesi hesabı sonucu iki faktörlü bir ölçme modeline ikinci düzey faktör analizi yapılamaz. İkinci düzey faktör analizi aşağıdaki görünmektedir.

153
İkinci düzey faktör analizi örneği: Neuman, Bolin, & Briggs (2000)
")
154
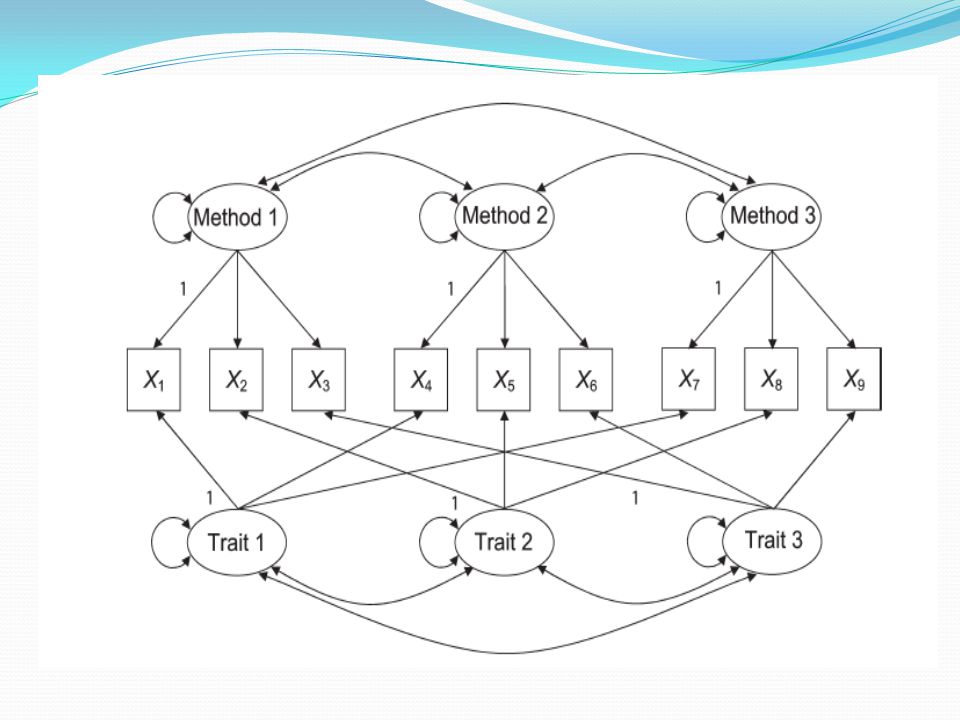
Çok boyut çok yöntem (MTMM)
ayrıcı ve uyum geçerliği analizi (convergent & discriminant validity)
")
157
Faktör puanları Faktör puanlarının hesaplanması için kullanılan en basit yöntem madde puanlarının toplamıdır. Daha karmaşık olan diğer yöntemlerden daha kötü değildir; kullanılabilir.

158
Çoklu grup CFA Sadece kovaryans yapılarının incelendiği durumlarda ölçüm değişmezliğinin test edilmesi için kullanılır. Ortalama yapılarının analize dahil edilmesiyle farklı grupların gizil değişkenler üzerindeki puanlarının da kıyaslanmasına olanak vardır. Ölçüm değişmezliği birden çok kültürde ve dilde kullanılan ve farklı ülkelerden katılımcı grupların kıyaslanmasında kullanılan ölçme araçlarının yaygınlaşması ile daha çok önem kazanmıştır. Örneğin Finlandiya ve Türkiye PIRLS bulguları kıyaslanmadan önce iki ayrı dildeki testin de aynı yapıyı ölçtüğünün istatistiksel olarak gösterilmesi gereklidir.

159
Ölçüm değişmezliğinin dereceleri üzerinde bir dil birliği mevcut olmasa da genel olarak üç tür ölçüm değişmezliği söz konusudur: Zayıf değişmezlik: Faktör yapılarının aynı olması, diğer parametreler serbest Güçlü değişmezlik: Faktör yapılarının ve faktör yüklerinin aynı olması, hata varyansları serbest Tam değişmezlik: Faktör yapıları, faktör yükleri ve hata varyansları aynı

160
Kültürler arası kullanılan ölçme araçları için ölçüm değişmezliği üzerine daha çok bilgi almak için, Hacettepe Üniversitesi’nden Mustafa Asil’in ve Tuncay Öğretmen’in doktora tezleri ve Ankara Üniversitesi’nden Murat Akyıldız’ın doktora tezleri incelenebilir.

161
Yapısal Eşitlik Modelleri (SEM)
")
163
SEM modellerinin test edilmesi için önce geçerli bir ölçme modeline ihtiyaç vardır.

165
dfM Modelin kullanacağı bilgilerin olduğu kovaryans matrisinin birbirinden farklı elemanlarının sayısı p*(p+1)/2’dir. Modelin kestireceği parametre sayısı hesaplanırken X değişkenlerinin (hatalar dahil) varyans ve kovaryansları ile faktör yükleri ve yol katsayıları dahil edilir. Kullanıcı tarafından gizil değişkenlerin ölçeklenmesi amacıyla 1’e sabitlenen faktör yükleri veya yazılım tarafından 1’e sabitlenen gizil değişken varyansları hesaba katılmaz.
/2’dir. Modelin kestireceği parametre sayısı hesaplanırken X değişkenlerinin (hatalar dahil) varyans ve kovaryansları ile faktör yükleri ve yol katsayıları dahil edilir. Kullanıcı tarafından gizil değişkenlerin ölçeklenmesi amacıyla 1’e sabitlenen faktör yükleri veya yazılım tarafından 1’e sabitlenen gizil değişken varyansları hesaba katılmaz.")
166
SEM modellerinin tanımlanmış olup olmadıklarının belirlenmesi için iki adım kullanılır: SEM modelini bir CFA olarak düzenleyip df incelenir. CFA modeli için dfM ≥ 0 olduğu görüldükten sonra modelin sadece yapısal kısmı yol analizi gibi görüntülenir. Eğer yapısal kısım recursive ise model tanımlıdır.

167
SEM’de kullanılacak ölçme modeli konjenerik değilse modelin serbestlik derecesini belirlemek mümkün olmayabilir. Modelin serbestlik derecesi 0’dan büyük değilse zaten LISREL sonuç üretmeyecektir. Test edilecek modelin tanımlı olup olmadığının önceden bilinmesi araştırma önerisi yazımında keönem arz edebilir. Tanımlı olmayan bir modelin test edilmesini öngören bir araştırma önerisi hakemlerden dönebilir.

168
Modelin test edilmesi Yapısal eşitlik modellerinin test edilmesi için tek aşamalı bir test yöntemi uygun görülmemektedir. Bunun yerine iki aşamalı veya dört aşamalı modeller önerilmiştir. Bu sunuda iki aşamalı model yer alacaktır. İki aşamalı modelde SEM öncelikle CFA modeli olarak kurulur ve test edilir. Ölçme modeli uygun model veri uyumu sağlamıyorsa araştırmacının ölçme modelini yeniden düzenleyip uygun bir ölçme modeli elde etmesi gerekir.

169
İkinci aşamada ise orijinal yapısal eşitlik modeli kurularak test edilir. Ölçme modeli ile orijinal yapısal eşitlik modeli ve diğer olası yapısal modeller kıyaslanır. Ölçme modeli ile diğer modeller hiyerarşik yapıdadır. Hiçbir yapısal model, CFA’dan daha fazla model veri uyumu üretmez. Ancak daha önceki analizlerde olduğu gibi burada da amaç model veri uyumundan çok kaybetmeden daha basit bir modeli oluşturmaya çalıştırmaktır.

170
Bir SEM örneği Araştırmacının test etmek istediği yapısal model:

171
Yapısal modelde yer alan değişkenlerin ölçüldüğü ve yapısal modelin test edilmesinin ilk basamağını teşkil edilen ölme modeli:

173
Ölçme modeline dair model veri uyumu şu şekilde rapor edilmiştir: χ2(48) = 188,050, p < 0,001, NC = 3,918, CFI = 0,886, SRMR = 0,067 ve RMSEA = 0,124 (%90 güven aralığı 0,103 – 0,145)
 = 188,050, p < 0,001, NC = 3,918, CFI = 0,886, SRMR = 0,067 ve RMSEA = 0,124 (%90 güven aralığı 0,103 – 0,145)")
174
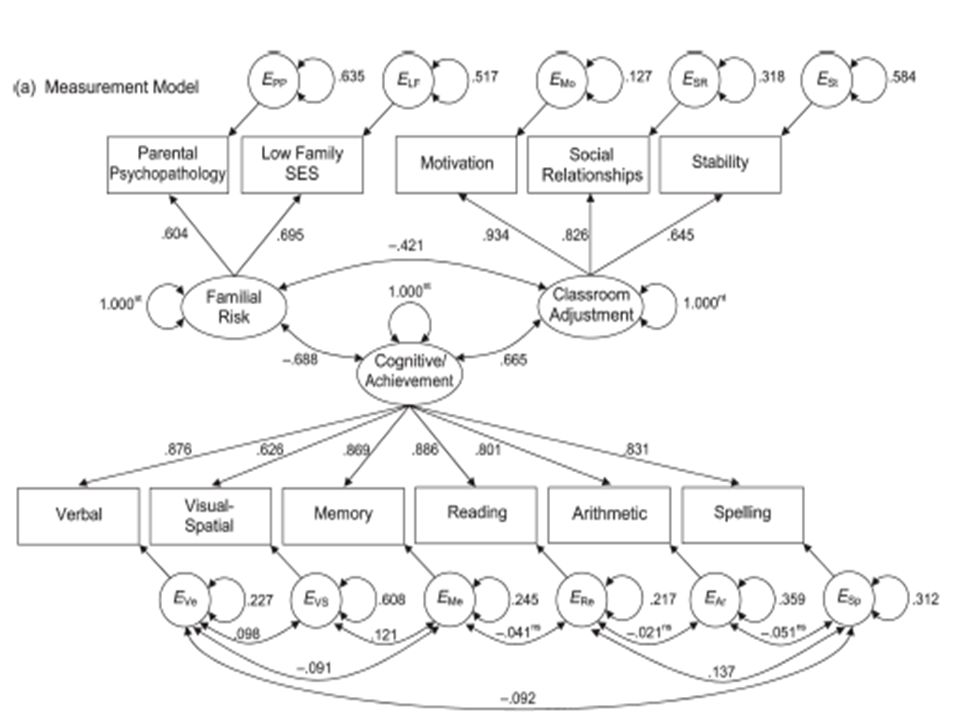
Bu durumda, ölçme modelinin model veri uyumunun iyileştirilmesi ihtiyacı görülmüştür. Standartlaştırılmış çözümde ilk olarak Extraversion değişkeninin hata varyansı 0,951, faktör yükü ise 0,221 olarak göze çarpmaktadır. Bu göstergenin modelden çıkarılması uygun olacaktır.

175
İkinci göze çarpan durum, Cognitive ile Achivement arasındaki korelasyonun 0,909 olduğudur. Bu durum, araştırmacının ölçme modelinin Cognitive ile Achievement yapılarını ayrık olarak ölçemediğini göstermektedir (poor discriminant validity). Dolayısıyla bu iki faktörün birleştirilmesi öngörülmüştür.
. Dolayısıyla bu iki faktörün birleştirilmesi öngörülmüştür..")
176
Cognitive ve Achivement değişlenlerinin göstergeleri bu kavramları ölçen iki testin alt boyutlarından alınan puanlardır. Bu iki faktör birleştirildiğinde aynı testin alt boyutu olan göstergelerin metod etkisi göstermesi, yani hata varyansları birbirleri arasında korelasyon gösterecektir. Bu şekilde hataların arasında ilişki kurulmasına ve modelin hata kovaryanslarını serbestçe kestirmesine teorik olarak gerekçe sağlanmıştır. Bu düzenlemeler ardından oluşan ölçme modeli test edilmiştir.

178
Yeni ölçme modelinin model veri uyumu şu şekilde rapor edilmiştir:
χ2(33) = 52,407, p < 0,107, NC = 1,558, CFI = 0,983, SRMR = 0,041 ve RMSEA = 0,059 (%90 güven aralığı 0,022 – 0,089)
 = 52,407, p < 0,107, NC = 1,558, CFI = 0,983, SRMR = 0,041 ve RMSEA = 0,059 (%90 güven aralığı 0,022 – 0,089)")
179
Ölçme modelindeki faktörlerden ikisi birleştirildiği için yapısal model aşağıdaki biçimi almıştır:

180
Ölçme modeli doğrulandıktan sonra yapısal eşitlik modeli test edildiğinde aşağıdaki gibi bir model veri uyumu bulunmuştur: χ2(34) = 52,948, p < 0,021, NC = 0,984, CFI = 0,984, SRMR = 0,041 ve RMSEA = 0,058 (%90 güven aralığı 0,021 – 0,088)
 = 52,948, p < 0,021, NC = 0,984, CFI = 0,984, SRMR = 0,041 ve RMSEA = 0,058 (%90 güven aralığı 0,021 – 0,088)")
181
CFA modeli ile SEM hiyerarşik modeller olduğundan kıyaslanmaları χ2fark testi ile yapılır: χ2(33) – χ2(33) = χ2(1) = 52,407 – 52,407 = 0,241, p = 0,623 > 0,05 Dolayısıyla, Familial Risk değişkeninin Classroom Adjustment değişkeni üzerindeki doğrudan etkisi olmadan oluşturulan yapısal modelin veriye uyumu ile bu doğrudan ilişkinin yer aldığı modele ait veri uyumu arasında istatistiksel olarak anlamlı bir fark bulunmamaktadır.
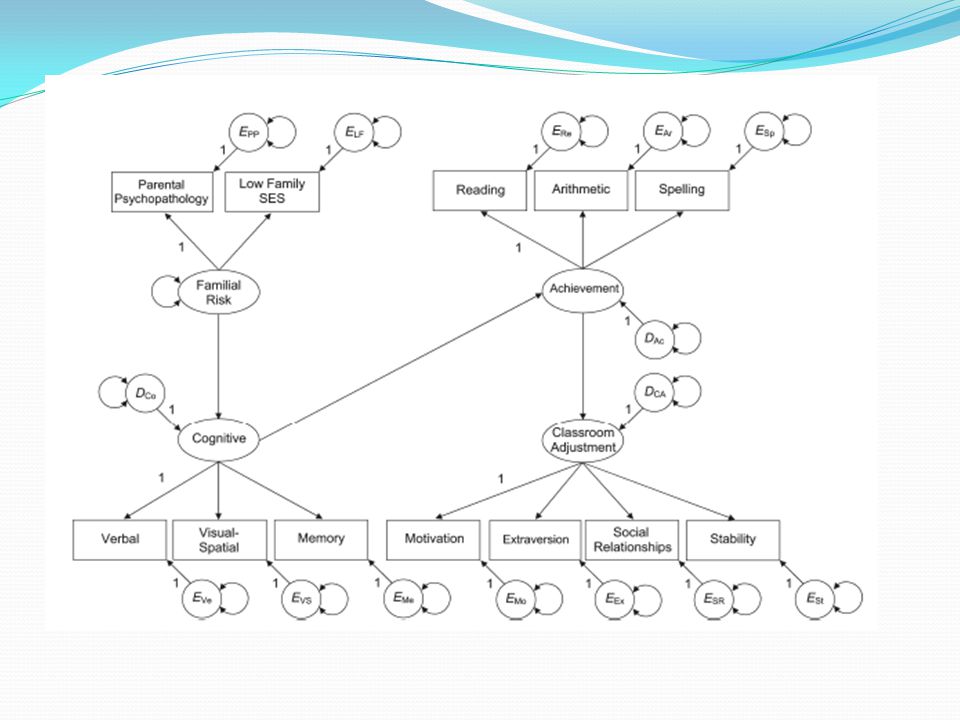
 – χ2(33) = χ2(1) = 52,407 – 52,407 = 0,241, p = 0,623 > 0,05 Dolayısıyla, Familial Risk değişkeninin Classroom Adjustment değişkeni üzerindeki doğrudan etkisi olmadan oluşturulan yapısal modelin veriye uyumu ile bu doğrudan ilişkinin yer aldığı modele ait veri uyumu arasında istatistiksel olarak anlamlı bir fark bulunmamaktadır.")
182
Bu durum, Familial Risk → Classroom Adjustment doğrudan etkisine ait yol katsayının istatistiksel olarak anlamlı olmadığını da göstermektedir. Analizin sonucunda, Familial Risk değişkeninin Classroom Adjustment değişkeni üzerindeki etkisinin tamamının Cognitive/Achievement değişkeni üzerinden dolaylı olarak gerçekleştiği söylenebilir.

184
Diğer yapısal eşitlik modellemesi örnekleri: Stewart, Conger, & Scarmella (2002) ve Shahar, Sells, & Davison (2003)
 ve Shahar, Sells, & Davison (2003)")
185
Tek göstergeli gizil değişkenler
Tek göstergeli gizil değişkenlerin olduğu bir yapısal eşitlik modelinde ölçme hatalarını hesaba katabilmek için göstergenin hata varyansı “1 – güvenirlik katsayısı”na sabitlenir. Set error variance of …

187
Sıkça Yapılan Hatalar Modeli veriyi topladıktan sonra oluşturmak
dfM < 0 olabilir. Bu durumda yeni değişkenleri analize dahil etmek için geç kalınmış olur. Uygun örneklem büyüklüğü ve güç modele bağlıdır. Önce veri toplanır sonra model kurulursa toplanan veri model için yetersiz kalabilir Gizil değişkenlere ait yeterince gösterge bulunmaması Psikometrik kalitesi yetersiz ölçme araçları kullanımı Okların (nedenselliğin) yönüne dikkat etmemek
 yönüne dikkat etmemek.")
188
Model veri uyumunu mükemmelleştirmek için modeli çok fazla karmaşık hale getirmek
Göstergelerin hatalarına içeriğe dair teorik gerekçeler olmadan kovaryanslar eklemek (metod etkisi, aynı bireyin birden çok kez ölçülmesi gibi) İçeriğe dair teorik gerekçeler olmadan göstergelerin birden çok faktörle ilişkisini kurmak Veri kontrolü yapmamak, normallik sayıltısını ve aykırı değerleri irdelememek
 İçeriğe dair teorik gerekçeler olmadan göstergelerin birden çok faktörle ilişkisini kurmak. Veri kontrolü yapmamak, normallik sayıltısını ve aykırı değerleri irdelememek.")
189
Modeli sadece modifikasyon indeksleri rehberliğinde değiştirmek
Heywood vakalarını görmezden gelmek veya negatif varyansları 0’a eşitleyerek problemi görmezden gelmek Sadece standartlaştırılmış çözümleri rapor etmek Karmaşık modelleri küçük örneklemlerle test etmek Çoklu grup uygulamalarında gizil değişkenleri standartlaştırmak SEM için önce CFA modelini test etmemek

190
Model veri uyumunu incelerken sadece genel uyum indekslerine bakıp standart hatalar matrisine bakmamak Model veri uyumunun sağlanmasını modelin kanıtlandığı şeklinde yorumlamak Model veri uyumunu modeldeki yordayıcı değişkenlerin Y değişkenlerini güçlü biçimde yordadığı şeklinde yorumlamak Denk veya denk olmayan alternatif modelleri irdelememek Okuyucuların analizleri tekrar etmelerine izin verecek gerekli bilgileri rapor etmemek

191
(Xxxx, 2008)
")
192
(Jayaram, Kannan, & Tan, 2004)
")
193
(Bentler & Chou, 1987)
")
194
:) Zafer Çepni
 Zafer Çepni")
Benzer bir sunumlar














 Kİ-KARE DAĞILIMI VE ÖZELLİKLERİ>")





>")




