Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
Bilgi Erişim Sorunu Yaşar Tonta Hacettepe Üniversitesi
yunus.hacettepe.edu.tr/~tonta/ BBY220 Bilgi Erişim İlkeleri

2
Plan Bilgi artışı Bilgi erişim sorunu Tanım
Bilgi erişim sistemlerinin mantıksal yapısı Erişim kuralları Performans ölçümleri Bilgi erişim ve Internet

3
Bilgi . . . Bilgi depolama ortamları Bilgi iletim ortamı
beyin, kültürel birikim, “dış” ortamlar Bilgi iletim ortamı dağıtık ağlar: 14 saniyede Kongre Kütüphanesi’nin içeriğini bir yerden bir yere iletmek mümkün Bilgi işleme ortamları beyin, bilgisayarlar, insanlardan daha “akıllı” makineler, “yapay beyin” Plato’nun Phaedrus’unda Mısır Kralı Theus ile yazıyı bulan bilim adamı arasında geçen konuşma hatırlatılabilir. 'İnsanlar yazıyı öğrenirlerse akıllarına unutkanlık aşılanır; bellek alıştırması yapmayı bırakırlar. Çünkü yazılı olana güvenirler; şeyleri ezbere değil, dışsal işaretler aracılığıyla hatırlamaya çalışırlar. Keşfettiğiniz şey bellek içindeğil, hatırlama için bir reçetedir. Ve size inananlara sunduğunuz şey gerçek bir hikmet değil, sadece onun görüntüsüdür. Çünkü size inananlara birçok şey söyleyerek, ama öğretmeden, onları çok biliyorlarmış gibi gösterebilirsiniz. Oysa çoğunlukla hiçbir şey bilmezler. Ve insanlar gerçek hikmetle donatılmazlarsa diğer insanlara yük olurlar.' Popper ‘Dünya uygarlığı bir savaşla yok olup, geriye kütüphanelerde saklanan nesnel bilgi içeriği kalırsa, uygarlığı yeniden kurmak mümkündür. Halbuki bu nesnel bilgi içeriği, yani kütüphaneler yok olup, yalnızca öznelerin öğrenme yeteneği kalsa, çağdaş uygarlığı yeniden inşa etmek hemen hemen imkânsızdır.’ “...tüm insanlığın belleği herkes tarafından erişilebilir hale getirilebilir, ve muhtemelen yakın bir gelecekte getirilecektir.... Bu beyin insan kafası ya da kalbi gibi kolayca tahrip edilemez. Kesin ve tam olarak Peru’da, Çin’de, İzlanda’da, Merkezi Afrika’da ya da tehlikeye ve engellemeye karşı garanti altına alınabilecek herhangi bir yerde bu beynin röprodüksiyonu yapılabilir. Bu beyin aynı zamanda hem kafataslı bir hayvanınki gibi tek bir yerde toplanabilir hem de bir amipinki gibi dağıtık ama canlı olabilir” (Dyson, 1997, s. 10). İnsan beyni Kültürel birikim “Dış” ortamlar Manyetik ve optik depolama aygıtları Dağıtık depolama kolaylıkları 2025 yılına dek makinelerin depolama gücü insan belleğininkine yaklaşacak 2030 yılına dek makineler insanlar sinirsel ağın bilgi işleme gücüne erişecek Kurzweil, “The Age of Spiritual Machines”) Beyin nakli de diğer organ nakilleri kadar popüler olacak mı? Meme büyütme operasyonları gibi beyin büyütme operasyonları yapılabilir mi?
. İnsan beyni. Kültürel birikim. Dış ortamlar. Manyetik ve optik depolama aygıtları. Dağıtık depolama kolaylıkları yılına dek makinelerin depolama gücü insan belleğininkine yaklaşacak yılına dek makineler insanlar sinirsel ağın bilgi işleme gücüne erişecek. Kurzweil, The Age of Spiritual Machines ) Beyin nakli de diğer organ nakilleri kadar popüler olacak mı Meme büyütme operasyonları gibi beyin büyütme operasyonları yapılabilir mi")
4
Kaynak: http://www.berghell.com/whitepapers/Storage%20Costs.pdf
Depolama Maliyetleri Kaynak:

5
Depolama Maliyetleri Fiyatlar her yıl %45 düşüyor 421 USD 0,42 USD
Kaynak:

6
İletim Maliyetleri Kaynak: ULAKBİM Faaliyet Raporu, 2003 (

7
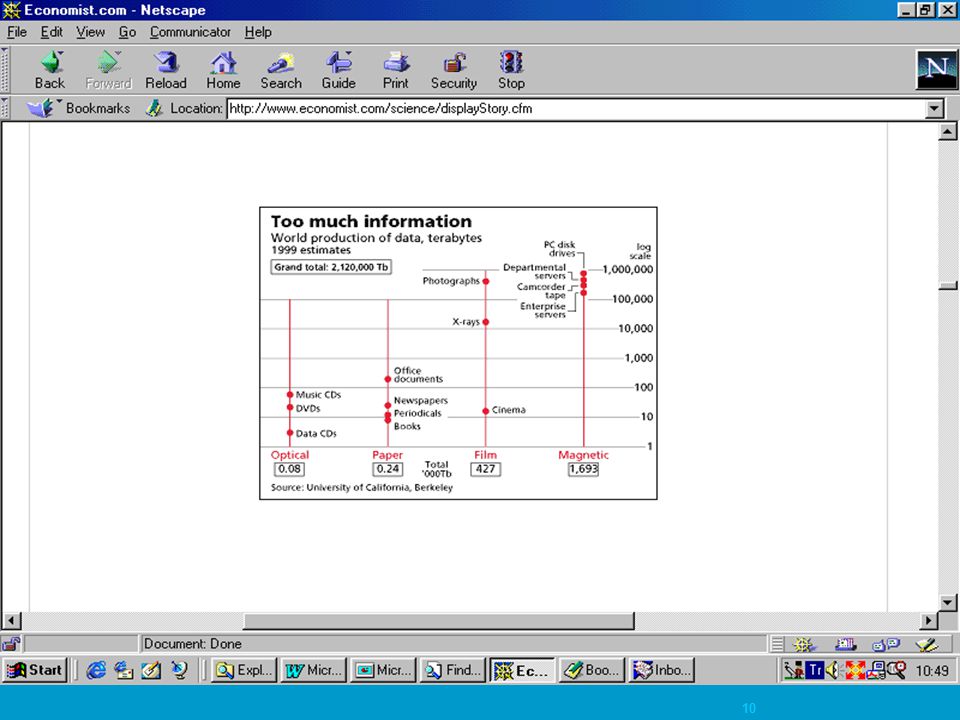
Bilgi Patlaması - 2002 5 Exabyte (5 x 1018 byte)
2002’de dünyada üretilen yeni bilgi miktarı (5 x 1018 byte) 5 Exabyte’lık bilgi = 37,000 yeni Kongre Kütüphanesi! “Yüzey web”de yaklaşık 100 milyar belge var (1670 Terabyte) var “Derin web”de 550 milyar belge var(dı) (91857 Terabyte) (“Web Growth, Web Dangers” (Editorial) NUA Internet Surveys, 31 July 2000, < Kaynak: BrightPlanet & Lyman and Varian
 5 Exabyte’lık bilgi = 37,000 yeni Kongre Kütüphanesi! Yüzey web de yaklaşık 100 milyar belge var (1670 Terabyte) var. Derin web de 550 milyar belge var(dı) (91857 Terabyte) ( Web Growth, Web Dangers (Editorial) NUA Internet Surveys, 31 July 2000, < Kaynak: BrightPlanet & Lyman and Varian.")
8
Bir Exabyte (EB) ne kadar büyük?
Kilobyte (KB) 1,000 bytes OR 103bytes 2 Kilobytes: A Typewritten page. 100 Kilobytes: A low-resolution photograph. Megabyte (MB) 1,000,000 bytes OR 106 bytes 1 Megabyte: A small novel OR a 3.5 inch floppy disk. 2 Megabytes: A high-resolution photograph. 5 Megabytes: The complete works of Shakespeare. 10 Megabytes: A minute of high-fidelity sound. 100 Megabytes: 1 meter of shelved books. 500 Megabytes: A CD-ROM. Gigabyte (GB) 1,000,000,000 bytes OR 109 bytes 1 Gigabyte: a pickup truck filled with books. 20 Gigabytes: A good collection of the works of Beethoven. 100 Gigabytes: A library floor of academic journals. Terabyte (TB) 1,000,000,000,000 bytes OR 1012 bytes 1 Terabyte: trees made into paper and printed. 2 Terabytes: An academic research library. 10 Terabytes: The print collections of the U.S. Library of Congress. 400 Terabytes: National Climactic Data Center (NOAA) database. Petabyte (PB) 1,000,000,000,000,000 bytes OR 1015 bytes 1 Petabyte: 3 years of EOS data (2001). 2 Petabytes: All U.S. academic research libraries. 20 Petabytes: Production of hard-disk drives in 1995. 200 Petabytes: All printed material. Exabyte (EB) 1,000,000,000,000,000,000 bytes OR 1018 bytes 2 Exabytes: Total volume of information generated in 1999. 5 Exabytes: All words ever spoken by human beings. Kaynak: How much information 2003, Tablo 1.1
 1,000 bytes OR 103bytes. 2 Kilobytes: A Typewritten page. 100 Kilobytes: A low-resolution photograph. Megabyte (MB) 1,000,000 bytes OR 106 bytes. 1 Megabyte: A small novel OR a 3.5 inch floppy disk. 2 Megabytes: A high-resolution photograph. 5 Megabytes: The complete works of Shakespeare. 10 Megabytes: A minute of high-fidelity sound. 100 Megabytes: 1 meter of shelved books. 500 Megabytes: A CD-ROM. Gigabyte (GB) 1,000,000,000 bytes OR 109 bytes. 1 Gigabyte: a pickup truck filled with books. 20 Gigabytes: A good collection of the works of Beethoven. 100 Gigabytes: A library floor of academic journals. Terabyte (TB) 1,000,000,000,000 bytes OR 1012 bytes. 1 Terabyte: trees made into paper and printed. 2 Terabytes: An academic research library. 10 Terabytes: The print collections of the U.S. Library of Congress. 400 Terabytes: National Climactic Data Center (NOAA) database. Petabyte (PB) 1,000,000,000,000,000 bytes OR 1015 bytes. 1 Petabyte: 3 years of EOS data (2001). 2 Petabytes: All U.S. academic research libraries. 20 Petabytes: Production of hard-disk drives in Petabytes: All printed material. Exabyte (EB) 1,000,000,000,000,000,000 bytes OR 1018 bytes. 2 Exabytes: Total volume of information generated in Exabytes: All words ever spoken by human beings. Kaynak: How much information 2003, Tablo 1.1.")
9
Bilgi Artışı Tablo ’de dünyada üretilen özgün dijital bilgi üretimi. İyimser tahminlerde bilginin dijital olarak tarandığı varsayıldı, alt tahminlerde dijital içeriğin sıkıştırıldığı varsayıldı. Depolama ortamı 2002 Üst tahmin (Terabyte olarak) Alt tahmin (Terabyte olarak) Üst tahmin Alt tahmin % Değişim Üst tahminler Kâğıt 1,634 327 1,200 240 %36 Film 420,254 76,69 431,690 58,209 %-3 Manyetik 3,416,230 2,779,760 2,073,760 %87 Optik 103 51 81 29 %28 TOPLAM 5,609,121 3,416,281 3,212,731 2,132,238 %74.5 Kaynak: Lyman ve Varian
 Alt. tahmin (Terabyte olarak) Üst tahmin Alt tahmin. % Değişim Üst tahminler. Kâğıt. 1, , %36. Film. 420, , , ,209. %-3. Manyetik ,416,230. 2,779,760. 2,073,760. %87. Optik %28. TOPLAM. 5,609,121. 3,416,281. 3,212,731. 2,132,238. %74.5. Kaynak: Lyman ve Varian.")
11
Bilgi Miktarı 5,4 Exabyte (milyar x milyar byte: 54 milyar Economist dergisinin içeriğine eşit) ABD’de her yıl 80 milyar fotoğraf çekiliyor 2 milyar röntgen filmi çekiliyor Günde 610 milyar e-posta mesajı gönderiliyor Her yıl 15 trilyon sayfa yazıcılardan çıktı alınıyor Peter Lyman ve Hal Varian’ın araştırması (The Economist, 26 Mart 2001 sayısı)
")
12
Bilgi Patlaması

13
5 Exabayt 161 Exabayt 161 Exabayt ne kadar eder?
Dünyadan Güneşe kadar uzanan 12 raf kitap Kişi başına 6 ton kitap Dörtte biri orijinal bilgi, gerisi ikileme. Dörtte biri 40 Exabayt eder. Oysa ’de toplam yeni bilgi miktarı 40 Exabayt hesaplanmıştı. THE UNSTRUCTURED DATA PROBLEM Over 95% of the digital universe is "unstructured data" – meaning its content can't be truly represented by its location in a computer record, such as name, address, or date of last transaction. Digital images, voice packets, and the musical notes in an MP3 file would be considered unstructured data. In organizations, unstructured data accounts for more than 80% of all information. There may be information about the content, such as when it was captured – e.g., the time stamp on a camcorder clip – or its compression scheme, address from which it was sent or received if indeed it was, or file size. But that information, or "metadata," is generally not enough to determine what is

14
Depolama Kapasitesi IDC estimates that in 2006, just the traffic from one person to another – i.e., excluding spam – accounted for 6 exabytes (or 3%) of the digital universe. … The cost of not responding to the avalanche of information can add up, yet not be immediately visible to CEOs and CFOs. In surveys of U.S. companies, we have found that information workers spend 14.5 hours per week reading and answering , 13.3 hours creating documents, 9.6 hours searching for information, and 9.5 hours analyzing information. We estimate that an organization employing 1,000 knowledge workers loses $5.7 million annually just in time wasted having to reformat information as they move among applications. Not finding information costs that same organization an additional $5.3 million a year. Adopting a comprehensive and disciplined approach to managing information and understanding its value is a key to reducing the hidden – and not so hidden – costs associated with the information explosion.
 of the digital universe. … The cost of not responding to the avalanche of information can. add up, yet not be immediately visible to CEOs and CFOs. In. surveys of U.S. companies, we have found that information. workers spend 14.5 hours per week reading and answering , 13.3 hours creating documents, 9.6 hours searching for. information, and 9.5 hours analyzing information. We estimate that an organization employing 1,000 knowledge. workers loses $5.7 million annually just in time wasted having. to reformat information as they move among applications. Not. finding information costs that same organization an additional. $5.3 million a year. Adopting a comprehensive and disciplined approach to. managing information and understanding its value is a key to. reducing the hidden – and not so hidden – costs associated with. the information explosion.")
15
Bilgi Erişim Sorunu Wells, “World Encyclopedia” (1936)
Bush, “As we may think,” Atlantic Monthly, (1945) Memex (memory expansion) “bilgi erişim” (IR) teriminin ilk kez kullanımı (Calvin Mooers, 1952) Otomatik dizinleme – KWIC/KWOC (Luhn, 1958) Boole modeli (Lockheed, 1960’lar) Mantıksal model (Mooers, Cooper & Maron, Van Rijsbergen, ) Olasılık modeli (Maron-Kuhns, 1960; Robertson-Jones, 1976; Robertson-Maron-Cooper, 1982; Croft, 1979 ) Vektör uzayı modeli (Gerard Salton, 1961) İstatistiksel ağırlıklandırma (tf*idf, 1970’ler) Dil modelleri (Ponte-Croft, 1998) Performans ölçümleri Cranfield, Medlars, SMART, STAIRS, TREC, (Cleverdon, Lancaster, Salton, Blair-Maron, Harman) Bilginin giderek artan fragmantasyonu Bütüncül ya da “büyük resim” düşüncesinin ifadesi 1. Sistem felsefesi Genel Sistem Kuramı Ludwig von Bertalanffy, 19. Yüzyıl ortaları Sistem analizi C.A. Cutter, 1876, Kataloğun amaçları 2. Bilim felsefesi Mantıksal pozitivizm Doğrulanabilirlik Değişkenlerin işletimselleştirilmesi Farklı değişkenler arasında ilişki kurma Anma-duyarlık ilişkisi (Cyril Cleverdon, 1950’ler) Dizin spesifisitesi, dizin derinliği, sözdağarı büyüklüğü gibi etmenlerin erişim performansına etkileri 3. Dil felsefesi Doğrulanabilirlik dilbilimsel bir ilke Dilbilimsel çözümleme felsefesi (Wittgenstein) Bir sözcüğün anlamını belirleyen onun kullanım biçimidir
 Memex (memory expansion) bilgi erişim (IR) teriminin ilk kez kullanımı (Calvin Mooers, 1952) Otomatik dizinleme – KWIC/KWOC (Luhn, 1958) Boole modeli (Lockheed, 1960’lar) Mantıksal model (Mooers, Cooper & Maron, Van Rijsbergen, ) Olasılık modeli (Maron-Kuhns, 1960; Robertson-Jones, 1976; Robertson-Maron-Cooper, 1982; Croft, 1979 ) Vektör uzayı modeli (Gerard Salton, 1961) İstatistiksel ağırlıklandırma (tf*idf, 1970’ler) Dil modelleri (Ponte-Croft, 1998) Performans ölçümleri. Cranfield, Medlars, SMART, STAIRS, TREC, (Cleverdon, Lancaster, Salton, Blair-Maron, Harman) Bilginin giderek artan fragmantasyonu. Bütüncül ya da büyük resim düşüncesinin ifadesi. 1. Sistem felsefesi. Genel Sistem Kuramı. Ludwig von Bertalanffy, 19. Yüzyıl ortaları. Sistem analizi. C.A. Cutter, 1876, Kataloğun amaçları. 2. Bilim felsefesi. Mantıksal pozitivizm. Doğrulanabilirlik. Değişkenlerin işletimselleştirilmesi. Farklı değişkenler arasında ilişki kurma. Anma-duyarlık ilişkisi (Cyril Cleverdon, 1950’ler) Dizin spesifisitesi, dizin derinliği, sözdağarı büyüklüğü gibi etmenlerin erişim performansına etkileri. 3. Dil felsefesi. Doğrulanabilirlik dilbilimsel bir ilke. Dilbilimsel çözümleme felsefesi (Wittgenstein) Bir sözcüğün anlamını belirleyen onun kullanım biçimidir.")
16
“Memex ve Türkler” “The owner of the memex, let us say, is interested in the origin and properties of the bow and arrow. Specifically he is studying why the short Turkish bow was apparently superior to the English long bow in the skirmishes of the Crusades. He has dozens of possibly pertinent books and articles in his memex. First he runs through an encyclopedia, Thus he goes, building a trail of many items. . . Thus he builds a trail of his interest through the maze of materials available to him. And his trails do not fade. Several years later, his talk with a friend turns to the queer ways in which a people resist innovations, even of vital interest. He has an example, in the fact that the outraged Europeans still failed to adopt the Turkish bow. In fact he has a trail on it. A touch brings up the code book It is an interesting trail, pertinent to the discussion. So he sets a reproducer in action, photographs the whole trail out, and passes it to his friend for insertion in his own memex, there to be linked into the more general trail.”

17
Bilgi Erişim “bilgi toplama, sınıflama, kataloglama, depolama, büyük miktardaki verilerden arama yapma ve bu verilerden istenen bilgiyi üretme (veya gösterme) tekniği ve süreci”
 tekniği ve süreci")
18
Bilgi Erişimin Entellektüel Temelleri
Sistem felsefesi Bilim felsefesi Dil felsefesi Bilginin giderek artan fragmantasyonu Bütüncül ya da “büyük resim” düşüncesinin ifadesi 1. Sistem felsefesi Genel Sistem Kuramı Ludwig von Bertalanffy, 19. Yüzyıl ortaları Sistem analizi C.A. Cutter, 1876, Kataloğun amaçları 2. Bilim felsefesi Mantıksal pozitivizm Doğrulanabilirlik Değişkenlerin işletimselleştirilmesi Farklı değişkenler arasında ilişki kurma Anma-duyarlık ilişkisi (Cyril Cleverdon, 1950’ler) Dizin spesifisitesi, dizin derinliği, sözdağarı büyüklüğü gibi etmenlerin erişim performansına etkileri 3. Dil felsefesi Doğrulanabilirlik dilbilimsel bir ilke Dilbilimsel çözümleme felsefesi (Wittgenstein) Bir sözcüğün anlamını belirleyen onun kullanım biçimidir
 Dizin spesifisitesi, dizin derinliği, sözdağarı büyüklüğü gibi etmenlerin erişim performansına etkileri. 3. Dil felsefesi. Doğrulanabilirlik dilbilimsel bir ilke. Dilbilimsel çözümleme felsefesi (Wittgenstein) Bir sözcüğün anlamını belirleyen onun kullanım biçimidir.")
19
Dil Felsefesi ve Bilgi Erişim
Bilgi düzenleme ve bilgi erişim de dil kullanımının özel bir türü Sistematik dizinleme (J. Otto Kaiser) Dilbilimsel yapılar Sözdağarı Anlambilim Sözdizimi Kataloglama, sınıflama, dizinleme Basit terimler anlamsal kategorilere ayrıldı. Bu kategorilere göre tanımlanmış sözdizim kuralları kullanılarak birleşik terimler inşa edildi
 Dilbilimsel yapılar. Sözdağarı. Anlambilim. Sözdizimi. Kataloglama, sınıflama, dizinleme. Basit terimler anlamsal kategorilere ayrıldı. Bu kategorilere göre tanımlanmış sözdizim kuralları kullanılarak birleşik terimler inşa edildi.")
20
Sınıflama Kuramı Sınıflama dile dayanıyor Dil belirsizlikler içeriyor
Kavramlar üzerinde anlaşma sağlamak zor Domates “meyve” mi “sebze” mi? George Lakoff, “Women, Fire and Dangerous Things” “Alternatif tıp” hangi konuya girer? Felsefe? Din? Sağlık ve tıp? Webster’da “domates” şöyle tanımlanıyor: “kırmızı ya da sarımtırak sulu bir meyve, sebze olarak kullanılır, bitki olarak yumuşak, kabuksuz meyvedir” Aslında teknik olarak domates bir meyve (berrey), ama 1893’de ABD Anayasa Mahkemesi domatesin sebze olduğuna karar veriyor. West Indies’ten domates ithal eden John Nix, sebze ithaline konulan %10’luk gümrük vergisini ödememek için dava açıyor. Nix domatesin meyve olduğunu savunuyor. Mahkeme ise domatesin meyve gibi tatlı olarak değil de sebze olarak tüketildiğini göz önünde bulundurarak domatesin sebze olduğuna hükmediyor. Kaynak: Denise Grady, “Best Bite of Summer”, Self 19(7): , July 1997’den aktaran: Louis Rosenfeld and Peter Norville, Information architecture for the World Wide Web. Sebastopol, CA: O’Reilly, 1998. (Aslında ABD Anayasa Mahkemesi daha Wittgenstein doğmadan Wittgensteincı bir yorum yapmış burada: bir sözcüğün anlamını kullanım belirler. Belgeleri tanımlamak mekanik bir süreç değil Entellektüel – otomatik dizinleme (“bağıntılı dizinleme”) Belli sözcüklerin varlığı/yokluğu İstatistiksel dizinleme Dildeki belirsizlik Tanımlar üzerinde anlaşma Terimlerin sınıflandırılması
, ama 1893’de ABD Anayasa Mahkemesi domatesin sebze olduğuna karar veriyor. West Indies’ten domates ithal eden John Nix, sebze ithaline konulan %10’luk gümrük vergisini ödememek için dava açıyor. Nix domatesin meyve olduğunu savunuyor. Mahkeme ise domatesin meyve gibi tatlı olarak değil de sebze olarak tüketildiğini göz önünde bulundurarak domatesin sebze olduğuna hükmediyor. Kaynak: Denise Grady, Best Bite of Summer , Self 19(7): , July 1997’den aktaran: Louis Rosenfeld and Peter Norville, Information architecture for the World Wide Web. Sebastopol, CA: O’Reilly, (Aslında ABD Anayasa Mahkemesi daha Wittgenstein doğmadan Wittgensteincı bir yorum yapmış burada: bir sözcüğün anlamını kullanım belirler. Belgeleri tanımlamak mekanik bir süreç değil. Entellektüel – otomatik dizinleme ( bağıntılı dizinleme ) Belli sözcüklerin varlığı/yokluğu. İstatistiksel dizinleme. Dildeki belirsizlik. Tanımlar üzerinde anlaşma. Terimlerin sınıflandırılması.")
21
“Well, it all started with an unsuccessful subject search”

22
Bilgi Erişimin Temel İkilemi
“Hakkında bilgi bulmak için bilmediğin bir şeyi tanımlama gereği” (Hjerrpe) Durum “sözlük” kelimesinin anlamını bilmeyen bir kişinin içinde bulunduğu çıkmaza benzetilebilir. Sözlük kelimesinin anlamını bilmiyorsa bilmediğini öğrenmek için sözlüğe bakmayı nasıl akıl edecek?
 Durum sözlük kelimesinin anlamını bilmeyen bir kişinin içinde bulunduğu çıkmaza benzetilebilir. Sözlük kelimesinin anlamını bilmiyorsa bilmediğini öğrenmek için sözlüğe bakmayı nasıl akıl edecek")
23
Bilgi Keşfetme, Tanımlama, Düzenleme ve Erişim
organizing information: to compile an encyclopedic compendium of knowledge for the purpose of information retrieval Erişim Erişim

24
Belge Erişim Sisteminin Mantıksal Düzenlemesi
Belgeler Kullanıcılar Gömü - Sözlük Sorgu formülasyonu Dizinleme Dizin tutanakları Erişim kuralı Formel sorgu cümlesi Kaynak: Maron, 1984

25
İdeal Bilgi Erişim Sistemi
İlgili belgelerin tümüne ve salt ilgili belgelere erişim sağlamalı “İlgililik” kavramı Nesnel ilgililik Öznel ilgililik Birbirine benzeyen bilgileri bir araya getirmek, benzemeyenleri ayırmak

26
Erişim Kuralları Boole mantığı Vektör uzayı modeli Olasılık modeli
Set kuramına dayanıyor. Boole işleçleri –VE, VEYA, DEĞİL- kullanılıyor Vektör uzayı modeli (D,Q) = (tkxqk) / (tk)2 x (qk) 2 tk = k teriminin belgedeki değeri qk = k teriminin sorgudaki değeri Olasılık modeli P (ilgili) = n / N P( ilgili) = 1 – P(ilgili) = N – n / N n = ilgili belge sayısı N = toplam belge sayısı İstatistiksel ağırlıklandırma (tf*idf) Ağırlıklandırma ilkesi: İlgili belgelerde sık AMA derlemin tamamında seyrek geçen terimleri daha yüksek ağırlıklandır
 = (tkxqk) / (tk)2 x (qk) 2. tk = k teriminin belgedeki değeri. qk = k teriminin sorgudaki değeri. Olasılık modeli. P (ilgili) = n / N. P( ilgili) = 1 – P(ilgili) = N – n / N. n = ilgili belge sayısı. N = toplam belge sayısı. İstatistiksel ağırlıklandırma (tf*idf) Ağırlıklandırma ilkesi: İlgili belgelerde sık AMA derlemin tamamında seyrek geçen terimleri daha yüksek ağırlıklandır. ")
27
Benzerlik Skorunun Hesaplanması
Pekmez Slide 38 of 79 Zile

28
Bilgi Erişim Sistemleri Mükemmel Değil!
N y v x u İLGİLİ ERİŞİLEN v tipi hatalar u tipi hatalar

29
Bilgi Erişim Performansı
İLGİLİ İLGİSİZ ERİŞİLEN x u n1 ERİŞİLE-MEYEN v y n2 N y v x u İLGİLİ ERİŞİLEN Duyarlık = x / n1 Erişilen ilgili belgelerin erişilen tüm belgelere oranı Anma = x / n2 Erişilen ilgili belgelerin tüm ilgili belgelere oranı Posa = u / u + y Erişilen ilgisiz belgelerin tüm ilgisiz belgelere oranı Genellik = n2 / N Tüm dermedeki ilgili belgelerin oranı

30
Diğer Performans Ölçümleri
Kapsama Oranı: |Rk| / U Gerçekte erişilen ilgili belgelerin kullanıcının ilgili olduğunu önceden bildiği belgelere oranı Yenilik Oranı: |Ru| / |Ru| + |Rk| Gerçekte erişilen ilgili belgelerin kullanıcının ilgili olduğunu önceden bilmediği belgelere oranı U: kullanıcının ilgili olduğunu önceden bildiği belgeler seti Rk: Erişilen ve kullanıcının önceden ilgili olduğunu bildiği belgelerin sayısı Ru: Erişilen ve kullanıcının önceden ilgili olduğunu bilmediği belgelerin sayısı

31
Normalleştirilmiş Sıralama
1 2 3 4 5 6 7 8 9 Sıra1 + - Sıra2 Sıra3 Duyarlık üç arama için de 5/9 Hangisini tercih edersiniz?

32
Yetersizlik Aksiyomları I
Bir bilgi ihtiyacı bağlamdan bağımsız olarak ifade edilemez. Bir makineye bir soruyu uygun arama terimlerine çevirmesini öğretmek olanaksızdır. Bir belgenin ilgili olup olmaması görülen diğer belgelere bağlıdır. Bütün ilgili belgelerin bulunup bulunmadığını doğrulamak asla mümkün değildir. Makineler anlamı tanıyamaz -> entellektüel dizinleme kadar başarılı değildir, vs.

33
Yetersizlik Aksiyomları II
Sözcük sıklığı istatistikleri ne anlamı temsil edebilir, ne de anlam yerine geçebilir. Bir bilgi erişim sisteminin bir tekrarlı süreci destekleme yeteneği insanlar tarafından sadece bir kez yapılan ilgililik değerlendirmesiyle değerlendirilemez. Ya sağlam ilgililik değerlendirmesi ya da çok etkili mekanik süreçlere sahip olabilirsiniz, ama ikisine birden asla. Yani, tutarlı bir şekilde etkin olan tamamen otomatik dizinleme ve erişim mümkün değildir. Kaynak: Swanson, 1988

34
Internet Zaman ve mekân engelinin ortadan kalkması Bilgi kaynaklarına ve hizmetlerine günde 24 saat haftada 7 gün uzaktan erişim “Anında memnuniyet”

35
Bilgi Erişim ve Internet...
“Yangın hortumundan su içmek” “Dijital belgeler”: devingen, sınırları belirsiz, kendi kendini değiştirebilen belge Dizinleme ve bilgi erişim teknikleri yetersiz Erişim doğrusal ve hantal İnsan beyninde ise dizinleme ve erişim “bağıntılı” Acaba yakın gelecekte taklit edilebilir mi? Ses, koku, vs. bilgisine erişim? Beyin dışında kayıtlı bilgiler insanın düşünme ve sorun çözme gücünün bir parçası haline getirilebilir mi? Oysa beyin dışında kayıtlı bilgileri günlük karar alma ve üretim sürecinin bir parçası haline getirmek, gerektiğinde etkin bir biçimde yararlı bilgilere erişmek gerekli Yakın gelecekte bilgiye “dokunup” bilgiyi şekillendirebilecek miyiz?

Benzer bir sunumlar






 27.03.2008.>")












