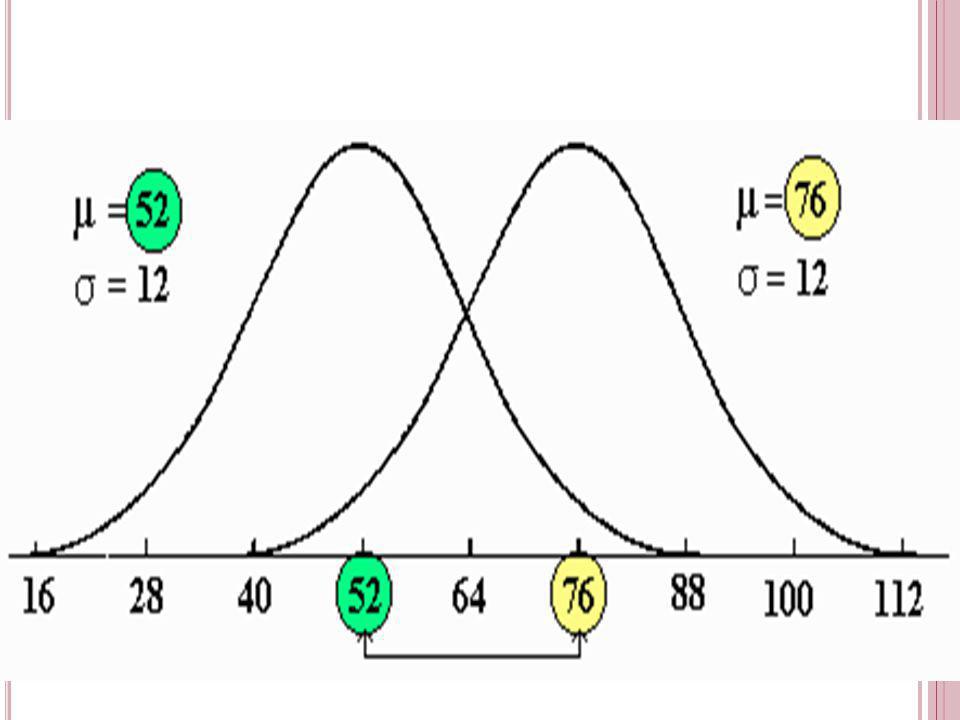
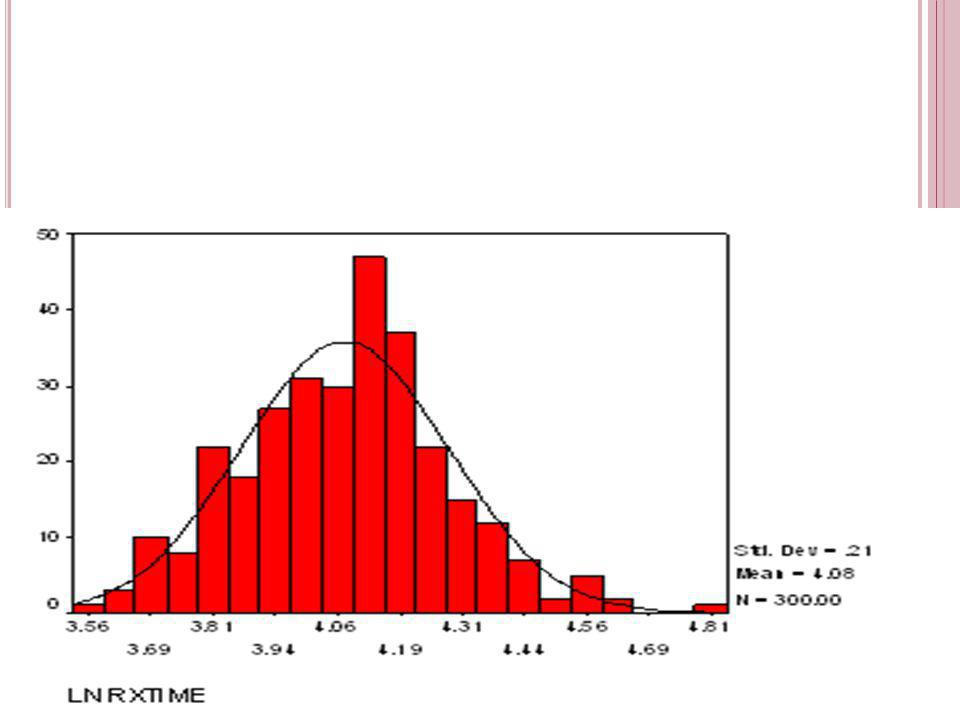
Sunuyu indir
Sunum yükleniyor. Lütfen bekleyiniz

1
PSİKİYATRİ VE BİYOİSTATİSTİK
Gülşah Seydaoğlu Güz okulu, Ankara Eylül 2010

2
Bilim Anlar Bebeklik Açıklar Çocukluk Kestirir Gençlik
Kontrol eder Olgunluk

3
Nedir? Nerede kullanılır?
CANLILARIN ÖZELLİKLERİ VE BUNLARI ETKİLEYEN ÖGELER ARASINDAKİ NEDENSELLİK BAĞLARINI, YÖNTEMBİLİMSEL DEĞERLENDİRME KURGULARI VE OLASILIK KURAMI ÇERÇEVESİNDE AÇIKLAMAYA ÇALIŞAN BİLİM DALIDIR.... Hekim, deneyimlerini ve bilimsel tıbbi gerçekleri istatistik bilimi yardımıyla daha belirgin ve güvenilir aktarır. Makale – yayın – araştırma – tez hazırlar

4
Herkes hata yapar Dünyanın en saygın ve en çok okunan yayınlarında da dahi kötü tasarlanmış, yanlış analizler uygulanmış makale oranı yüksektir. Bir araştırma sonucuna göre; BMJ, The NEJ of Medicine, The Lancet gibi dergilerinde bulunduğu 30 dergide yayınlanan 4200 makalenin, yalnızca %20’sinin çalışma düzeni ve istatistik analiz olarak geçerli olduğu, Kötü deney düzeni ve istatistik analizli çalışmaların %80’inde pozitif bulgu varken iyi çalışmaların yalnızca %25’i pozitif (ilaç etkili, tanı geçerli) bulgu verir.
 bulgu verir.")
5
Normallik sınırı ve p değeri
Toplum normlarına göre, denetlenen farkın normal yada anormal (anlamlı farklı) olduğu, başlangıçta kabul edilen güven düzeyi (%95) temelinde yargılanır. Bahsedilen güven düzeyinin dışında kalan olasılık yanılgı payı ( =%5) olarak değerlendirilir ve uygulanan tüm istatistiksel testlerin sonucu bu p olasılığına kadar indirgenerek yorumlanır.
 olduğu, başlangıçta kabul edilen güven düzeyi (%95) temelinde yargılanır. Bahsedilen güven düzeyinin dışında kalan olasılık yanılgı payı ( =%5) olarak değerlendirilir ve uygulanan tüm istatistiksel testlerin sonucu bu p olasılığına kadar indirgenerek yorumlanır.")
6
Gözlem-Sezgi Hipotez-Varsayım Gerçekleme Genelleme
Bilimsel araştırma basamakları Gözlem-Sezgi Hipotez-Varsayım Gerçekleme A priori Ön bilgi Genelleme

7
Hipotez- varsayımın kurgulanması
Hipotez, araştırmacının kendi bilgi birikiminden veya daha önce yapılmış gözlemlerden faydalanarak önerilir. Örneğin tedavi grupları arasında fark vardır. H1 (alternatif varsayım); araştırmacının geçerliliğini denetleyeceği başlangıçta doğru olarak kabul ettiği varsayım. H0 (Sıfır Varsayımı); H1 Varsayımının doğru olmadığını önesüren doğal varsayım
; araştırmacının geçerliliğini denetleyeceği başlangıçta doğru olarak kabul ettiği varsayım. H0 (Sıfır Varsayımı); H1 Varsayımının doğru olmadığını önesüren doğal varsayım.")
8
Varsayım Varsayım Para ile mutluluk arasında ilişki vardır
Para arttıkça mutluluk artar Para arttıkça mutluluk azalır Para ile mutluluk arasında ilişki yoktur. Kadınlarla erkekler arasında dedikodu yapma oranları farklıdır Kadınlar erkeklerden daha çok dedikodu yapar Erkekler kadınlardan daha çok dedikodu yapar Kadınlar ve erkekler arasında fark yoktur

9
Varsayım Varsayım Para ile mutluluk arasında ilişki vardır (r ≠ 0)
Para arttıkça mutluluk artar (r > 0) + Para arttıkça mutluluk azalır (r < 0) - Para ile mutluluk arasında ilişki yoktur. (r = 0) Kadınlarla erkekler arasında dedikodu yapma oranları farklıdır (m1 ≠ m2) Kadınlar erkeklerden daha çok dedikodu yapar (m1 < m2) Erkekler kadınlardan daha çok dedikodu yapar (m1 > m2) Kadınlar ve erkekler arasında fark yoktur (m1 = m2)
 + Para arttıkça mutluluk azalır (r < 0) - Para ile mutluluk arasında ilişki yoktur. (r = 0) Kadınlarla erkekler arasında dedikodu yapma oranları farklıdır (m1 ≠ m2) Kadınlar erkeklerden daha çok dedikodu yapar (m1 < m2) Erkekler kadınlardan daha çok dedikodu yapar (m1 > m2) Kadınlar ve erkekler arasında fark yoktur (m1 = m2)")
10
İstatistiksel değerlendirme
Hangi varsayım doğru? karar verilecek İstatistik analiz sonunda: p< ÇIKARSA , H1 DOĞRU KABUL EDİLİR Yani hipotezimiz varsayımımız (çok düşük bir yanılma payı ile) genel geçerliliği olan yeni bir sonuç olarak kabul edilir. p> 0.05 çıkarsa: H0 KABUL EDİLİR (varsayımımız kabul edilemeyecek kadar çok yanılmaktadır) KABUL RED %95 %2,5
 genel geçerliliği olan yeni bir sonuç olarak kabul edilir. p> 0.05 çıkarsa: H0 KABUL EDİLİR. (varsayımımız kabul edilemeyecek kadar çok yanılmaktadır) KABUL. RED. %95. %2,5.")
11
Karar Hataları EVRENSEL GERÇEK ARAŞTIRMA SONUCU KARAR Ho DOĞRU
Ho Yanlış H1 DOĞRU Kabul Ho Red 2.Tip HATA () 1.Tip HATA () DOĞRU (1- =Power) 1.TİP HATA() Gerçekte FARKSIZLARA yanlış olarak FARKLI denmesi. 2.TİP HATA() Gerçekte FARKLILARA yanlış olarak FARKSIZ denmesi.
 1.Tip. HATA. () DOĞRU. (1- =Power) 1.TİP HATA() Gerçekte FARKSIZLARA yanlış olarak FARKLI denmesi. 2.TİP HATA() Gerçekte FARKLILARA yanlış olarak FARKSIZ denmesi.")
12
Gerçekleme Uygun kurgunun tasarlanması
Değişkenlerin Saptanması -Değişken sayısının belirlenmesi Verilerin doğru ve güvenilir toplanması (Veri girişi) Verilerin uygun analizi Verilerin doğru sunumu
 Verilerin uygun analizi. Verilerin doğru sunumu.")
13
1-Araştırma Tasarımları
A- Gözlemsel Araştırmalar 1-Tanımlayıcı Korelasyon çalışmaları Vaka raporları, Vaka serileri, Kesitsel (Cross-sectional ) taramalar 2-Analitik Kohort Vaka kontrol B-Deneysel Araştırmalar 1-Kontrollü çalışmalar randomize non randomize 2-Kontrolsüz Çalışmalar
 taramalar. 2-Analitik. Kohort. Vaka kontrol. B-Deneysel Araştırmalar. 1-Kontrollü çalışmalar. randomize. non randomize. 2-Kontrolsüz Çalışmalar.")
14
OLGU - KONTROL ÇALIŞMASI
Çalışmanın başlangıcı Etken + Olgu Etken - Etken + Kontrol Etken-

15
KOHORT ÇALIŞMASI İzlenen Grup Etken + Çalışmanın başlangıcı Hasta
Sağlam İzlenen Grup Hasta Etken - Sağlam Çalışmanın yönü

16
Rasgele Yerleştirilmiş Kontrollü Çalışma - RCT
Hastalık Deneysel tedavi İyileşme Uygun hastalar Randomizasyon Hastalık Standart tedavi İyileşme Araştırmanın yönü

17
SİSTEMATİK DERLEME META-ANALİZ
A çalışması B çalışması C çalışması D çalışması Meta-analiz

18
Soru, araştırma türünü belirler
SORU TİPİ ÇALIŞMA TİPİ Prevelans, insidans Tanımlayıcı -Kesitsel Tanı Tanı testleri Tedavi RCT Prognoz Kohort, olgu-kontrol, RCT Zarar/Etio Kohort, olgu-kontrol, RCT Sistematik Derleme Meta Analiz

19
SİSTEMİK DEĞERLEND. ve META ANALİZLER RANDOMİZE KONTROLÜ ÇİFT KÖR Ç.
KANIT PİRAMİDİ SİSTEMİK DEĞERLEND. ve META ANALİZLER RANDOMİZE KONTROLÜ ÇİFT KÖR Ç. KOHORT Ç. OLGU-KONTROL Ç. OLGU SERİLERİ OLGU SUNUMLARI UZMAN GÖRÜŞÜ HAYVAN DENEYLERİ İNVİTRO DENEYLER

20
Kanıt düzeyleri ve önem dereceleri
1 2 a 2 b 3 a 3 b 4 5 Sistematik derleme – RKÇ Sistematik derleme – kohort Kohort çalışmalar veya düşük kalite RKÇ lar (izlemde kalan % 80) Sistematik derleme – olgu-kontrol çalışmalar Olgu-kontrol çalışmalar Olgu serileri veya düşük kalitede olgu-kontrol ve kohort çalışmalar Uzman görüşü (eleştirel değer biçmeye dayalı olmayan)
 Sistematik derleme – olgu-kontrol çalışmalar. Olgu-kontrol çalışmalar. Olgu serileri veya düşük kalitede olgu-kontrol ve kohort çalışmalar. Uzman görüşü (eleştirel değer biçmeye dayalı olmayan)")
21
İstatistikçiye " Eşiniz Nasıl ? " Diye Sormuşlar ..
"Kime Kıyasla !!!" Diye Yanıtlamış ... Kontrol grubu var mı? İstatistikçinin İkiz Oğulları Olmuş. Birini Sünnet Ettirmiş , Diğerini Ettirmemiş; Kontrol Kümesi Olarak Saklamış...

22
Kontrol ve deney grubu benzer mi?

23
Kontrol Kontrollü çalışmalarda sıklıkla kullanılan yöntem, bağımsız eşzamanlı kontrol grubu oluşturmaktır. İki grup denek vardır. Deney grubuna (experimental group) araştırma konusu olan tanı ya da tedavi yöntemi uygulanırken, kontrol grubuna plasebo ya da diğer yöntem uygulanır. Kontrol grubunun uygulanan yöntemdeki farklılık dışında deney grubuna benzer olması gerekir.
 araştırma konusu olan tanı ya da tedavi yöntemi uygulanırken, kontrol grubuna plasebo ya da diğer yöntem uygulanır. Kontrol grubunun uygulanan yöntemdeki farklılık dışında deney grubuna benzer olması gerekir.")
24
Körleme?

25
Körleme Tek kör Çift kör Üçlü kör Hasta bilmiyor Hasta Hekim bilmiyor
İstatistikçi bilmiyor

26
Randomizasyon

27
Randomizasyon Tüm elemanların her iki gruba girmesi için eşit şansa sahip olması Her grubun tedavi veya kontrol grubu olma konusunda eşit şansa sahip olması Taraf tutmanın önlenmesi amaçlanır. Bunun için: Kurra çekmek, yazı tura atmak, rasgele sayılar tablosu, bilgisayarda hazırlanmış rasgele sayılar tablosu vb. kullanılır.

28
Önbilgiler, Öngörüler, Kısıtlar
KAÇ ÖRNEK ALALIM? Önbilgiler, Öngörüler, Kısıtlar Örnek Toplumu temsil etmeli ve yeterli sayıda olmalıdır. Örnek birimler rasgele seçilmelidir. Toplumdaki her birimin örneğe seçilme şansları eşit olmalıdır. Sosyo-kültürel farklılıklar örneğe yansımalıdır. Toplumun alt kesimlerinin değişken yoğunluklarına göre örnekte temsilleri yoğunluklar ile orantılı olmalıdır. Prevalans/İnsidans araştırmalarında Az görülen hastalık için ÇOK, sık görülen hastalık için AZ örnek. Sahada Homojen dağılan hastalık için AZ, Heterojen dağılan hastalık için ÇOK örnek.

29
Önbilgiler, Öngörüler, Kısıtlar
KAÇ ÖRNEK ALALIM? Önbilgiler, Öngörüler, Kısıtlar Toplum oranını tahmin etmek için ne kadar kesinlik gerekiyor? Çok yakın (kesin) tahmin için ÇOK, Yaklaşık tahmin için AZ örnek; Tahminler için güven aralığı (olasılık) yüzde kaç alınmalıdır? %95 güvenli değerler için AZ, %99.9 güvenli değerler için ÇOK örnek; Araştırma PAHALI bir uygulama ise AZ, UCUZ ise ÇOK örnek; Araştırma yeni bir teori, teknik, yöntem geliştirme ise AZ örnek, Tekrar deneyleri ise ÇOK örnek;
 tahmin için ÇOK, Yaklaşık tahmin için AZ örnek; Tahminler için güven aralığı (olasılık) yüzde kaç alınmalıdır %95 güvenli değerler için AZ, %99.9 güvenli değerler için ÇOK örnek; Araştırma PAHALI bir uygulama ise AZ, UCUZ ise ÇOK örnek; Araştırma yeni bir teori, teknik, yöntem geliştirme ise AZ örnek, Tekrar deneyleri ise ÇOK örnek;")
30
Örneklem Büyüklüğünün hesaplanması
Olayların görülüş sıklığını ya da olayların ortalamasını incelemek için örnekleme alınacak birey sayısı; evrendeki kişi sayısının bilinip bilinmemesine göre değişik formüllerle hesaplanır. Bu n sayısı ile elde edilecek sonuçların ne kadar güvenilir olduğu güç analizi ile denetlenir. Genel olarak örneklem büyüklükleri; N büyüdükce; Yapılacak sapma daraldıkca ve Yapılması istenen hata küçüldükce ARTAR.

31
Formüller Örneklem büyüklüğünü belirlemek için; - Hedef kitledeki birey sayısı bilinmiyorsa n = t2pq / d Hedef kitledeki birey sayısı biliniyorsa n= N t2pq / d2 (N-1) + t2pq formülleri kullanılır. Formüllerde; N : Hedef kitledeki birey sayısı n : Örnekleme alınacak birey sayısı p : İncelenen olayın görülüş sıklığı (gerçekleşme olasılığı) q : İncelenen olayın görülmeyiş sıklığı (gerçekleşmeme olasılığı) t : Belirli bir anlamlılık düzeyinde, t tablosuna göre bulunan teorik değer d : Olayın görülüş sıklığına göre kabul edilen ? örnekleme hatasıdır.
 + t2pq formülleri kullanılır. Formüllerde; N : Hedef kitledeki birey sayısı n : Örnekleme alınacak birey sayısı p : İncelenen olayın görülüş sıklığı (gerçekleşme olasılığı) q : İncelenen olayın görülmeyiş sıklığı (gerçekleşmeme olasılığı) t : Belirli bir anlamlılık düzeyinde, t tablosuna göre bulunan teorik değer d : Olayın görülüş sıklığına göre kabul edilen örnekleme hatasıdır.")
32
ÖRNEKLEMDEN ELDE EDİLEN VE TOPLUM BİLGİSİ
OLARAK KULLANILACAK OLAN “ BİLİMSEL SONUCUN ” AŞAĞIDAKİ KOŞULLARI SAĞLAMASI BEKLENİR. KESİNLİK -güvenilirlik ÖLÇÜM VARYASYONUNUN ÇOK GENİŞ OLMAMASI. BU RASSAL HATANIN DÜŞÜK OLMASI DEMEKTİR. GEÇERLİLİK ELDE EDİLEN SONUÇ DEĞERİN GERÇEK TOPLUM DEĞERİ YERİNE OTURACAK YAKINLIKTA OLMASI.

33
KESİNLİK VE GEÇERLİLİK
EN KÖTÜ SONUÇ KESİN DEĞİL GEÇERLİ DEĞİL (Rassal ve Sistematik Hata) KESİN GEÇERLİ DEĞİL (Sistematik Hata); KESİN DEĞİL GEÇERLİ (Rassal Hata) İDEAL SONUÇ KESİN GEÇERLİ Rassal Hata ; ölçüm kesin değil (Varyasyon geniş) Sistematik Hata ; Ölçüm geçerli değil
 KESİN. GEÇERLİ DEĞİL. (Sistematik Hata); KESİN DEĞİL. GEÇERLİ. (Rassal Hata) İDEAL SONUÇ. KESİN. GEÇERLİ. Rassal Hata ; ölçüm kesin değil (Varyasyon geniş) Sistematik Hata ; Ölçüm geçerli değil.")
34
2- değişkenlerin saptanması
Analize girecek değişkenleri kim belirleyecektir? Karıştırıcı- Yan değişkenler ile nasıl baş edilecektir? (Covariate adjustment) Eşik Değerlerin (Cut-off) Saptanması:
 Eşik Değerlerin (Cut-off) Saptanması:")
35
Değişken(variable) Deneklere ait özellikler Yaş Cinsiyet
Diastolik kan basıncı Eğitim Düzeyi Ağrı skoru Hastanın tanısı İlaç grubu

36
İstatistik analiz için ilk yapılacak şey, değişkenlerin nasıl ölçüldüğünün belirlenmesidir.

37
Değişkenlerin ölçüm biçimi
SAYISAL ÖLÇÜM ORDİNAL ÖLÇÜM NOMİNAL ÖLÇÜM

38
Sayısal Değişken Kesikli -interval variable: Sayımla belirtilen değerleri alabilen değişkenler kesiklidir. Ör. Kardeş, Gebelik sayısı Sürekli-continuous variable: Her türlü değeri alabilen değişkenler. Ör. Hg, Htc değeri, Yaş, Boy, Kilo

39
Sayısal Değişken Sayısal değişkenleri, sınıflayarak ordinal değişkenlere dönüştürebiliriz. Örneğin BMI sürekli değişkendir. BMI yeniden sınıflayarak 18,6’dan düşük değer alanları zayıf, ,0 arasında değer alanları normal, değer alanları şişman ve 30.1 den fazla değer alanları obez olarak 4 grupta sınıflandırabiliriz. Hastaların yaşlarını da "20’den küçük", "20-34", "35- 50", "50’den büyük" gibi sınıflandırarak, ordinal değişkene dönüştürebiliriz.

40
Önemli Not Veri toplarken sayısal değişkenleri, ordinal değişkenlere dönüştürmeyin, gerçek değerleri ile kaydedin. Hataya yol açmaz, ama daha az bilgi veren yöntemler kullanılmasını gerekli kılabilir. Veri toplandıktan sonra bilgisayarda “recode” komut ile sürekli değişkeni, orijinal veriyi koruyarak dönüştürebiliriz.

41
Ordinal- Sıralı Değişken
Değişkenin ölçüm düzeyleri arasında bir sıralama vardır, ama düzeyler arasındaki mesafeler belirli değildir. Örneğin tümörlü hastaların EVRE’si. Bu değişkene evre 1’den 4’e karşılık gelmek üzere, 1, 2, 3 ve 4 değerleri girilebilir. Bu değerler belirli bir sıra ifade etmektedir. Örneğin "evre 3, evre 2’den daha ileri evredir", "evre 1 en iyi, evre 4 en kötü evredir" vb. Ama değişkenin düzeyleri arasındaki mesafeler belirli değildir. Örneğin matematik işlem yapıldığında = = 1 doğrudur, ama "evre 2, evre1’den ne kadar ileriyse, evre 4 de evre 3’den o kadar ileridir" denemez.

42
Nominal-isimsel Değişken
İsimsel değişkenlerdir. Matematiksel bir değer almazlar. Ör. Cinsiyet, ek hastalık (DM, HT, MI…), Sonuç (stable, nüks, şifa), vs. Bilgisayara genellikle kodlayarak girilir. Nominal değişkenlerin düzeyleri arasında sıralama söz konusu değildir.
, Sonuç (stable, nüks, şifa), vs. Bilgisayara genellikle kodlayarak girilir. Nominal değişkenlerin düzeyleri arasında sıralama söz konusu değildir.")
43
VERİ TOPLAMA ARAÇLARI Anket Dosya Tarama Bilgi Formu Yasa dışı dinleme

44
ANKET Anket, sistematik veri toplama yöntemlerinden biridir.
En popüler veri toplama yöntemi olması basit ve kolay uygulanabilen bir yöntem olduğu kanısı uyandırmaktadır. Oysa bilimsel nitelikli anket hazırlanması uzmanlık gerektiren bir alandır. Geçerlilik Güvenilirlik ?

45
Anket nasıl uygulanacak?
Yüz yüze Posta (self report) Telefon. Hangi anket yöntemini seçeceğinize karar vermek araştırmanın bütçesine bağlı olduğu kadar konunun içeriği ile de çok ilgilidir. Örneğin cinsellik, inanç gibi konularda yüz yüze anket yönteminde deneklerin utanma nedeniyle güvenilir yanıtlar vermeyebileceği göz önünde bulundurulmalıdır.
 Telefon. Hangi anket yöntemini seçeceğinize karar vermek araştırmanın bütçesine bağlı olduğu kadar konunun içeriği ile de çok ilgilidir. Örneğin cinsellik, inanç gibi konularda yüz yüze anket yönteminde deneklerin utanma nedeniyle güvenilir yanıtlar vermeyebileceği göz önünde bulundurulmalıdır.")
46
Cevap formatına karar vermek
Kapalı uçlu Açık uçlu Yarı Açık uçlu

47
Cevap formatına karar vermek
Açık uçlu Kaç yaşındasınız? Yaşayan kaç çocuğunuz var? İhtiyaç duyduğunuz eğitimler nelerdir? …….

48
Cevap formatına karar vermek
Kapalı uçlu Eğitim durumunuz? Okur yazar değil Okur yazar İlk okul mezunu Ortaokul mezunu Lise mezunu Üniversite mezunu Aldığınız hizmetten ne kadar tatmin oldunuz? Hiç tatmin olmadım Tatmin olmadım Kararsızım Tatmin oldum Çok tatmin oldum

49
Cevap formatına karar vermek
Kapalı uçlu Bu eğitimden ne kadar yararlandınız? Hiç yararlanmadım Yararlanmadım Kararsızım Yararlandım Çok yararlandım 5’li Likert yöntemi

50
Cevap formatına karar vermek
Bu tür derecelendirme ölçeklerini hazırlarken uç noktaların zıt anlamda olduğundan emin olun. Bu yapılmazsa yanıtların taraflı olma riski ortaya çıkar. Örneğin aşağıdaki derecelendirme ölçekleri sizin hoşunuza gidecek cevaplar sağlayabilir ama gerçek ve ihtiyacınız olan bilgiyi vermez. Genelde tatminkar Tamamiyle tatminkar Son derece tatminkar Mükemmel

51
Soruları gözden geçirmek
Taslak anketi hazırladıktan sonra aşağıdaki özelliklere uygunluğunu gözden geçirin Her soru tek tek anketin amacına uygun olmalıdır. Soruları, mantıklı bir sıralama içinde hazırlayın. Genelden özele, kolaydan zora doğru sıralayın. İnsanların bilmedikleri ya da cevap veremeyecekleri maddeleri çıkarın Yanlış yorumlanabilecek belirsiz ifadelerden kaçının. Çakışan cevap seçenekleri vermeyin. Hiç Haftada bir saatten az Haftada 1-2 saat Haftada 2-3 saat

52
Soruları gözden geçirmek
Yönlendirici cevaplardan kaçının Düzenli bakım için çok fazla para ödediğinizi düşünüyor musunuz? Yan tutucu sorulardan sakının Bir Adanalı olarak, Adana müzesini gezdiniz mi? (gezmese bile gezdim diyecektir) Aynı soru içinde iki ayrı konu olmamasına dikkat edin. Doktorun muayenesi ve açıklamalarından tatmin oldunuz mu? Lüzumsuz ve tekrar sorularından kaçının İncitici ya da utandırıcı soruların genel sorulardan sonra olmasına özen gösterin (güven kazandıktan sonra). Geriye dönük sorularda hafıza faktörünü göz önünde bulundurun, uzun geçmişleri net hatırlamayabilirler. Yakın tarihli sorular sorun ya da belirli günler ya da zaman belirterek sorular
 Aynı soru içinde iki ayrı konu olmamasına dikkat edin. Doktorun muayenesi ve açıklamalarından tatmin oldunuz mu Lüzumsuz ve tekrar sorularından kaçının. İncitici ya da utandırıcı soruların genel sorulardan sonra olmasına özen gösterin (güven kazandıktan sonra). Geriye dönük sorularda hafıza faktörünü göz önünde bulundurun, uzun geçmişleri net hatırlamayabilirler. Yakın tarihli sorular sorun ya da belirli günler ya da zaman belirterek sorular.")
53
Anketi test etmek Hazırladığınız taslak anketi örneklem grubunu temsil edecek küçük bir grupta deneyin. Mümkünse grubu bir araya toplayıp anketi uygulayın. Anketle ilgili eleştirilerini yazılı bildirmelerini isteyin (grup önünde ifade edemeyebilirler) daha sonra tartışmaya açın. Böylece işlemeyen hatalı soruları belirleme olanağınız olacaktır. Süre tutun. Bir anketin ne kadar sürede doldurulduğunu belirleyin, çok uzun ise soruları bir kez daha gözden geçirin.
 daha sonra tartışmaya açın. Böylece işlemeyen hatalı soruları belirleme olanağınız olacaktır. Süre tutun. Bir anketin ne kadar sürede doldurulduğunu belirleyin, çok uzun ise soruları bir kez daha gözden geçirin.")
54
Veri girişi

55
Değişken ve değer etiketleri Nominal ve ordinal verilerin kodlanması
Veri girişi SPSS’te dosya işlemleri SPSS’te veritabanı hazırlama, değişkenlerin tanımlanması Değişken adı Değişken tipi Değişken ve değer etiketleri Nominal ve ordinal verilerin kodlanması Kayıp değerler

56
SPSS’i çalıştırdığınızda veri girişi için "New -data" penceresi açılır
SPSS’i çalıştırdığınızda veri girişi için "New -data" penceresi açılır. İki ayrı sayfa görüntülenir; Variable View sayfası Değişkenlerin tanımlandığı sayfa Data View sayfası Veri girişi sayfası

57
Value label ikonu aktif
Data View Value label ikonu aktif değil SPSS paket programında Breast Cancer Survival örnek datası

58
Value label ikonu aktif
Data View Value label ikonu aktif SPSS paket programında Breast Cancer Survival örnek datası

59
Değer etiketi Değişken adı Değiş.Tipi Etiketi Kayıp değer

60
Variable View sayfası

61
VERİLERİN GÖZDEN GEÇİRİLMESİ
Hata denetimi yapın Aşırı değerlere ne yapılacağına karar verin. Küçük kategorilere ne yapılacağına karar verin. Yeni kategoriler türetecek misiniz?

62
İstatistik analize hazırlık
Verilerde hata kontrolü aşırı değer (outlier) kontrolü min-max kontrolü Veriler neden eksik? Eksik verilere ne yapmalı?
 kontrolü. min-max kontrolü. Veriler neden eksik Eksik verilere ne yapmalı")
63
Box-plot grafiği ile aşırı değer kontrolü
Outlier değerler 4 ve 37. sıradaki hastalar Extreme değer 57. sıradaki hasta

64
İSTATİSTİK ANALİZE HAZIRLIK
Veri tabanı oluşturun Verileri kodlayın ve bilgisayara ortamına aktarın. Verilerde hata kontrolünü yapın. Eksik verilere ne yapılacağına karar verin. Aşırı değerlere ne yapacağınıza karar verin Yeniden kodlamaları yapın Değişkenlerin dağılımını belirleyin (çok önemli)
")
65
Verilerin dağılım özelliği niçin önemlidir?
İstatistikte dağılımın normal olup olmadığının belirlenmesi çok önemlidir. Çünkü farklı dağılım gösteren verilere uygulanacak tanımlayıcı ve analitik istatistik yöntemleri de farklıdır. Parametrik testlerin tümünün uygulanabilmesi için verilerin dağılımının normal olması gelir. Dağılımın normal olup olmadığı grafik ve istatistik analiz yöntemleri ile araştırılır.

66
Normal Dağılım Doğadaki ve toplumdaki çok şeyin dağılımı çan eğrisine benzer

67
Değişkenlik

70
Normal Dağılım Normal dağılım simetrik olduğu için normal dağılım gösteren değişkenlerin ortalama, ortanca ve modları eşittir. Eğer bir dağılım simetrik değilse, dağılım eğrisinde çan eğrisinin tepe noktası ortada değil, sağa ve sola kaymış olacaktır.

71
Skewness Denekler ortalamadan daha büyük değerlerde toplanıyorlarsa, negatif basık ya da soldan basık (negatively skewed, skewed to the left), küçük değerlerde toplanıyorlarsa, pozitif basık ya da sağdan basık (positively skewed, skewed to the right) dağılımdan sözedilir . Mean, median ve mode farklıdır. Unimodal’da mean kuyruğa doğru çekilir. Median mean ile mode arasına düşer.
, küçük değerlerde toplanıyorlarsa, pozitif basık ya da sağdan basık (positively skewed, skewed to the right) dağılımdan sözedilir . Mean, median ve mode farklıdır. Unimodal’da mean kuyruğa doğru çekilir. Median mean ile mode arasına düşer.")
72
Kurtosis Dağılımın şeklinin ölçüsüdür. Pozitif değerler dağılımın dik, negatif değerler ise yassı olduğunu gösterir.

73
BAŞARI 4 yaşında başarı ....donuna işememektir. 12 yaşında başarı arkadaş bulabilmektir. 16 yaşında başarı araba surebilmektir. 20 yaşında başarı seks yapabilmektir. 35 yaşında başarı para kazanabilmektir. 50 yaşında başarı çok para kazanabilmektir. 60 yaşında başarı seks yapabilmektir. 70 yaşında başarı araba surebilmektir. 75 yaşında başarı arkadaş bulabilmektir. 80 yaşında başarı ....donuna işememektir. Buna ÇAN EĞRİSİ denir!.. Prof. Albert Follanberg

74
Normal dağılım nasıl anlaşılır?
Grafikler ile Merkezi ölçütler ve Dağılım ölçütleri ile Skewness ve kurtosis değerleri ile Hipotez testleri ile

75
Değerlerin histogramını çizerek
1. Grafikler ile Değerlerin histogramını çizerek Ya da "normal olasılık grafiği" (normal probability plot) adı verilen grafiğini çizerek araştırılabilir.
 adı verilen grafiğini çizerek araştırılabilir.")
76
2. Merkezi ve yayılım Ölçütleri ile
Ortalama, median ve mod birbirine yakın olmalı Standart Sapma Ortalamanın yaklaşık ¼ ü Skewness ve Kurtosis sıfıra yakın olmalı 3. Basıklık ve çarpıklık değerleri ile Skewness ve Kurtosis sıfıra yakın olmalı

77
4. Testlerle Shapiro-Wilks’ ve Kolmogorov Smirnov testleri bu amaç için sıklıkla kullanılan testlerdir. p değeri < 0.05 ise, dağılım normal değil. Özellikle denek sayısı fazlaysa, genellikle tüm normal dağılım testleri ile "p < 0.05" bulunabilir. Bu nedenle bu durumlarda grafik değerlendirmeler yapılmalı

78
Spss’te normal dağılım testleri nasıl yapılır?
SPSS’te dağılımın normal olup olmadığı çeşitli yöntemlerle test edilebilir: ”Analyse >> Descriptive statistics >> Frequencies ..." diyalog kutusundan ulaşılan "Charts" diyalog kutusu yoluyla histogram ve with normal curve kutuları işaretlenerek dağılımda normalden sapmalar olup olmadığı hakkında fikir edinilebilir.

79
Spss’te normal dağılım testleri nasıl yapılır?
" Analyse >> Descrptive statsitics>> Explore" seçimi ile açılan "Explore" diyalog kutusundaki "Plots" seçeneğinde "Normality plots with test" ile normal olasılık ve "detrended" normal olasılık grafikleri ve normal dağılım testleri yapılır. Dağılımı test edilecek değişken "Dependent List"e alınmalıdır. Eğer tüm deneklerdeki ölçümlerin dağılımı test edilecekse "Factor List" boş bırakılmalıdır. Altgruplardaki ölçümlerin dağılımı ayrı ayrı test edilecekse, altgrupları belirleyen değişken "Factor List"e seçilmelidir.

80
Normale uygunluk testleri

81
Dağılım şekli ölçütleri verilerin dağılım özelliği niçin önemlidir?
İstatistikte dağılımın normal olup olmadığının belirlenmesi çok önemlidir. Farklı dağılım gösteren verilere uygulanacak tanımlayıcı ve analitik istatistik yöntemleri de farklıdır. Veriyi tablolarda hangi ölçütler ile özetleyeceğiniz Hangi grafiği seçeceğiniz Hangi hipotez testini seçeceğiniz Dağılıma bağlıdır

82
Normaller tehlikelidir

83
Verilerin analizi

84
Tanımlayıcı İstatistikler
Değişkenin örnek ya da toplum özelliklerini yansıtan değerlere tanımlayıcı istatistikler adı verilir. İki ana gruba ayrılır.

85
Tanımlayıcı İstatistikler
Merkezi Eğilim Ölçütleri Aritmetik ortalama Medyan Mod Yayılım Ölçütleri Değer aralığı (range) Standart sapma ve varyans, standart hata Değişim (varyasyon) katsayısı Persentil Çeyreklerarası aralık Güvenirlik aralıkları
 Standart sapma ve varyans, standart hata. Değişim (varyasyon) katsayısı. Persentil. Çeyreklerarası aralık. Güvenirlik aralıkları.")
86
Not: Dağılım normal ise ortalama yı, normal değil ise medyan ı verin
Aritmetik Ortalama Değerlerin toplamının denek sayısına bölünmesiyle elde edilen aritmetik ortalama en sık kullanılan merkezi eğilim ölçütüdür. Sayısal değişkenler için merkezi eğilim ölçütü olarak ortalama kullanılır. Medyan-Ortanca küçükten büyüğe (ya da büyükten küçüğe) doğru sıralandığında tam ortadaki deneğin değeridir. ordinal veriler için en iyi merkezi dağılım ölçütüdür Ortanca aşırı değerlerden etkilenmez. Bu nedenle aşırı uç değerler varsa, sayısal veriler için de ortanca tercih edilmelidir. Mod En sık tekrarlayan değer Not: Dağılım normal ise ortalama yı, normal değil ise medyan ı verin
 doğru sıralandığında tam ortadaki deneğin değeridir. ordinal veriler için en iyi merkezi dağılım ölçütüdür. Ortanca aşırı değerlerden etkilenmez. Bu nedenle aşırı uç değerler varsa, sayısal veriler için de ortanca tercih edilmelidir. Mod. En sık tekrarlayan değer. Not: Dağılım normal ise ortalama yı, normal değil ise medyan ı verin.")
87
Yayılım Ölçütleri STANDART SAPMA VE VARYANS: SD, sd ya da s ile gösterilen standart sapma, değişken değerlerinin ortalamanın etrafındaki yayılmasını temsil eden bir yayılma ölçütüdür. Değerler arasında farklar arttıkça standart sapma ve varyans büyür. Standart sapmanın karesine varyans adı verilir. Standart sapma ve varyans, birçok istatistik analiz yönteminin temelini oluşturur.

88
Yayılım Ölçütleri DEĞER ARALIĞI (Range): Değişken değerlerinin dağılımını belirten yararlı bir ölçüt, en büyük ve en küçük değer arasındaki fark olan değer aralığıdır (range). Değer aralığı da, ortalama gibi uç değerlerden çok etkilenir. Üstelik en uçtaki iki değer arasında kalan değerler hakkında bilgi vermez
: Değişken değerlerinin dağılımını belirten yararlı bir ölçüt, en büyük ve en küçük değer arasındaki fark olan değer aralığıdır (range). Değer aralığı da, ortalama gibi uç değerlerden çok etkilenir. Üstelik en uçtaki iki değer arasında kalan değerler hakkında bilgi vermez.")
89
Yayılım Ölçütleri PERCENTİLLER: Çeyreklikler
Laboratuvar değerlerinin alt ve üst normal sınırlarının belirlenmesinde Genellikle kabul edilen alt normal sınır 2.5 persentil ve üst normal sınır 97.5 persentildir. ÇEYREKLERARASI ARALIK: 25. ve 75. persentil değerleri arasındaki farka çeyreklerarası aralık (interquartile range) adı verilir. Yani değerlerin ortada yer alan %50’si, çeyrekler arası aralıktır.
 adı verilir. Yani değerlerin ortada yer alan %50’si, çeyrekler arası aralıktır.")
90
Güvenirlik aralıkları
Güvenirlik Aralığı: Evren, parametresinin içinde bulunabileceği aralığın, bu aralıkta bulunma olasılığı ile birlikte verilmesidir. (%95', %99'luk güvenirlik aralığı, gibi) Ortalama için güvenirlik aralıkları: Evren ortalamasının içine düşmesinin beklendiği bir (a,b) aralığıdır. Oranlar için güvenirlik aralıkları: Evren oranının içine düşmesinin beklendiği bir (p1, p2) aralığıdır.
 Ortalama için güvenirlik aralıkları: Evren ortalamasının içine düşmesinin beklendiği bir (a,b) aralığıdır. Oranlar için güvenirlik aralıkları: Evren oranının içine düşmesinin beklendiği bir (p1, p2) aralığıdır.")
91
Ne zaman hangisini kullanalım?
Dağılım normal ise mean Dağılım normal değil ise median Merkezi eğilim ölçütü olarak ortalama kullanıldığı zaman, yayılma ölçütü olarak da standart sapma kullanılır. Ortalama ±SS Median kullanılacaksa minimum maksimum değerleri verilir. Medyan (min-max)
")
92
Spss’te tanımlayıcı istatistik nasıl yapılır?
"frequencies" menüsü "descriptives" menüsü

93
HİPOTEZ TESTLERİ (ÖNEMLİLİK TESTLERİ)
")
94
İstatistik analiz KARARI
Hipotezimiz ne istiyor? Soru neydi? Araştırmamız tanımlayıcı mı? İlişki mi arıyor? Fark mı arıyor? Nedensellik bağı mı kuruyor? Faktör gruplandırması mı yapmak istiyor?

95
İstatistik Yöntemler Tanımlayıcı istatistik yöntemleri
Sonuç çıkarıcı istatistik yöntemleri Tek İki Çok değişkenli değişkenli değişkenli Ortalamaya dayanan Faktör analizi Dağılım Şekli Çoklu regresyon T test anova Cluster analizi tek grup İki grup Merkezi yönelim Discriminant analiz Ortak ilişki Bağımlı grup Yayılış Regresyon Bağımsız grup

96
Hipotez testleri uyum iyiliğinde iki grubu / sonucu karşılaştırmada
Hipotez testleri elde edilen değerlerin, sonuçların, istatistiksel olarak önemli olup olmadığını test ederler. Hipotez testleri; uyum iyiliğinde iki grubu / sonucu karşılaştırmada çok grupları / sonuçları karşılaştırmada kullanılabilirler.

97
Hipotez testi nedir? Bir fark var mı? / Bir fark oluştu mu?
Hemen bütün çalışmaların veri toplanmasının bitiminde araştırmacı bir soru sorar. Bir fark var mı? / Bir fark oluştu mu? Bu sorudan kastedilen, örnek çalışmada meydana gelen farkı ham hali ile sorgulamak değildir. Zaten sözgelimi, aynı 10 kişinin boylarını 2 saat ara ile ölçseniz yine de fark oluşur. Kastedilen şey bu farkın önemli olup olmadığıdır. Yani farkın ‘istatistiksel önemi’dir.

98
tek yönlü çift yönlü Hipotezler
Hipotez testleri (önemlilik testleri ) bir hipotezi test eder. H0 : Fark yok H1 : Fark var tek yönlü çift yönlü Hipotezin tek ya da çift yönlü oluşuna baştan karar vermek önemlidir. Bu karar yorumunuzu etkileyecektir (p-değerini değiştireceği için)
 bir hipotezi test eder. H0 : Fark yok. H1 : Fark var. tek yönlü. çift yönlü. Hipotezin tek ya da çift yönlü oluşuna baştan karar vermek önemlidir. Bu karar yorumunuzu etkileyecektir (p-değerini değiştireceği için)")
99
bir fark olduğunu söylerken onun gerçekte olmama olasılığıdır
Nedir bu p değeri ???? p ; bir fark olduğunu söylerken onun gerçekte olmama olasılığıdır

100
Asıl Soru Yani; aslında soru şudur:
Örnekte meydana gelen bu fark; eğer çok fazla birimde (hatta mümkünse evrende) çalışsak yine ortaya çıkar mıydı? ya da, bu fark aslında tesadüfen mi ortaya çıkmıştır? İstatistik, bu tesadüflüğün ölçüsü konusunda bize yardım eder.
 çalışsak yine ortaya çıkar mıydı ya da, bu fark aslında tesadüfen mi ortaya çıkmıştır İstatistik, bu tesadüflüğün ölçüsü konusunda bize yardım eder.")
101
Örnek – evren - önemlilik
Örnek-evren- önemlilik konusunu açmak için bir örnek ile devam edelim...

102
Hipotez örnekleri H0 :Diyetle alınan hayvansal yağ miktarı meme kanseri mortalitesini etkilemez. H1 : Meme kanseri mortalitesi yağ miktarı artınca artar (tek yönlü). H0 : KYB hastaları ile cerrahi hastaları arasında depresyon yönünden fark yoktur. H1 : KYB hastaları ile cerrahi hastaları arasında depresyon oranı farklı olur (çift yönlü).
. H0 : KYB hastaları ile cerrahi hastaları arasında depresyon yönünden fark yoktur. H1 : KYB hastaları ile cerrahi hastaları arasında depresyon oranı farklı olur (çift yönlü).")
103
Hangisi ile?????? Ki kare?? T testi?? Anova?? Mann Whitney U??
Hadi test edelim Hangisi ile?????? Ki kare?? T testi?? Anova?? Mann Whitney U??

104
Test seçimini etkileyen faktörler:
Hipotez test seçimi Test seçimini etkileyen faktörler: Verinin Ölçüm Biçimi Grupların Bağımlı ya da Bağımsız oluşu Grup Sayısı Gruplardaki Eleman sayısı-dağılım

105
Sürekli İsimsel Mc Nemar Mc Nemar Kikare Kikare Grup Bağımlı
Parametrik Nonparametrik Grup Bağımlı Wilcoxon Friedman test Pair T test Repeated M.A Grup sayısı 2 Grup sayısı 3+ Grup Bağımsız Student t test One way ANOVA Mann Whitney U Krusall Wallis Grup sayısı 2 Grup sayısı 3+ İsimsel Mc Nemar Mc Nemar Grup Bağımlı Kikare Kikare Grup Bağımsız

106
Verinin ölçüm biçimi Bazı veriler ölçülür: boy uzunluğu, ağırlık, hemoglobin değeri, kolesterol miktarı, hastanede yatılan gün sayısı, günlük diyetle alınan yağ miktarı. Bazıları ise isimlendirilir: cinsiyet, meslek, hastalık cinsi,, yapılan ameliyatın türü, alınan ilaç.

107
Verinin ölçüm biçimi İsimsel Sürekli

108
2. Bağımlı ve bağımsız gruplar
İki ya da daha çok grup karşılaştırılması yapılıyorsa, grupların bağımlı ya da bağımsız olduğunu bilmek çok önemlidir. Bağımlı grup: 1 birey (birim) den birden fazla ölçüm alınması ile oluştuğu durumdur. Bağımsız grup: Ölçümlerin birbirinden farklı birey ya da gruplarda yapıldığı durumdur.
 den birden fazla ölçüm alınması ile oluştuğu durumdur. Bağımsız grup: Ölçümlerin birbirinden farklı birey ya da gruplarda yapıldığı durumdur.")
109
Bağımsız grup Bağımlı grup A ilacının 5.dakikadaki kalp atım hızı ile
B ilacının dakikadaki kalp atım hızı A ilacının 5.dakikadaki kalp atım hızı ile A ilacının 10.dakikadaki kalp atım hızı

110
3. Grup sayısı Tek grup 2 grup 3 ve daha fazla grup

111
Grup sayısı ve ölçüm sayısı
Tek grup 2 grup Tek grupta 2 zamanlı ölçüm 2 ve daha fazla grup Tek grup 2 den fazla ölçüm 2 den fazla grup 2 den fazla ölçüm

112
Grup sayısı ve ölçüm sayısı
Tek grup-Panik hastalarda ank. skoru 2 grup- Panik ve OKB ank. skoru Tek grupta 2 zamanlı ölçüm-Panik hastalarda A ilacı öncesi ve 3 ay sonrası ank. skoru 3 ve daha fazla grup- Panik, OKB ve sağlıklı kontrollerde ank skoru Tek grup 2 den fazla ölçüm-Panik hastalarda başlangıç, 1 ay 3 ay 6 ay sonrasında ank skoru 3 den fazla grup 3 den fazla ölçüm- Panik hastalara A ilacı; 1, 3, 6 ay ank skoru; panik hastalara kognitif terapi; 1,3,6 ay ank. skoru

113
4. Gruplardaki kişi sayısı (n)
Önemlilik testlerinde ‘30’ sayısı; istatistiksel teori içinde anlam taşıdığından önemlidir. 30 ve daha büyük örnekli gruplara test gücü daha fazla olan parametrik testler uygulanır.-merkezi limit teoremine dayanır Asıl dayanak dağılımın normal olmasıdır. n sayısı 500 de olsa değişken normal dağılmıyorsa parametrik test seçilemez

114
Test seçimini etkileyen faktörler:
Test seçimi özeti Test seçimini etkileyen faktörler: Verinin Ölçüm Biçimi Grupların Bağımlı ya da Bağımsız oluşu Grup Sayısı Gruplardaki Eleman sayısı-dağılım

115
Test Seçimi

116
Araştırma-1 40’ar kişilik iki grup hastaya iki farklı tedavi ile depresyon tedavisi yapılmış ve HAM-A skorları karşılaştırılmıştır. sürekli bağımsız iki grup 30 dan fazla-normal student-t testi

117
Test Seçimi

118
Araştırma -2 50 hastanın 25’inde A ajanı, 25’inde ise B ajanı kullanılmıştır ve grupların CGI değerleri karşılaştırılmıştır. sürekli bağımsız iki grup 30 dan az-normal değil Mann Whitney-U

119
Test Seçimi

120
Araştırma-3 Plasebo alan 40 hasta, klasik ajanla tedavi edilen 39 hasta ve yeni ilaç ile tedavi edilen 41 hastanın anksiyete skoru karşılaştırılacaktır. sürekli bağımsız üç grup 30 dan fazla-normal varyans analizi-ANOVA

121
Test Seçimi

122
Araştırma-4 A ilacı alan 61 ve B ilacı alan 62 parkinson hastasında tedavi sonrası diskinezi oranları karşılaştırılacaktır. isimsel bağımsız iki grup Ki kare

123
Test Seçimi

124
Araştırma -5 Anksiyeteli 50 çocukta yeni bir eğitim modeli uygulanacaktır. Eğitimin yararı STA-I ve STA-II skorları ile değerlendirilecektir. Ölçümle bağımlı iki grup 30 dan fazla Pair t test

125
Araştırma -6 50 nefrotik sendromlu hastada diyalize başlamadan önceki crp düzeleri ile 1 ay ve 3 ay sonraki crp düzeyleri karşılaştırılacaktır. Ölçümle bağımlı iki grup 30 dan fazla-dağılım? Friedman test

126
Test Seçimi Friedman

127
Test Değişkenler Hangi test İsimsel-İsimsel (oran farkı) Ki kare
İsimsel- Sürekli (ortalama farkı) Sürekli-Sürekli (ilişki) Ki kare T testleri Korelasyon testi- Lineer regresyon
 Sürekli-Sürekli (ilişki) Ki kare. T testleri. Korelasyon testi- Lineer regresyon.")
128
Sürekli değişken İlişki
Değişken tipi Sürekli Dağılım normal Parametrik testler Dağılım Normal değil Nonparametrik testler Grup Bağımlı Wilcoxon Friedman test Pair T test Repetead M.A Grup sayısı 2 Grup sayısı 2+ Grup Bağımsız Student t test One way ANOVA Mann Whitney U Krusall Wallis Grup sayısı 2 Grup sayısı 2+ Sürekli değişken İlişki Pearsons Spearman

129
SPSS’de Parametrik Testler

130
SPSS’de Non-parametrik Testler

131
İleri Analiz teknikleri
Korelasyon Regresyon Ancova-Manova Survival Analiz Discriminat Cluster Faktör Analizi Reliability …..

132
ÇALIŞMANIN KOŞULLARINA GÖRE
UYGUN BİYOİSTATİSTİKSEL YARGI YÖNTEMİ BELİRGİN ve TEK’TİR…..

134
Verilerin sunumu

135
Temel kavramlar

136
GÜÇ (POWER) Gerçek Durum testin anlamlılık düzeyi
H0 Doğru H0 Yanlış gerçek pozitif 1 - b tip I hata a H0 Red testin, anlamlı farkı GÜÇ bulma olasılığı Karar gerçek negatif 1 - a tip II hata b H0 Kabul

137
POWER: Bir çalışmanın, belirli bir büyüklükteki gerçek etkiyi saptayabilme gücü. Güç = 1- Tip II hata Güç Analizi: Belirli bir büyüklükteki etkiyi (farkı) saptayacak örnek büyüklüğünün belirlenmesi
 saptayacak örnek büyüklüğünün belirlenmesi.")
138
Tip I Hata Eğer gerçekte tespit edilen fark tamamen şansa (örnekleme hatası) bağlı ise ve çalışmamızda H0 hipotezini reddedersek doğruyu bulmuş oluruz, ancak fark gerçekten varsa ve çalışmamızda H0 hipotezini rededersek Tip I (α) hata yapmış oluruz. Eğer gerçekte tespit edilen fark, tamamen şansa (örnekleme hatası) bağlı ise, H0 hipotezini kabul etmemiz bizi yine doğruya götürür.
 bağlı ise ve çalışmamızda H0 hipotezini reddedersek doğruyu bulmuş oluruz, ancak fark gerçekten varsa ve çalışmamızda H0 hipotezini rededersek Tip I (α) hata yapmış oluruz. Eğer gerçekte tespit edilen fark, tamamen şansa (örnekleme hatası) bağlı ise, H0 hipotezini kabul etmemiz bizi yine doğruya götürür.")
139
Tip II hata Ancak eğer fark gerçekten varsa ve biz H0 hipotezini kabul edersek yani fark yoktur sonucuna varırsak bu kez de Tip II (β) hata yapmış oluruz
 hata yapmış oluruz.")
140
Hipotez sınama sonrası olası sonuçlar
Tip I hata (α) Gerçekte tedaviler birbirinden farksızken anlamlı p değeri (p < α) bulunmasıdır. Etkin olmayan tedaviye onay Tip II hata (β) H0 hipotezinin gerçekte doğru olmadığı bir durumda kabul edilmesidir. Tip II hata çalışmanın gücünü belirler. Etkin olan bir tedavinin kullanım dışı kalması
 Gerçekte tedaviler birbirinden farksızken anlamlı p değeri (p < α) bulunmasıdır. Etkin olmayan tedaviye onay. Tip II hata (β) H0 hipotezinin gerçekte doğru olmadığı bir durumda kabul edilmesidir. Tip II hata çalışmanın gücünü belirler. Etkin olan bir tedavinin kullanım dışı kalması.")
141
P- değeri (İstatistiksel Önemlilik)
Anlamlılık seviyesi, sonucumuzun ne kadar hata oranı ile kabul edilebilir olduğu konusunda karar vermemizi sağlayan bir kriterdir. Yani araştırmanın planlama aşamasında Tip I hata yapma olasılığımızı belirleriz, bu değer genellikle 0.05 kabul edilir.

142
P- değeri (İstatistiksel Önemlilik)
Çalışma grupları arasındaki farkın tamamen şansa bağlı olarak ortaya çıkma olasılığı P değerinin kendisinin verilmesi P= p=0.06 Veya < 0.05, 0.01, 0.001

143
Anlamlı Değil !!! Kafası Kesilerek Öldürülen 10 Fareden Birinin Yaşamaya Devam Ettiğini Gören İstatistikçinin Yorumu Ne Olur ?? - Anlamlı Değil !!!

144
Belli bir güven derecesinde gerçek değerin bulunduğu aralıktır.
GÜVEN ARALIKLARI Belli bir güven derecesinde gerçek değerin bulunduğu aralıktır. Alt ve üst sınırı vardır RR= 1.9 % 95 GA ( ) GA % 90, %99 ve %95 olabilir. GA 1’i içeriyorsa p> 0.05 GA 1’i içermiyorsa p< 0.05
 GA % 90, %99 ve %95 olabilir. GA 1’i içeriyorsa p> GA 1’i içermiyorsa p<")
145
Güven aralığının üstünlükleri:
Çalışmalardan elde edilen kestirimler (estimates) değişkendir, tekrarlandığında aynı sonuçlar elde edilmez. İstatistik testin verdiği bilgiyi ve örnek büyüklüğü ile ilgili bilgiyi de verir. Geniş GA riskin değişkenliğini ve çalışma grubunun küçük olduğunu gösterir Dar GA riskin az değişken olduğunu ve çalışma grubunun büyük olduğunu gösterir. Literatürle uyumlu olmayan çalışmalarda güven aralığı daha da önemli.
 değişkendir, tekrarlandığında aynı sonuçlar elde edilmez. İstatistik testin verdiği bilgiyi ve örnek büyüklüğü ile ilgili bilgiyi de verir. Geniş GA riskin değişkenliğini ve çalışma grubunun küçük olduğunu gösterir. Dar GA riskin az değişken olduğunu ve çalışma grubunun büyük olduğunu gösterir. Literatürle uyumlu olmayan çalışmalarda güven aralığı daha da önemli.")
146
2 Kere 2 Kaç Eder Sorusuna Yanıtlar
İlkokul Çocuğu : Dört. Matematik Profesörü : (Uzun Uzun Düşündükten Sonra) Dört.. İstatistik Profesörü : % 95 Olasılıkla 3.75 ile Arasında Çıkar... Pazar Araştırma Uzmanı : Size Ne Kadar Lazımdı ??
 Dört.. İstatistik Profesörü : % 95 Olasılıkla 3.75 ile 4.25 Arasında Çıkar... Pazar Araştırma Uzmanı : Size Ne Kadar Lazımdı")
147
Risk Ölçütleri Rölatif risk (RR) Risk oranı (RR) Hızların oranı (RR)
Odds ratio (OR)
")
148
Hasta Sağlam Etken + Etken - Rölatif Risk a b c d a/a+b = Insidans (+)
c/c+d = Insidans (-) I + I - Rölatif Risk
 I + I - Rölatif Risk.")
149
Olgu Kontrol a/c = odds Etken + b/d = odds Etken - Odds Ratio a b c d
a/c ad = b/d bc Odds ratio

150
Önemlilik Etkenle sonuç ilişkisi güçlü mü? (OR veya RR)
Kohort ve RCT’de insidansların oranı olan RR hesaplanır Geriye dönük incelendiği için insidanslar belirlenemediği için, RR değil OR hesaplanır. RR veya OR=1 ise risk yok RR veya OR>1 ise risk var RR veya OR<1 ise koruyucu

151
Risk ölçütlerinin kesinlik düzeyi (GA)
Sonuçların rasgele hatalardan etkilenmemesi için çalışmanın olgu sayısı fazla olmalı Genellikle, sonuçlarda hesaplanan güven aralıkları (GA) dar ise çalışmadaki olgu sayının büyük olduğunu, GA geniş ise çalışmadaki olgu sayısının küçük olduğunu gösterir. GA 1’i içeriyorsa istatistiksel önem yoktur. %90, %95, %99
 dar ise çalışmadaki olgu sayının büyük olduğunu, GA geniş ise çalışmadaki olgu sayısının küçük olduğunu gösterir. GA 1’i içeriyorsa istatistiksel önem yoktur. %90, %95, %99.")
152
NNH NNH, bir fazla kişide daha zararlı etkinin görülebilmesi için kaç kişinin etkenle karşılaşması gerektiğini gösteren sayı Örneğin sigara içenlerde akciğer kanseri gelişme riskini araştıran bir çalışmada NNH=5 ise beş kişinin sigara içmesiyle toplumda bir fazla kişide daha akciğer kanseri geliştiğini gösteriyor Kohort ve RCT’de NNH = 1/[a/a+b] - [c/c+d]

153
Çalışmanın sonuçları önemli mi ?
Sonuç etken ilişkisi ne kadar güçlü ? Tedavinin etkisi ne büyüklükte ? Control event rate Experimental event rate RRR, ARR, NNT... Tedavinin etkisi ne kadar kesin ? % 95 CI ...

154
TEDAVİ ETKİLERİ Deney grubunda olay hızı (EER)
Olay, araştırmada beklenen sonuç Yan etki, komplikasyon, nüks vb. Kontrol grubunda olay hızı (CER) Mutlak risk azalması (ARR) = EER-CER Göreli risk azalması (RRR)
 Mutlak risk azalması (ARR) = EER-CER. Göreli risk azalması (RRR)")
155
NNT Tedavi için gerekli sayı Number needed to treat (NNT) İstenen olumlu sonuca ulaşılacak her bir hasta için, tedavi edilmesi gereken hasta sayısı 1/ ARR = 1/ EER-CER

156
Örnek Teratogenicity of high Vitamin A intake Rothman KJ ve ark, Teratogenicity of high Vitamin A intake, NEJM 1995; 333(21):
:")
157
Gebelikte yüksek doz A-vitamini verilmesi ile nöral tüp defekti oluşumu arasında ilişki
Kohort çalışma 100 kadın doğum uzmanına amniyosentez +/- alfa-fetoprotein izlemi için başvuran gebe kadın çalışmaya katılmayı kabul etmiş 22748 (%96.8) takip edilmiş
 takip edilmiş.")
158
Tüm gebelere; diyet, tedavi, ilk trimestrda geçirdikleri hastalıklar, kullandıkları A- vitamini dozu ile ilgili anket yapılmış. Tüm hastalar doğuma kadar takip edilmiş, doğumda ortaya çıkan anomaliler CDC kriterlerine göre değerlendirilmiş. İlk trimestr’da A vitaminini > U/gün ile <5.000 U/gün kullananlar, bebeklerinde gelişen nöral tüp defektleri açısından karşılaştırılmış.

159
Bebekte nöral tüp defekti oluşumu
+ - Toplam >10.000 7 310 317 <5.000 51 11032 11083 58 11342 11400 Annenin günlük aldığı Vitamin A dozu RR = (7/317) / (51/11083) = / = 4.8
 / (51/11083) = / = 4.8.")
160
<5.000 IU VitA/gün alabilir
Çalışmanın sonuçları? Etkenle sonuç arasında ilişki ne kadar güçlü? (OR veya RR ne kadar büyük?) RR büyük (RR=4.8) Risk ölçütlerinin kesinlik düzeyi nasıl?(GA nasıl ?) %95 GA = Riskin büyüklüğü ne? > riski=0.0220 <5.000 riski=0.0046 NNH= =57 Etkenle karşılaşmayı engellemeli iyim? (Maruziyeti kesmeli miyim?) Evet (> için) <5.000 IU VitA/gün alabilir
 RR büyük. (RR=4.8) Risk ölçütlerinin kesinlik düzeyi nasıl (GA nasıl ) %95 GA = Riskin büyüklüğü ne > riski= <5.000 riski= NNH= 1 . = Etkenle karşılaşmayı engellemeli iyim (Maruziyeti kesmeli miyim ) Evet (> için) <5.000 IU VitA/gün alabilir.")
161
Tedavi için gereken sayı
Göreli risk azalması RRR Mutlak risk azalması ARR Tedavi için gereken sayı NNT CER EER CER-EER 1/ARR %17.4 %14.8 0.149 %2.6 38

162
TIPTA KARAR VERME Tıpta tanı yöntemleri ile ilgili araştırmaların büyük bir bölümü, tanı yöntemlerinin doğruluğunun kestirilmesi ve karşılaştırılmasına ayrılmıştır. Tanı doğruluğunu gösterecek değişik ölçüler geliştirilmiş, bu amaç için klinik çalışma düzenleri tanımlanmıştır. Son yıllarda giderek artan öneminin nedenlerinden biri de hasta bakım maliyetleri üzerine olan etkisidir.

163
Tanı testinin kullanılabilir olması için
I- Hastanın durumu hakkında güvenilir bilgi sağlaması II- Hastanın tedavisi ile ilgili hekimin planları üzerinde etkili olabilmesi III- Hastalar üzerinde test tekrarlandığında hastalık mekanizmalarını yada hastalığın doğal seyrini anlatabilmesi

164
Tanı testi performansları nasıl değerlendirilir
A - Özgün oranlar B - Kestirim gücü C- ROC eğrisi Kappa katsayısı, Mc-Nemar testi;

165
Tanı ve Tarama Testleri
Altın Test a/a+c = Duyarlılık Doğru pozitif oran Test + - a b c d d/b+d = Seçicilik Doğru negatif oran a/a+b = + PD 1-Seçicilik d/c+d = - PD 1-Duyarlılık

166
Duyarlılık Testin toplumdaki hastaları saptayabilme gücü
Payda (toplumdaki) gerçek hastalar
 gerçek hastalar.")
167
Seçicilik Testin toplumdaki sağlamları saptayabilme gücü
Payda (toplumdaki) gerçek sağlamlar
 gerçek sağlamlar.")
168
Duyarlılık (Sensitivity): Gerçekte hasta olanlar arasında testin pozitif sonuç verme oranı
Seçicilik (Specificity): Gerçekte hastalığa sahip olmayanlar arasında testin negatif sonuç verme oranı Yanlış pozitif oran: Gerçekte hastalığa sahip olmayanlar arasında testin yanlışlıkla pozitif sonuç verme oranı=1-Seçicilik Yanlış negatif oran: Gerçekte hasta olanlar arasında testin yanlışlıkla negatif sonuç verme oranı=1-Duyarlılık
: Gerçekte hastalığa sahip olmayanlar arasında testin negatif sonuç verme oranı. Yanlış pozitif oran: Gerçekte hastalığa sahip olmayanlar arasında testin yanlışlıkla pozitif sonuç verme oranı=1-Seçicilik. Yanlış negatif oran: Gerçekte hasta olanlar arasında testin yanlışlıkla negatif sonuç verme oranı=1-Duyarlılık.")
169
hastalık prevelansından etkilenmezler.
DP ve DN oranlar hastalık prevelansından etkilenmezler. YN Tedavinin gecikmesi YP Riskli, gereksiz, ileri tetkikler, Yanlış tedavi, Yanlış tanımlama DP-DN Hastalık şiddeti, anatomik özellikler, hasta özellikleri

170
DUYARLILIK VE SEÇİCİLİĞİN BİRLEŞTİRİLMESİ İLE ELDE EDİLEN ÖLÇÜLER
Duyarlılık ve Seçicilik gibi iki ölçü kullanmak yerine bunları birleştiren tek ölçülere gereksinim duyulur. DOĞRU TEST SONUCU OLASILIĞI= GERÇEK DURUM H+ H- T E S T+ a b T- c d TOPLAM n1 n2 Toplam doğruluk çok yüksek çıkabilir ancak seyrek görülen olayları atlayabilir.

171
DP=0,60 DN=0,90 DTSO=906/1010 =0,90 DP=0,60 DN=0,90 DTSO=150/200 =0,75
GERÇEK DURUM H+ H- T E S T+ 6 100 T- 4 900 TOPLAM 10 1000 GERÇEK DURUM H+ H- T E S T+ 60 100 T- 40 900 TOPLAM 1000 GERÇEK DURUM H+ H- T E S T+ 60 10 T- 40 90 TOPLAM 100 DP=0,60 DN=0,90 DTSO=906/1010 =0,90 DP=0,60 DN=0,90 DTSO=150/200 =0,75 DP=0,60 DN=0,90 DTSO=960/1100 =0,87

172
Duyarlılık ve seçicilik teste özgü, prevelanstan etkilenmeyen bir özelliktedir, ancak doğru test sonucu olasılığı bu özelliklere sahip değildir. YP ve YN oranlara eşit önem tanır, oysaki gerekmeyebilir.

173
LIKELIHOOD RATIO Olabilirlik Oranı
OLABİLİRLİK ORANI Bir tanı testinin duyarlılığını ve seçiciliğini birleştirerek kullanan performans ölçüsütüdür Pozitif Olabilirlik Oranı; Bir testin hasta kişide pozitif çıkma olasılığının, sağlam kişide pozitif çıkma olasılığına oranı LR (+) = duyarlılık / (1-seçicilik)
 = duyarlılık / (1-seçicilik)")
174
LIKELIHOOD RATIO Pozitif Olabilirlik Oranı
POO=Duyarlılık/(1-Seçicilik)=DP/YP Bir tanı testinin, her doğru pozitif sonuca karşılık kaç tane yanlış pozitif sonuç verdiğini gösterir. DP=0,80 ve DN=0,90 olan bir test için; POO=0.80/0.10 = 8 Bu test, her 8 doğru pozitif sonuca karşılık 1 yanlış pozitif sonuç verir. Dokuz pozitif sonucun 8’i doğru, biri yanlıştır.
=DP/YP. Bir tanı testinin, her doğru pozitif sonuca karşılık kaç tane yanlış pozitif sonuç verdiğini gösterir. DP=0,80 ve DN=0,90 olan bir test için; POO=0.80/0.10 = 8. Bu test, her 8 doğru pozitif sonuca karşılık 1 yanlış pozitif sonuç verir. Dokuz pozitif sonucun 8’i doğru, biri yanlıştır.")
175
LIKELIHOOD RATIO Negatif Olabilirlik Oranı
Bir testin hasta kişide negatif çıkma olasılığının, sağlam kişide negatif çıkma olasılığına oranı LR (-) = (1- duyarlılık)/seçicilik
 = (1- duyarlılık)/seçicilik.")
176
Negatif Olabilirlik Oranı
NOO=(1-Duyarlılık)/Seçicilik=YN/DN Bir tanı testinin, her yanlış negatif sonuca karşılık kaç tane doğru negatif sonuç verdiğini gösterir. DP=0,80 ve DN=0,90 olan bir test için; NOO=0.2/0.9=2/9 Bu test, her 2 yanlış negatif sonuca karşılık 9 doğru negatif sonuç verir. Onbir negatif sonucun 9’u doğru, ikisi yanlıştır. POO’nın olabildiğince büyük, NOO’nın olabildiğince küçük olması istenir.
/Seçicilik=YN/DN. Bir tanı testinin, her yanlış negatif sonuca karşılık kaç tane doğru negatif sonuç verdiğini gösterir. DP=0,80 ve DN=0,90 olan bir test için; NOO=0.2/0.9=2/9. Bu test, her 2 yanlış negatif sonuca karşılık 9 doğru negatif sonuç verir. Onbir negatif sonucun 9’u doğru, ikisi yanlıştır. POO’nın olabildiğince büyük, NOO’nın olabildiğince küçük olması istenir.")
177
Olabilirlik Oranı +LR>10 veya -LR<0.1 ise önemliliğe götürür
-LR ise orta +LR 2-5 veya -LR küçük ama bazen önemli +LR 1-2 -LR ise küçük ve çok az önemlili

178
B - KESTİRİM GÜCÜ Gerçekte araştırmacıların yanıt aradığı en önemli soru; “Tanı testi sonucu pozitif olanın, gerçek bir hasta olma olasılığı nedir? (veya Tanı testi sonucu negatif olanın gerçekten sağlam olma olasılığı nedir ?)” sorusudur. Bu kavram “KESTİRİM DEĞERİ” adını alır ve Bayes kuramı çerçevesinde çözümlenir.
 sorusudur. Bu kavram KESTİRİM DEĞERİ adını alır ve Bayes kuramı çerçevesinde çözümlenir.")
179
B - KESTİRİM GÜCÜ POZİTİF SONUCUN KESTİRİM DEĞERİ (PKD): Tanı testi hasta yargısı verdiğinde, gerçekten hasta olma olasılığıdır. 2) NEGATİF SONUCUN KESTİRİM DEĞERİ (NKD): Tanı Testi sağlam dediğinde gerçekten sağlam olma olasılığıdır. Bu oran ne kadar küçük olursa tanı testi, sağlamları o derecede iyi ayırmaktadır.
 NEGATİF SONUCUN KESTİRİM DEĞERİ (NKD): Tanı Testi sağlam dediğinde gerçekten sağlam olma olasılığıdır. Bu oran ne kadar küçük olursa tanı testi, sağlamları o derecede iyi ayırmaktadır.")
180
Klinisyenler için önemli olan soru, bir test sonucunun ne anlama geldiği sorusudur. Pozitif sonuca sahip bir kişinin hasta olması yada negatif sonuca sahip bir kişinin hastalıksız olması olasılıklarının ne olduğu önemlidir.

181
Bu amaca hizmet eden olasılıklar TEST SONRASI OLASILIKLAR olarak adlandırılır ve iki farklı test sonrası olasılık vardır. Bunlar: POZİTİF TAHMİNİ DEĞER (POSITIVE PREDICTIVE VALUE) ya da POZİTİF TEST SONUCUNUN TAHMİNİ DEĞERİ ve NEGATİF TAHMİNİ DEĞER (NEGATIVE PREDICTIVE VALUE) ya da NEGATİF TEST SONUCUNUN TAHMİNİ DEĞERİ dir.
 ya da POZİTİF TEST SONUCUNUN TAHMİNİ DEĞERİ. ve. NEGATİF TAHMİNİ DEĞER (NEGATIVE PREDICTIVE VALUE) ya da NEGATİF TEST SONUCUNUN TAHMİNİ DEĞERİ dir.")
182
Pozitif Tahmini Değer (PTD), tanı testi sonucu pozitif olan bir kişinin hasta olması olasılığını gösterir. Test istenmeden önceki hastalık olasılığına ve testin performans ölçütlerine bağlıdır.

183
Pozitif Tahmini Değer (PTD), tanı testi sonucu pozitif olan bir kişinin hasta olması olasılığını gösterir. Test istenmeden önceki hastalık olasılığına ve testin performans ölçütlerine bağlıdır. Burada Se: Testin Duyarlılığı Sp: Testin Seçiciliği Pr: Test Öncesi Hastalık Olasılığı

184
Negatif Tahmini Değer (NTD), tanı testi sonucu negatif olan bir kişinin hasta olmaması olasılığını gösterir. Test istenmeden önceki hastalık olasılığına ve testin performans ölçütlerine bağlıdır. Burada Se: Testin Duyarlılığı Sp: Testin Seçiciliği Pr: Test Öncesi Hastalık Olasılığı

185
DP=0,80 ve DN=0,90 olan örnek tanı testinin, test uygulanmadan önceki hastalık olasılığı %60 olan bir hastaya uygulandığını ve; I) Test sonucunun pozitif geldiğini düşünelim Test uygulanmadan önce, öykü ve fizik muayene bulguları ile %60 olasılıkla hasta olabileceği düşünülen kişinin, tanı testi sonucu pozitif gelmesi durumunda hasta olması olasılığı %92 dir.
 Test sonucunun pozitif geldiğini düşünelim. Test uygulanmadan önce, öykü ve fizik muayene bulguları ile %60 olasılıkla hasta olabileceği düşünülen kişinin, tanı testi sonucu pozitif gelmesi durumunda hasta olması olasılığı %92 dir.")
186
II) Test sonucunun negatif geldiğini düşünelim
Test uygulanmadan önce, öykü ve fizik muayene bulguları ile %60 olasılıkla hasta olabileceği (%40 olasılıkla hasta olmadığı) düşünülen kişinin, tanı testi sonucu negatif gelmesi durumunda hasta olmaması olasılığı %75 dir.
 düşünülen kişinin, tanı testi sonucu negatif gelmesi durumunda hasta olmaması olasılığı %75 dir.")
187
P(H+)=0,60 P(H+)=0,92 P(H-)=0,40 P(H-)=0,75
Görüldüğü gibi bu test belirsizliği büyük ölçüde ortadan kaldırmaktadır. P(H+)=0, P(H+)=0,92 P(H-)=0, P(H-)=0,75 Tanı Testi + Duy.=0,80 Seç.=0,90 Tanı Testi - Duy.=0,80 Seç.=0,90
=0,60 P(H+)=0,92. P(H-)=0,40 P(H-)=0,75. Tanı Testi + Duy.=0,80. Seç.=0,90. Tanı Testi - Duy.=0,80. Seç.=0,90.")
188
Eğer bu tanı testi daha duyarlı, daha az seçici olsaydı, örneğin;
Duy.=0,90 ; YN=0,10 Seç.=0,80 ; YP=0,20 olsaydı YP oranının %10 dan %20 ye çıkması test öncesi hastalık olasılığı aynı kaldığında, test sonrası hasta olma olasılığını %92 den %87 ye düşürmüştür. Pozitif sonuç ile belirsizlik bir miktar artmıştır.

189
ROC eğrisi yöntemi; Testin ayırt etme gücünün belirlenmesine,
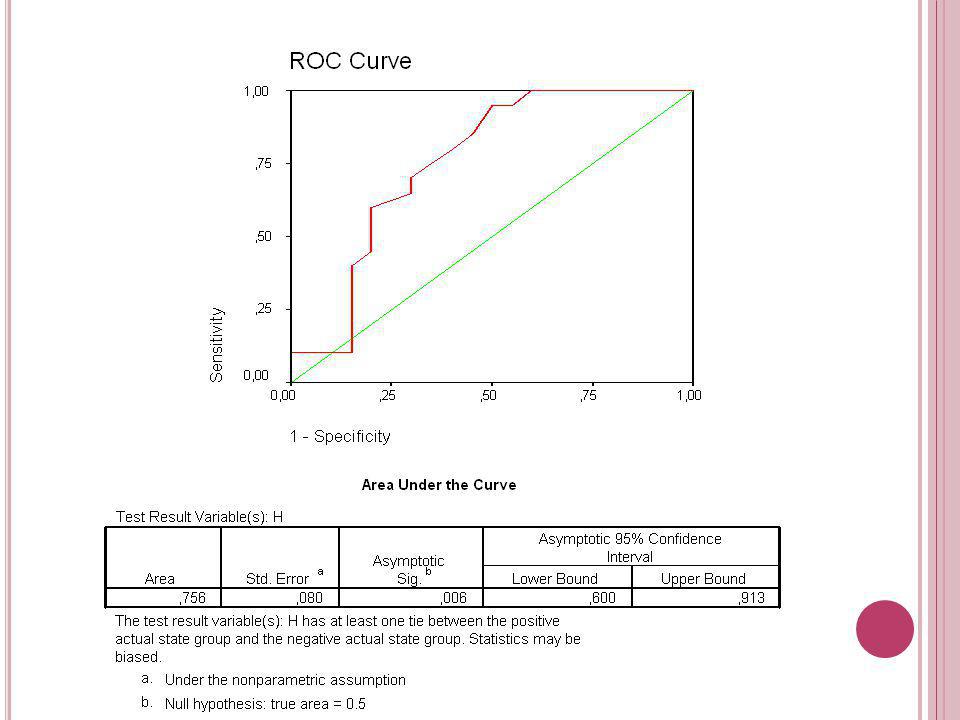
Çeşitli testlerin etkinliklerinin kıyaslanmasına, Uygun pozitiflik eşiğinin belirlenmesine, Laboratuar sonuçlarının kalitesinin izlenmesine, Uygulayıcının gelişiminin izlenmesine ve Farklı uygulayıcıların etkinliklerinin kıyaslanmasına olanak sağlar.

190
Receiver Operating Characteristic Curve
ROC EĞRİSİ Bir çift duyarlılık ve seçicilik değeri kullanmanın getirdiği dezavantajları ortadan kaldıracak bir yöntem olarak geliştirilmiştir. Testin kendi doğruluğunu (prevelanstan bağımsız olarak) tanımlaması ve testler arasında en doğru karşılaştırma yapmaya olanak sağlaması açısından sıklıkla kullanılmaktadır.
 tanımlaması ve testler arasında en doğru karşılaştırma yapmaya olanak sağlaması açısından sıklıkla kullanılmaktadır.")
191
ROC eğrisi, değişik kesim noktalarında testin duyarlılığının (y-ekseni), testin YP oranına (x-ekseni) karşı noktalanması ile elde edilir. Her kesim noktasındaki DP ve YP’e karşılık gelen noktalar birleştirilerek ROC eğrisi çizilir.

193
ROC Eğrisi Altında Kalan Alan:
Testin doğruluğunu tek bir sayısal değerle özetlemek için kullanılır. En büyük “1” değerini alabilir. Pratik olarak alabileceği en küçük değer “0.50” dir. Hastalarla sağlamlar tamamen şansa bağlı olarak (örneğin para atışı ile) ayırt edilirse bu durum ortaya çıkar
 ayırt edilirse bu durum ortaya çıkar.")
194
MB Bu örnek problem için ROC eğrisi altında kalan alan 0,83 birim2’dir. Meme kanserli bir hastanın, sağlam bir kişiye göre daha şüpheli (pozitif) test sonucuna sahip olması olasılığı 0,83’dür. B Ş M ROC eğrisi altında kalan alan bir testin hastalarla sağlamları ayırt edebilme başarısının en iyi göstergesi olarak kabul edilir.
 test sonucuna sahip olması olasılığı 0,83’dür. B. Ş. M. ROC eğrisi altında kalan alan bir testin hastalarla sağlamları ayırt edebilme başarısının en iyi göstergesi olarak kabul edilir.")
195
ROC Eğrisi Altında Kalan Alan:
ROC eğrisi altında kalan alan herzaman çok bilgilendirici olmayabilir. Kimi zaman, testin yüksek seçici (yüksek duyarlı) olması istendiğinde düşük seçicilik değerleri (düşük duyarlılık değerleri) ile değil, ROC eğrisinde yüksek seçiciliğe (yüksek duyarlılığa) karşılık gelen bölge ile ilgilenebiliriz. İki test aynı ROC eğrisi altında kalan alan değerine sahip olabilir, ancak işleyişleri farklıdır.
 olması istendiğinde düşük seçicilik değerleri (düşük duyarlılık değerleri) ile değil, ROC eğrisinde yüksek seçiciliğe (yüksek duyarlılığa) karşılık gelen bölge ile ilgilenebiliriz. İki test aynı ROC eğrisi altında kalan alan değerine sahip olabilir, ancak işleyişleri farklıdır.")
196
ROC Eğrisi Altında Kalan Alan:
Düşük yanlış pozitif oran (yüksek seçicilik) gerekli ise, B test A testine tercih edilebilir. Bu nedenle ROC eğrisinin ilgilenilen bölümünü kullanmak, böyle bir bölgeyi kullanan ölçülerle ilgilenmek daha akılcı olabilir.
 gerekli ise, B test A testine tercih edilebilir. Bu nedenle ROC eğrisinin ilgilenilen bölümünü kullanmak, böyle bir bölgeyi kullanan ölçülerle ilgilenmek daha akılcı olabilir.")
197
Özet A - ÖZGÜN ORANLAR B - KESTİRİM GÜCÜ DUYARLILIK (SENSİTİVİTY):
ÖZGÜLLÜK (SPECİFİCİTY) YANLIŞ NEGATİF ORANI: YANLIŞ POZİTİF ORANI: POZİTİF OLABİLİRLİK ORANI (L+): NEGATİF OLABİLİRLİK ORANI (L -): DOĞRULUK (ACCURACY): B - KESTİRİM GÜCÜ POZİTİF SONUCUN KESTİRİM DEĞERİ (PKD): NEGATİF SONUCUN KESTİRİM DEĞERİ (NKD):
 YANLIŞ NEGATİF ORANI: YANLIŞ POZİTİF ORANI: POZİTİF OLABİLİRLİK ORANI (L+): NEGATİF OLABİLİRLİK ORANI (L -): DOĞRULUK (ACCURACY): B - KESTİRİM GÜCÜ. POZİTİF SONUCUN KESTİRİM DEĞERİ (PKD): NEGATİF SONUCUN KESTİRİM DEĞERİ (NKD):")
198
Özet 1) DUYARLILIK (Sensitivity): Testin, gerçek hastalar içinden hastaları ayırma yeteneği. 2) ÖZGÜLLÜK (Specificity) testin, gerçek sağlamlar içinden sağlamları ayırma yeteneği. 3) YANLIŞ NEGATİF ORANI: Gerçek hastalar içinden testin hatalı olarak sağlam dediği olgulardır. 4) YANLIŞ POZİTİF ORANI: Gerçek sağlamlar içinden testin hatalı olarak hasta dediği olgulardır. 5) Pozitif olabilirlik oranı (L+): Testin, hastalığa var dediği zaman doğruyu bildirmesinin yanılmasına oranıdır. (hastalık tanısı koymanın doğruluk oranı) Bu oran ne kadar yüksek olursa, gerçek hastalar o derecede iyi ayrımlanmaktadır 6) Negatif olabilirlik oranı (L -): Sağlam tanısının doğruluk oranıdır. Bu oran ne kadar küçük olursa, gerçek sağlamlar o kadar iyi ayrımlanabilmektedir. 7) DOĞRULUK (Accuracy): Gerçekte testin hasta ve sağlam olarak toplam doğru tanı oranına “doğruluk” denir. Diğer oranlardan farklı olarak doğruluk, aynı duyarlılık- özgüllük için bile hastalık sıklığına bağlı olarak değişebilir. 8) POZİTİF KESTİRİM DEĞERİ (PKD): Tanı testi hasta yargısı verdiğinde, gerçekten hasta olma olasılığıdır. 9) NEGATİF KESTİRİM DEĞERİ (NKD): Tanı Testi sağlam dediğinde gerçekten sağlam olma olasılığıdır. Bu oran ne kadar küçük olursa tanı testi, sağlamları o derecede iyi ayırmaktadır.
 ÖZGÜLLÜK (Specificity) testin, gerçek sağlamlar içinden sağlamları ayırma yeteneği. 3) YANLIŞ NEGATİF ORANI: Gerçek hastalar içinden testin hatalı olarak sağlam dediği olgulardır. 4) YANLIŞ POZİTİF ORANI: Gerçek sağlamlar içinden testin hatalı olarak hasta dediği olgulardır. 5) Pozitif olabilirlik oranı (L+): Testin, hastalığa var dediği zaman doğruyu bildirmesinin yanılmasına oranıdır. (hastalık tanısı koymanın doğruluk oranı) Bu oran ne kadar yüksek olursa, gerçek hastalar o derecede iyi ayrımlanmaktadır. 6) Negatif olabilirlik oranı (L -): Sağlam tanısının doğruluk oranıdır. Bu oran ne kadar küçük olursa, gerçek sağlamlar o kadar iyi ayrımlanabilmektedir. 7) DOĞRULUK (Accuracy): Gerçekte testin hasta ve sağlam olarak toplam doğru tanı oranına doğruluk denir. Diğer oranlardan farklı olarak doğruluk, aynı duyarlılık- özgüllük için bile hastalık sıklığına bağlı olarak değişebilir. 8) POZİTİF KESTİRİM DEĞERİ (PKD): Tanı testi hasta yargısı verdiğinde, gerçekten hasta olma olasılığıdır. 9) NEGATİF KESTİRİM DEĞERİ (NKD): Tanı Testi sağlam dediğinde gerçekten sağlam olma olasılığıdır. Bu oran ne kadar küçük olursa tanı testi, sağlamları o derecede iyi ayırmaktadır.")
199
Çapraz tablo

200
Formüller DUYARLILIK = A / (A+C) = GP / (GP + YN)
ÖZGÜLLÜK= D / (D + B) = GN / (GN + YP) YN = (1-DUYARLILIK) = C /(A + C) = YN/ (YN + GP) YP = (1-ÖZGÜLLÜK) = B /(B+D) = YP / (YP+GN) L+ = DUYARLILIK) / (1-ÖZGÜLLÜK) = A(B+D) / B (A+C) = GP (YP+GN) / YP (GP+YN) L- = (1-DUYARLILIK) / (ÖZGÜLLÜK) = C(B+D) / D (A+C) = YN (YP+GN) / GN (GP+YN) DOĞRULUK= (A+D)/(A+B+C+D) = (GP+GN) / (GP+YP+YN+GN) PKD = P(H+/T+) = A /(A+B) = GP / (GP+YP) NKD = P(H-/T+) = D / (D+C) = GN / (GN+YN)
 = GN / (GN + YP) YN = (1-DUYARLILIK) = C /(A + C) = YN/ (YN + GP) YP = (1-ÖZGÜLLÜK) = B /(B+D) = YP / (YP+GN) L+ = DUYARLILIK) / (1-ÖZGÜLLÜK) = A(B+D) / B (A+C) = GP (YP+GN) / YP (GP+YN) L- = (1-DUYARLILIK) / (ÖZGÜLLÜK) = C(B+D) / D (A+C) = YN (YP+GN) / GN (GP+YN) DOĞRULUK= (A+D)/(A+B+C+D) = (GP+GN) / (GP+YP+YN+GN) PKD = P(H+/T+) = A /(A+B) = GP / (GP+YP) NKD = P(H-/T+) = D / (D+C) = GN / (GN+YN)")
201
Hangisi? Testin performansı ve tanı sonucunun doğruluğu, testinin özgün oranları ve hastalığın prevalansına bağlıdır. Tarama konumlarında özellikle sağlamların belirlenmesi söz konusu olduğunda testin “NKD”önem kazanır. NKD’nin büyümesi için yanlış negatiflerin oranı azalmalı yani testin duyarlılığı büyümelidir.

202
Hangisi? Buna karşılık tanıda, hastalığın varlığının doğrulanması gerekir, dolayısıyla PKD önem kazanır. Bu yanlış pozitiflerin oranı azaltılarak sağlanabilir. Uygun bir tedavisi olan ve hasta olmayanlara (YP) boşuna uygulandığında ağır sonuçlar getirmeyen hastalık tanısına yönelik testlerde DUYARLILIK YÜKSEK tutulmalıdır. Buna karşın, daha az ağır sonuçlara sahip hastalıklarda hele yanlış pozitiflerin boşuna tedavisi ağır yan etkilere sahip ise ÖZGÜLLÜK YÜKSEK tutulmalıdır.
 boşuna uygulandığında ağır sonuçlar getirmeyen hastalık tanısına yönelik testlerde DUYARLILIK YÜKSEK tutulmalıdır. Buna karşın, daha az ağır sonuçlara sahip hastalıklarda hele yanlış pozitiflerin boşuna tedavisi ağır yan etkilere sahip ise ÖZGÜLLÜK YÜKSEK tutulmalıdır.")
203
10 erkek bir cinayet davasından yargılanmayı bekliyor
Sadece üçü suçlu Jüri herkesi dinliyor Altı kişiyi suçlu buluyor Suçlu bulunanların sadece ikisi gerçek suçlu Dört kişi haksız yere hapsedilmiş durumda Katillerden biri serbest kalmış

204
Gerçek Jüri Kararı Katil Masum Suçlu Doğru hüküm ( 2 kişi) Yanlış hüküm (4 kişi) Suçsuz Yanlış beraat (1 kişi) Doğru beraat (3 kişi)
 Yanlış hüküm (4 kişi) Suçsuz Yanlış beraat (1 kişi) Doğru beraat (3 kişi) .")
205
Her 3 katilden 2’sini doğru bir biçimde belirleyebiliyor.
Sensitivite % 66 Her 7 suçsuz kişiden 3’ünü doğru şekilde aklıyor Spesifite % 42 Bir kişiyi suçlu bulmuşsa, gerçek suçlu olma olasılığı üçte birdir. PPD %33 Eğer bu jüri bir kişiyi suçsuz bulmuşsa, o kişinin suçsuz olma olasılığı ¾’tür. NPD % 75 Jüri her 10 davadan 5’ini doğru bir biçimde karara bağlıyor…………. Jürinin doğruluğu % 50

207
Teşekkürler

Benzer bir sunumlar